| 3.3. Notepad++的多种编码支持 | ||
|---|---|---|
 |
第 3 章 Notepad++的功能详解 | 
|
| 3.3. Notepad++的多种编码支持 | ||
|---|---|---|
|
|
第 3 章 Notepad++的功能详解 |
|
在对什么字符编码,以及常见的一些字符编码,比如GBK等,有个最基本的了解之后,我们再来看看Notepad++在字符编码方面,有哪些功能:
对于想要知道当前文件所用的字符编码类型,可以如下操作:
选择 格式(M),然后就可以看到当前字符编码类型了:
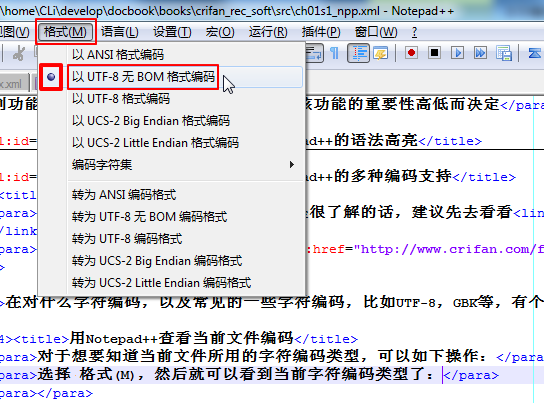 |
可以看到,当前xml文件所用字符编码类型为"以 UTF-8 无 BOM 格式编码"。
![[提示]](images/tip.png) |
提示 |
|---|---|
| 关于UTF-8的BOM,不了解的可参考[9] |
需要提及的一些是,一般我们中文和英文,最常用的几个字符编码,大概有:
对应的编码,截图如下:
 |
当你打开某个文件时,可能会遇到一些乱码。
此时,如果知道当前文本本身是用的是何种编码,则可在Notepad++中选择对应编码打开,就可以正确显示文件内容了。
例 3.1. 在Notepad++中使用ISO-8859-1编码打开VirtualBox的Manual的HTML源码
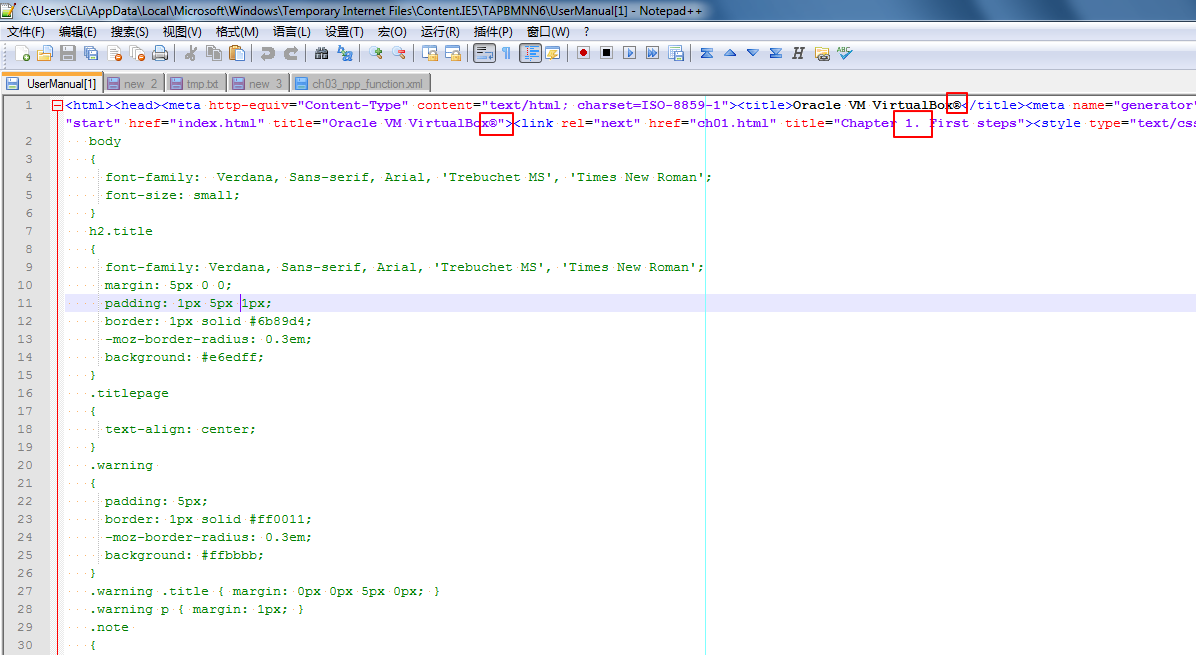
