10.6 管线命令 (pipe)
就如同前面所说的, bash 命令执行的时候有输出的数据会出现! 那么如果这群数据必需要经过几道手续之后才能得到我们所想要的格式,应该如何来设置? 这就牵涉到管线命令的问题了 (pipe) ,管线命令使用的是“ | ”这个界定符号! 另外,管线命令与“连续下达命令”是不一样的呦! 这点下面我们会再说明。下面我们先举一个例子来说明一下简单的管线命令。
假设我们想要知道 /etc/ 下面有多少文件,那么可以利用 ls /etc 来查阅,不过, 因为 /etc 下面的文件太多,导致一口气就将屏幕塞满了~不知道前面输出的内容是啥?此时,我们可以通过 less 指令的协助,利用:
[dmtsai@study ~]$ ls -al /etc | less
如此一来,使用 ls 指令输出后的内容,就能够被 less 读取,并且利用 less 的功能,我们就能够前后翻动相关的信息了!很方便是吧?我们就来了解一下这个管线命令“ | ”的用途吧! 其实这个管线命令“ | ”仅能处理经由前面一个指令传来的正确信息,也就是 standard output 的信息,对于 stdandard error 并没有直接处理的能力。那么整体的管线命令可以使用下图表示:
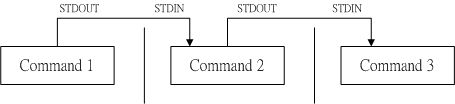 图10.6.1、管线命令的处理示意图
图10.6.1、管线命令的处理示意图
在每个管线后面接的第一个数据必定是“指令”喔!而且这个指令必须要能够接受 standard input 的数据才行,这样的指令才可以是为“管线命令”,例如 less, more, head, tail 等都是可以接受 standard input 的管线命令啦。至于例如 ls, cp, mv 等就不是管线命令了!因为 ls, cp, mv 并不会接受来自 stdin 的数据。 也就是说,管线命令主要有两个比较需要注意的地方:
- 管线命令仅会处理 standard output,对于 standard error output 会予以忽略
- 管线命令必须要能够接受来自前一个指令的数据成为 standard input 继续处理才行。

Tips 想一想,如果你硬要让 standard error 可以被管线命令所使用,那该如何处理?其实就是通过上一小节的数据流重导向即可! 让 2>&1 加入指令中~就可以让 2> 变成 1> 啰!了解了吗? ^_^
多说无益,让我们来玩一些管线命令吧!下面的咚咚对系统管理非常有帮助喔!
10.6.1 撷取命令: cut, grep
什么是撷取命令啊?说穿了,就是将一段数据经过分析后,取出我们所想要的。或者是经由分析关键字,取得我们所想要的那一行! 不过,要注意的是,一般来说,撷取讯息通常是针对“一行一行”来分析的, 并不是整篇讯息分析的喔~下面我们介绍两个很常用的讯息撷取命令:
- cut
cut 不就是“切”吗?没错啦!这个指令可以将一段讯息的某一段给他“切”出来~ 处理的讯息是以“行”为单位喔!下面我们就来谈一谈:
[dmtsai@study ~]$ cut -d'分隔字符' -f fields <==用于有特定分隔字符
[dmtsai@study ~]$ cut -c 字符区间 <==用于排列整齐的讯息
选项与参数:
-d :后面接分隔字符。与 -f 一起使用;
-f :依据 -d 的分隔字符将一段讯息分区成为数段,用 -f 取出第几段的意思;
-c :以字符 (characters) 的单位取出固定字符区间;
范例一:将 PATH 变量取出,我要找出第五个路径。
[dmtsai@study ~]$ echo ${PATH}
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/dmtsai/.local/bin:/home/dmtsai/bin
# 1 | 2 | 3 | 4 | 5 | 6 |
[dmtsai@study ~]$ echo ${PATH} | cut -d ':' -f 5
# 如同上面的数字显示,我们是以“ : ”作为分隔,因此会出现 /home/dmtsai/.local/bin
# 那么如果想要列出第 3 与第 5 呢?,就是这样:
[dmtsai@study ~]$ echo ${PATH} | cut -d ':' -f 3,5
范例二:将 export 输出的讯息,取得第 12 字符以后的所有字串
[dmtsai@study ~]$ export
declare -x HISTCONTROL="ignoredups"
declare -x HISTSIZE="1000"
declare -x HOME="/home/dmtsai"
declare -x HOSTNAME="study.centos.vbird"
.....(其他省略).....
# 注意看,每个数据都是排列整齐的输出!如果我们不想要“ declare -x ”时,就得这么做:
[dmtsai@study ~]$ export | cut -c 12-
HISTCONTROL="ignoredups"
HISTSIZE="1000"
HOME="/home/dmtsai"
HOSTNAME="study.centos.vbird"
.....(其他省略).....
# 知道怎么回事了吧?用 -c 可以处理比较具有格式的输出数据!
# 我们还可以指定某个范围的值,例如第 12-20 的字符,就是 cut -c 12-20 等等!
范例三:用 last 将显示的登陆者的信息中,仅留下使用者大名
[dmtsai@study ~]$ last
root pts/1 192.168.201.101 Sat Feb 7 12:35 still logged in
root pts/1 192.168.201.101 Fri Feb 6 12:13 - 18:46 (06:33)
root pts/1 192.168.201.254 Thu Feb 5 22:37 - 23:53 (01:16)
# last 可以输出“帐号/终端机/来源/日期时间”的数据,并且是排列整齐的
[dmtsai@study ~]$ last | cut -d ' ' -f 1
# 由输出的结果我们可以发现第一个空白分隔的字段代表帐号,所以使用如上指令:
# 但是因为 root pts/1 之间空格有好几个,并非仅有一个,所以,如果要找出
# pts/1 其实不能以 cut -d ' ' -f 1,2 喔!输出的结果会不是我们想要的。
cut 主要的用途在于将“同一行里面的数据进行分解!”最常使用在分析一些数据或文字数据的时候! 这是因为有时候我们会以某些字符当作分区的参数,然后来将数据加以切割,以取得我们所需要的数据。 鸟哥也很常使用这个功能呢!尤其是在分析 log 文件的时候!不过,cut 在处理多空格相连的数据时,可能会比较吃力一点,所以某些时刻可能会使用下一章的 awk 来取代的!
- grep
刚刚的 cut 是将一行讯息当中,取出某部分我们想要的,而 grep 则是分析一行讯息, 若当中有我们所需要的信息,就将该行拿出来~简单的语法是这样的:
[dmtsai@study ~]$ grep [-acinv] [--color=auto] '搜寻字串' filename
选项与参数:
-a :将 binary 文件以 text 文件的方式搜寻数据
-c :计算找到 '搜寻字串' 的次数
-i :忽略大小写的不同,所以大小写视为相同
-n :顺便输出行号
-v :反向选择,亦即显示出没有 '搜寻字串' 内容的那一行!
--color=auto :可以将找到的关键字部分加上颜色的显示喔!
范例一:将 last 当中,有出现 root 的那一行就取出来;
[dmtsai@study ~]$ last | grep 'root'
范例二:与范例一相反,只要没有 root 的就取出!
[dmtsai@study ~]$ last | grep -v 'root'
范例三:在 last 的输出讯息中,只要有 root 就取出,并且仅取第一栏
[dmtsai@study ~]$ last | grep 'root' |cut -d ' ' -f1
# 在取出 root 之后,利用上个指令 cut 的处理,就能够仅取得第一栏啰!
范例四:取出 /etc/man_db.conf 内含 MANPATH 的那几行
[dmtsai@study ~]$ grep --color=auto 'MANPATH' /etc/man_db.conf
....(前面省略)....
MANPATH_MAP /usr/games /usr/share/man
MANPATH_MAP /opt/bin /opt/man
MANPATH_MAP /opt/sbin /opt/man
# 神奇的是,如果加上 --color=auto 的选项,找到的关键字部分会用特殊颜色显示喔!
grep 是个很棒的指令喔!他支持的语法实在是太多了~用在正则表达式里头, 能够处理的数据实在是多的很~不过,我们这里先不谈正则表达式~下一章再来说明~ 您先了解一下, grep 可以解析一行文字,取得关键字,若该行有存在关键字,就会整行列出来!另外, CentOS 7 当中,默认的 grep 已经主动加上 --color=auto 在 alias 内了喔!
10.6.2 排序命令: sort, wc, uniq
很多时候,我们都会去计算一次数据里头的相同型态的数据总数,举例来说, 使用 last 可以查得系统上面有登陆主机者的身份。那么我可以针对每个使用者查出他们的总登陆次数吗? 此时就得要排序与计算之类的指令来辅助了!下面我们介绍几个好用的排序与统计指令喔!
- sort
sort 是很有趣的指令,他可以帮我们进行排序,而且可以依据不同的数据型态来排序喔! 例如数字与文字的排序就不一样。此外,排序的字符与语系的编码有关,因此, 如果您需要排序时,建议使用 LANG=C 来让语系统一,数据排序比较好一些。
[dmtsai@study ~]$ sort [-fbMnrtuk] [file or stdin]
选项与参数:
-f :忽略大小写的差异,例如 A 与 a 视为编码相同;
-b :忽略最前面的空白字符部分;
-M :以月份的名字来排序,例如 JAN, DEC 等等的排序方法;
-n :使用“纯数字”进行排序(默认是以文字体态来排序的);
-r :反向排序;
-u :就是 uniq ,相同的数据中,仅出现一行代表;
-t :分隔符号,默认是用 [tab] 键来分隔;
-k :以那个区间 (field) 来进行排序的意思
范例一:个人帐号都记录在 /etc/passwd 下,请将帐号进行排序。
[dmtsai@study ~]$ cat /etc/passwd | sort
abrt:x:173:173::/etc/abrt:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
alex:x:1001:1002::/home/alex:/bin/bash
# 鸟哥省略很多的输出~由上面的数据看起来, sort 是默认“以第一个”数据来排序,
# 而且默认是以“文字”型态来排序的喔!所以由 a 开始排到最后啰!
范例二:/etc/passwd 内容是以 : 来分隔的,我想以第三栏来排序,该如何?
[dmtsai@study ~]$ cat /etc/passwd | sort -t ':' -k 3
root:x:0:0:root:/root:/bin/bash
dmtsai:x:1000:1000:dmtsai:/home/dmtsai:/bin/bash
alex:x:1001:1002::/home/alex:/bin/bash
arod:x:1002:1003::/home/arod:/bin/bash
# 看到特殊字体的输出部分了吧?怎么会这样排列啊?呵呵!没错啦~
# 如果是以文字体态来排序的话,原本就会是这样,想要使用数字排序:
# cat /etc/passwd | sort -t ':' -k 3 -n
# 这样才行啊!用那个 -n 来告知 sort 以数字来排序啊!
范例三:利用 last ,将输出的数据仅取帐号,并加以排序
[dmtsai@study ~]$ last | cut -d ' ' -f1 | sort
sort 同样是很常用的指令呢!因为我们常常需要比较一些信息啦! 举个上面的第二个例子来说好了!今天假设你有很多的帐号,而且你想要知道最大的使用者 ID 目前到哪一号了!呵呵!使用 sort 一下子就可以知道答案咯!当然其使用还不止此啦!有空的话不妨玩一玩!
- uniq
如果我排序完成了,想要将重复的数据仅列出一个显示,可以怎么做呢?
[dmtsai@study ~]$ uniq [-ic]
选项与参数:
-i :忽略大小写字符的不同;
-c :进行计数
范例一:使用 last 将帐号列出,仅取出帐号栏,进行排序后仅取出一位;
[dmtsai@study ~]$ last | cut -d ' ' -f1 | sort | uniq
范例二:承上题,如果我还想要知道每个人的登陆总次数呢?
[dmtsai@study ~]$ last | cut -d ' ' -f1 | sort | uniq -c
1
6 (unknown
47 dmtsai
4 reboot
7 root
1 wtmp
# 从上面的结果可以发现 reboot 有 4 次, root 登陆则有 7 次!大部分是以 dmtsai 来操作!
# wtmp 与第一行的空白都是 last 的默认字符,那两个可以忽略的!
这个指令用来将“重复的行删除掉只显示一个”,举个例子来说, 你要知道这个月份登陆你主机的使用者有谁,而不在乎他的登陆次数,那么就使用上面的范例, (1)先将所有的数据列出;(2)再将人名独立出来;(3)经过排序;(4)只显示一个! 由于这个指令是在将重复的东西减少,所以当然需要“配合排序过的文件”来处理啰!
- wc
如果我想要知道 /etc/man_db.conf 这个文件里面有多少字?多少行?多少字符的话, 可以怎么做呢?其实可以利用 wc 这个指令来达成喔!他可以帮我们计算输出的讯息的整体数据!
[dmtsai@study ~]$ wc [-lwm]
选项与参数:
-l :仅列出行;
-w :仅列出多少字(英文单字);
-m :多少字符;
范例一:那个 /etc/man_db.conf 里面到底有多少相关字、行、字符数?
[dmtsai@study ~]$ cat /etc/man_db.conf | wc
131 723 5171
# 输出的三个数字中,分别代表: “行、字数、字符数”
范例二:我知道使用 last 可以输出登陆者,但是 last 最后两行并非帐号内容,那么请问,
我该如何以一行指令串取得登陆系统的总人次?
[dmtsai@study ~]$ last | grep [a-zA-Z] | grep -v 'wtmp' | grep -v 'reboot' | \
> grep -v 'unknown' |wc -l
# 由于 last 会输出空白行, wtmp, unknown, reboot 等无关帐号登陆的信息,因此,我利用
# grep 取出非空白行,以及去除上述关键字那几行,再计算行数,就能够了解啰!
wc 也可以当作指令?这可不是上洗手间的 WC 呢!这是相当有用的计算文件内容的一个工具组喔!举个例子来说, 当你要知道目前你的帐号文件中有多少个帐号时,就使用这个方法:“ cat /etc/passwd | wc -l ”啦!因为 /etc/passwd 里头一行代表一个使用者呀! 所以知道行数就晓得有多少的帐号在里头了!而如果要计算一个文件里头有多少个字符时,就使用 wc -m 这个选项吧!
10.6.3 双向重导向: tee
想个简单的东西,我们由前一节知道 > 会将数据流整个传送给文件或设备,因此我们除非去读取该文件或设备, 否则就无法继续利用这个数据流。万一我想要将这个数据流的处理过程中将某段讯息存下来,应该怎么做? 利用 tee 就可以啰~我们可以这样简单的看一下:
 图10.6.2、tee 的工作流程示意图
图10.6.2、tee 的工作流程示意图
tee 会同时将数据流分送到文件去与屏幕 (screen);而输出到屏幕的,其实就是 stdout ,那就可以让下个指令继续处理喔!
[dmtsai@study ~]$ tee [-a] file
选项与参数:
-a :以累加 (append) 的方式,将数据加入 file 当中!
[dmtsai@study ~]$ last | tee last.list | cut -d " " -f1
# 这个范例可以让我们将 last 的输出存一份到 last.list 文件中;
[dmtsai@study ~]$ ls -l /home | tee ~/homefile | more
# 这个范例则是将 ls 的数据存一份到 ~/homefile ,同时屏幕也有输出讯息!
[dmtsai@study ~]$ ls -l / | tee -a ~/homefile | more
# 要注意! tee 后接的文件会被覆盖,若加上 -a 这个选项则能将讯息累加。
tee 可以让 standard output 转存一份到文件内并将同样的数据继续送到屏幕去处理! 这样除了可以让我们同时分析一份数据并记录下来之外,还可以作为处理一份数据的中间暂存盘记录之用! tee 这家伙在很多选择/填充的认证考试中很容易考呢!
10.6.4 字符转换命令: tr, col, join, paste, expand
我们在 vim 程序编辑器当中,提到过 DOS 断行字符与 Unix 断行字符的不同,并且可以使用 dos2unix 与 unix2dos 来完成转换。好了,那么思考一下,是否还有其他常用的字符替代? 举例来说,要将大写改成小写,或者是将数据中的 [tab] 按键转成空白键?还有,如何将两篇讯息整合成一篇? 下面我们就来介绍一下这些字符转换命令在管线当中的使用方法:
- tr
tr 可以用来删除一段讯息当中的文字,或者是进行文字讯息的替换!
[dmtsai@study ~]$ tr [-ds] SET1 ...
选项与参数:
-d :删除讯息当中的 SET1 这个字串;
-s :取代掉重复的字符!
范例一:将 last 输出的讯息中,所有的小写变成大写字符:
[dmtsai@study ~]$ last | tr '[a-z]' '[A-Z]'
# 事实上,没有加上单引号也是可以执行的,如:“ last | tr [a-z] [A-Z] ”
范例二:将 /etc/passwd 输出的讯息中,将冒号 (:) 删除
[dmtsai@study ~]$ cat /etc/passwd | tr -d ':'
范例三:将 /etc/passwd 转存成 dos 断行到 /root/passwd 中,再将 ^M 符号删除
[dmtsai@study ~]$ cp /etc/passwd ~/passwd && unix2dos ~/passwd
[dmtsai@study ~]$ file /etc/passwd ~/passwd
/etc/passwd: ASCII text
/home/dmtsai/passwd: ASCII text, with CRLF line terminators <==就是 DOS 断行
[dmtsai@study ~]$ cat ~/passwd | tr -d '\r' > ~/passwd.linux
# 那个 \r 指的是 DOS 的断行字符,关于更多的字符,请参考 man tr
[dmtsai@study ~]$ ll /etc/passwd ~/passwd*
-rw-r--r--. 1 root root 2092 Jun 17 00:20 /etc/passwd
-rw-r--r--. 1 dmtsai dmtsai 2133 Jul 9 22:13 /home/dmtsai/passwd
-rw-rw-r--. 1 dmtsai dmtsai 2092 Jul 9 22:13 /home/dmtsai/passwd.linux
# 处理过后,发现文件大小与原本的 /etc/passwd 就一致了!
其实这个指令也可以写在“正则表达式”里头!因为他也是由正则表达式的方式来取代数据的! 以上面的例子来说,使用 [] 可以设置一串字呢!也常常用来取代文件中的怪异符号! 例如上面第三个例子当中,可以去除 DOS 文件留下来的 ^M 这个断行的符号!这东西相当的有用!相信处理 Linux & Windows 系统中的人们最麻烦的一件事就是这个事情啦!亦即是 DOS 下面会自动的在每行行尾加入 ^M 这个断行符号!这个时候除了以前讲过的 dos2unix 之外,我们也可以使用这个 tr 来将 ^M 去除! ^M 可以使用 \r 来代替之!
- col
[dmtsai@study ~]$ col [-xb]
选项与参数:
-x :将 tab 键转换成对等的空白键
范例一:利用 cat -A 显示出所有特殊按键,最后以 col 将 [tab] 转成空白
[dmtsai@study ~]$ cat -A /etc/man_db.conf <==此时会看到很多 ^I 的符号,那就是 tab
[dmtsai@study ~]$ cat /etc/man_db.conf | col -x | cat -A | more
# 嘿嘿!如此一来, [tab] 按键会被取代成为空白键,输出就美观多了!
虽然 col 有他特殊的用途,不过,很多时候,他可以用来简单的处理将 [tab] 按键取代成为空白键! 例如上面的例子当中,如果使用 cat -A 则 [tab] 会以 ^I 来表示。 但经过 col -x 的处理,则会将 [tab] 取代成为对等的空白键!
- join
join 看字面上的意义 (加入/参加) 就可以知道,他是在处理两个文件之间的数据, 而且,主要是在处理“两个文件当中,有 "相同数据" 的那一行,才将他加在一起”的意思。我们利用下面的简单例子来说明:
[dmtsai@study ~]$ join [-ti12] file1 file2
选项与参数:
-t :join 默认以空白字符分隔数据,并且比对“第一个字段”的数据,
如果两个文件相同,则将两笔数据联成一行,且第一个字段放在第一个!
-i :忽略大小写的差异;
-1 :这个是数字的 1 ,代表“第一个文件要用那个字段来分析”的意思;
-2 :代表“第二个文件要用那个字段来分析”的意思。
范例一:用 root 的身份,将 /etc/passwd 与 /etc/shadow 相关数据整合成一栏
[root@study ~]# head -n 3 /etc/passwd /etc/shadow
==> /etc/passwd <==
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
==> /etc/shadow <==
root:$6$wtbCCce/PxMeE5wm$KE2IfSJr...:16559:0:99999:7:::
bin:*:16372:0:99999:7:::
daemon:*:16372:0:99999:7:::
# 由输出的数据可以发现这两个文件的最左边字段都是相同帐号!且以 : 分隔
[root@study ~]# join -t ':' /etc/passwd /etc/shadow | head -n 3
root:x:0:0:root:/root:/bin/bash:$6$wtbCCce/PxMeE5wm$KE2IfSJr...:16559:0:99999:7:::
bin:x:1:1:bin:/bin:/sbin/nologin:*:16372:0:99999:7:::
daemon:x:2:2:daemon:/sbin:/sbin/nologin:*:16372:0:99999:7:::
# 通过上面这个动作,我们可以将两个文件第一字段相同者整合成一列!
# 第二个文件的相同字段并不会显示(因为已经在最左边的字段出现了啊!)
范例二:我们知道 /etc/passwd 第四个字段是 GID ,那个 GID 记录在
/etc/group 当中的第三个字段,请问如何将两个文件整合?
[root@study ~]# head -n 3 /etc/passwd /etc/group
==> /etc/passwd <==
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
==> /etc/group <==
root:x:0:
bin:x:1:
daemon:x:2:
# 从上面可以看到,确实有相同的部分喔!赶紧来整合一下!
[root@study ~]# join -t ':' -1 4 /etc/passwd -2 3 /etc/group | head -n 3
0:root:x:0:root:/root:/bin/bash:root:x:
1:bin:x:1:bin:/bin:/sbin/nologin:bin:x:
2:daemon:x:2:daemon:/sbin:/sbin/nologin:daemon:x:
# 同样的,相同的字段部分被移动到最前面了!所以第二个文件的内容就没再显示。
# 请读者们配合上述显示两个文件的实际内容来比对!
这个 join 在处理两个相关的数据文件时,就真的是很有帮助的啦! 例如上面的案例当中,我的 /etc/passwd, /etc/shadow, /etc/group 都是有相关性的, 其中 /etc/passwd, /etc/shadow 以帐号为相关性,至于 /etc/passwd, /etc/group 则以所谓的 GID (帐号的数字定义) 来作为他的相关性。根据这个相关性, 我们可以将有关系的数据放置在一起!这在处理数据可是相当有帮助的! 但是上面的例子有点难,希望您可以静下心好好的看一看原因喔!
此外,需要特别注意的是,在使用 join 之前,你所需要处理的文件应该要事先经过排序 (sort) 处理! 否则有些比对的项目会被略过呢!特别注意了!
- paste
这个 paste 就要比 join 简单多了!相对于 join 必须要比对两个文件的数据相关性, paste 就直接“将两行贴在一起,且中间以 [tab] 键隔开”而已!简单的使用方法:
[dmtsai@study ~]$ paste [-d] file1 file2
选项与参数:
-d :后面可以接分隔字符。默认是以 [tab] 来分隔的!
- :如果 file 部分写成 - ,表示来自 standard input 的数据的意思。
范例一:用 root 身份,将 /etc/passwd 与 /etc/shadow 同一行贴在一起
[root@study ~]# paste /etc/passwd /etc/shadow
root:x:0:0:root:/root:/bin/bash root:$6$wtbCCce/PxMeE5wm$KE2IfSJr...:16559:0:99999:7:::
bin:x:1:1:bin:/bin:/sbin/nologin bin:*:16372:0:99999:7:::
daemon:x:2:2:daemon:/sbin:/sbin/nologin daemon:*:16372:0:99999:7:::
# 注意喔!同一行中间是以 [tab] 按键隔开的!
范例二:先将 /etc/group 读出(用 cat),然后与范例一贴上一起!且仅取出前三行
[root@study ~]# cat /etc/group|paste /etc/passwd /etc/shadow -|head -n 3
# 这个例子的重点在那个 - 的使用!那玩意儿常常代表 stdin 喔!
- expand
这玩意儿就是在将 [tab] 按键转成空白键啦~可以这样玩:
[dmtsai@study ~]$ expand [-t] file
选项与参数:
-t :后面可以接数字。一般来说,一个 tab 按键可以用 8 个空白键取代。
我们也可以自行定义一个 [tab] 按键代表多少个字符呢!
范例一:将 /etc/man_db.conf 内行首为 MANPATH 的字样就取出;仅取前三行;
[dmtsai@study ~]$ grep '^MANPATH' /etc/man_db.conf | head -n 3
MANPATH_MAP /bin /usr/share/man
MANPATH_MAP /usr/bin /usr/share/man
MANPATH_MAP /sbin /usr/share/man
# 行首的代表标志为 ^ ,这个我们留待下节介绍!先有概念即可!
范例二:承上,如果我想要将所有的符号都列出来?(用 cat)
[dmtsai@study ~]$ grep '^MANPATH' /etc/man_db.conf | head -n 3 |cat -A
MANPATH_MAP^I/bin^I^I^I/usr/share/man$
MANPATH_MAP^I/usr/bin^I^I/usr/share/man$
MANPATH_MAP^I/sbin^I^I^I/usr/share/man$
# 发现差别了吗?没错~ [tab] 按键可以被 cat -A 显示成为 ^I
范例三:承上,我将 [tab] 按键设置成 6 个字符的话?
[dmtsai@study ~]$ grep '^MANPATH' /etc/man_db.conf | head -n 3 | expand -t 6 - | cat -A
MANPATH_MAP /bin /usr/share/man$
MANPATH_MAP /usr/bin /usr/share/man$
MANPATH_MAP /sbin /usr/share/man$
123456123456123456123456123456123456123456123456...
# 仔细看一下上面的数字说明,因为我是以 6 个字符来代表一个 [tab] 的长度,所以,
# MAN... 到 /usr 之间会隔 12 (两个 [tab]) 个字符喔!如果 tab 改成 9 的话,
# 情况就又不同了!这里也不好理解~您可以多设置几个数字来查阅就晓得!
expand 也是挺好玩的~他会自动将 [tab] 转成空白键~所以,以上面的例子来说, 使用 cat -A 就会查不到 ^I 的字符啰~此外,因为 [tab] 最大的功能就是格式排列整齐! 我们转成空白键后,这个空白键也会依据我们自己的定义来增加大小~ 所以,并不是一个 ^I 就会换成 8 个空白喔!这个地方要特别注意的哩! 此外,您也可以参考一下 unexpand 这个将空白转成 [tab] 的指令功能啊! ^_^
10.6.5 分区命令: split
如果你有文件太大,导致一些携带式设备无法复制的问题,嘿嘿!找 split 就对了! 他可以帮你将一个大文件,依据文件大小或行数来分区,就可以将大文件分区成为小文件了! 快速又有效啊!真不错~
[dmtsai@study ~]$ split [-bl] file PREFIX
选项与参数:
-b :后面可接欲分区成的文件大小,可加单位,例如 b, k, m 等;
-l :以行数来进行分区。
PREFIX :代表前置字符的意思,可作为分区文件的前导文字。
范例一:我的 /etc/services 有六百多K,若想要分成 300K 一个文件时?
[dmtsai@study ~]$ cd /tmp; split -b 300k /etc/services services
[dmtsai@study tmp]$ ll -k services*
-rw-rw-r--. 1 dmtsai dmtsai 307200 Jul 9 22:52 servicesaa
-rw-rw-r--. 1 dmtsai dmtsai 307200 Jul 9 22:52 servicesab
-rw-rw-r--. 1 dmtsai dmtsai 55893 Jul 9 22:52 servicesac
# 那个文件名可以随意取的啦!我们只要写上前导文字,小文件就会以
# xxxaa, xxxab, xxxac 等方式来创建小文件的!
范例二:如何将上面的三个小文件合成一个文件,文件名为 servicesback
[dmtsai@study tmp]$ cat services* >> servicesback
# 很简单吧?就用数据流重导向就好啦!简单!
范例三:使用 ls -al / 输出的信息中,每十行记录成一个文件
[dmtsai@study tmp]$ ls -al / | split -l 10 - lsroot
[dmtsai@study tmp]$ wc -l lsroot*
10 lsrootaa
10 lsrootab
4 lsrootac
24 total
# 重点在那个 - 啦!一般来说,如果需要 stdout/stdin 时,但偏偏又没有文件,
# 有的只是 - 时,那么那个 - 就会被当成 stdin 或 stdout ~
在 Windows 操作系统下,你要将文件分区需要如何作?伤脑筋吧!在 Linux 下面就简单的多了!你要将文件分区的话,那么就使用 -b size 来将一个分区的文件限制其大小,如果是行数的话,那么就使用 -l line 来分区!好用的很!如此一来,你就可以轻易的将你的文件分区成某些软件能够支持的最大容量 (例如 gmail 单一信件 25MB 之类的!),方便你 copy 啰!
10.6.6 参数代换: xargs
xargs 是在做什么的呢?就以字面上的意义来看, x 是加减乘除的乘号,args 则是 arguments (参数) 的意思,所以说,这个玩意儿就是在产生某个指令的参数的意思! xargs 可以读入 stdin 的数据,并且以空白字符或断行字符作为分辨,将 stdin 的数据分隔成为 arguments 。 因为是以空白字符作为分隔,所以,如果有一些文件名或者是其他意义的名词内含有空白字符的时候, xargs 可能就会误判了~他的用法其实也还满简单的!就来看一看先!
[dmtsai@study ~]$ xargs [-0epn] command
选项与参数:
-0 :如果输入的 stdin 含有特殊字符,例如 `, \, 空白键等等字符时,这个 -0 参数
可以将他还原成一般字符。这个参数可以用于特殊状态喔!
-e :这个是 EOF (end of file) 的意思。后面可以接一个字串,当 xargs 分析到这个字串时,
就会停止继续工作!
-p :在执行每个指令的 argument 时,都会询问使用者的意思;
-n :后面接次数,每次 command 指令执行时,要使用几个参数的意思。
当 xargs 后面没有接任何的指令时,默认是以 echo 来进行输出喔!
范例一:将 /etc/passwd 内的第一栏取出,仅取三行,使用 id 这个指令将每个帐号内容秀出来
[dmtsai@study ~]$ id root
uid=0(root) gid=0(root) groups=0(root) # 这个 id 指令可以查询使用者的 UID/GID 等信息
[dmtsai@study ~]$ id $(cut -d ':' -f 1 /etc/passwd | head -n 3)
# 虽然使用 $(cmd) 可以预先取得参数,但可惜的是, id 这个指令“仅”能接受一个参数而已!
# 所以上述的这个指令执行会出现错误!根本不会显示用户的 ID 啊!
[dmtsai@study ~]$ cut -d ':' -f 1 /etc/passwd | head -n 3 | id
uid=1000(dmtsai) gid=1000(dmtsai) groups=1000(dmtsai),10(wheel) # 我不是要查自己啊!
# 因为 id 并不是管线命令,因此在上面这个指令执行后,前面的东西通通不见!只会执行 id!
[dmtsai@study ~]$ cut -d ':' -f 1 /etc/passwd | head -n 3 | xargs id
# 依旧会出现错误!这是因为 xargs 一口气将全部的数据通通丢给 id 处理~但 id 就接受 1 个啊最多!
[dmtsai@study ~]$ cut -d ':' -f 1 /etc/passwd | head -n 3 | xargs -n 1 id
uid=0(root) gid=0(root) groups=0(root)
uid=1(bin) gid=1(bin) groups=1(bin)
uid=2(daemon) gid=2(daemon) groups=2(daemon)
# 通过 -n 来处理,一次给予一个参数,因此上述的结果就 OK 正常的显示啰!
范例二:同上,但是每次执行 id 时,都要询问使用者是否动作?
[dmtsai@study ~]$ cut -d ':' -f 1 /etc/passwd | head -n 3 | xargs -p -n 1 id
id root ?...y
uid=0(root) gid=0(root) groups=0(root)
id bin ?...y
.....(下面省略).....
# 呵呵!这个 -p 的选项可以让使用者的使用过程中,被询问到每个指令是否执行!
范例三:将所有的 /etc/passwd 内的帐号都以 id 查阅,但查到 sync 就结束指令串
[dmtsai@study ~]$ cut -d ':' -f 1 /etc/passwd | xargs -e'sync' -n 1 id
# 仔细与上面的案例做比较。也同时注意,那个 -e'sync' 是连在一起的,中间没有空白键。
# 上个例子当中,第六个参数是 sync 啊,那么我们下达 -e'sync' 后,则分析到 sync 这个字串时,
# 后面的其他 stdin 的内容就会被 xargs 舍弃掉了!
其实,在 man xargs 里面就有三四个小范例,您可以自行参考一下内容。 此外, xargs 真的是很好用的一个玩意儿!您真的需要好好的参详参详!会使用 xargs 的原因是, 很多指令其实并不支持管线命令,因此我们可以通过 xargs 来提供该指令引用 standard input 之用!举例来说,我们使用如下的范例来说明:
范例四:找出 /usr/sbin 下面具有特殊权限的文件名,并使用 ls -l 列出详细属性
[dmtsai@study ~]$ find /usr/sbin -perm /7000 | xargs ls -l
-rwx--s--x. 1 root lock 11208 Jun 10 2014 /usr/sbin/lockdev
-rwsr-xr-x. 1 root root 113400 Mar 6 12:17 /usr/sbin/mount.nfs
-rwxr-sr-x. 1 root root 11208 Mar 6 11:05 /usr/sbin/netreport
.....(下面省略).....
# 聪明的读者应该会想到使用“ ls -l $(find /usr/sbin -perm /7000) ”来处理这个范例!
# 都 OK!能解决问题的方法,就是好方法!
10.6.7 关于减号 - 的用途
管线命令在 bash 的连续的处理程序中是相当重要的!另外,在 log file 的分析当中也是相当重要的一环, 所以请特别留意!另外,在管线命令当中,常常会使用到前一个指令的 stdout 作为这次的 stdin , 某些指令需要用到文件名称 (例如 tar) 来进行处理时,该 stdin 与 stdout 可以利用减号 "-" 来替代, 举例来说:
[root@study ~]# mkdir /tmp/homeback
[root@study ~]# tar -cvf - /home | tar -xvf - -C /tmp/homeback
上面这个例子是说:“我将 /home 里面的文件给他打包,但打包的数据不是纪录到文件,而是传送到 stdout; 经过管线后,将 tar -cvf - /home 传送给后面的 tar -xvf - ”。后面的这个 - 则是取用前一个指令的 stdout, 因此,我们就不需要使用 filename 了!这是很常见的例子喔!注意注意!