比如,在打开用户手册(UserManual)的HTML源码的时候,默认是用ANSI编码打开的,所以会有乱码:
 |
|
提示 |
|---|---|
对于如何用Notepad++打开该HTML并高亮显示,可参考第 3.9 节 “Notepad++的默认HTML查看器” |
此时,注意到该HTML源码已经通过charset=ISO-8859-1标明了使用的编码是ISO-8859-1了,所以,此时可以去改为对应的ISO-8859-1编码:
 |
就可以看到对应的乱码的字符,都可以正常显示了:
 |
由此,就可以实现了,在Notepad++中,使用正确的编码打开相应的文件,解决了乱码显示问题。
如上所述,当HTML源码时,可以通过charset去得知文件编码。
但是,很多时候,我们去打开一个文件时,
可能会遇到乱码,但是由于未必立刻就已知其文件编码是什么
所以,只能去猜测其编码是什么,然后再切换到对应的编码类型,去查看内容是否可以正常显示。
例 3.2. 出现乱码,猜测出是西欧编码,切换到ISO 8859-1而消除乱码
比如遇到一个例子:
打开文件时,出现是乱码:
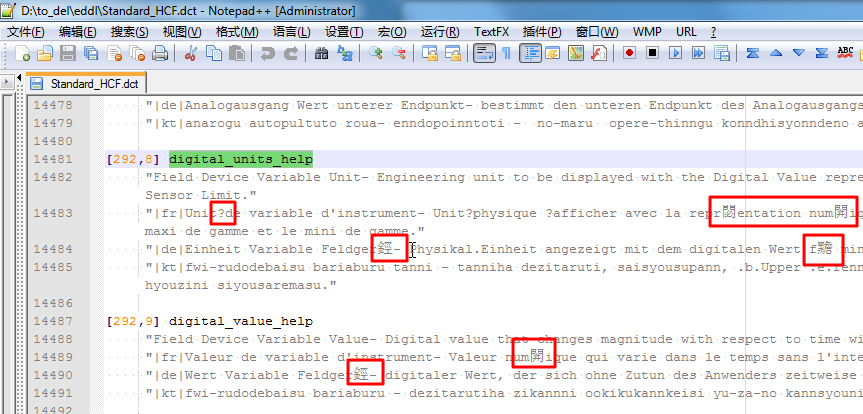 |
看起来,就像是西欧类的字符,所以,去切换到对应的ISO 8859-1编码:
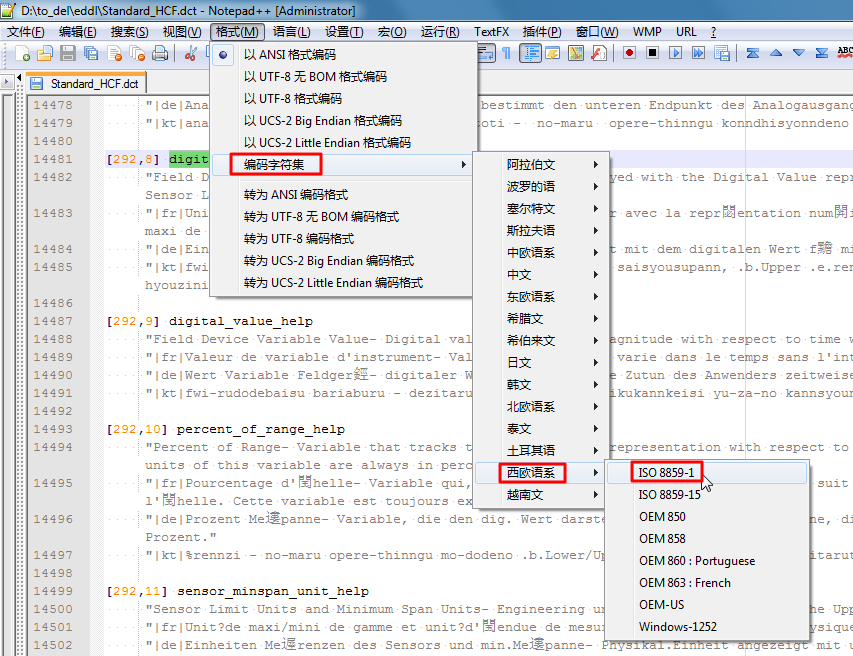 |
然后真的就消除了乱码,可以正常显示出对应的一些特殊的西欧字符了:
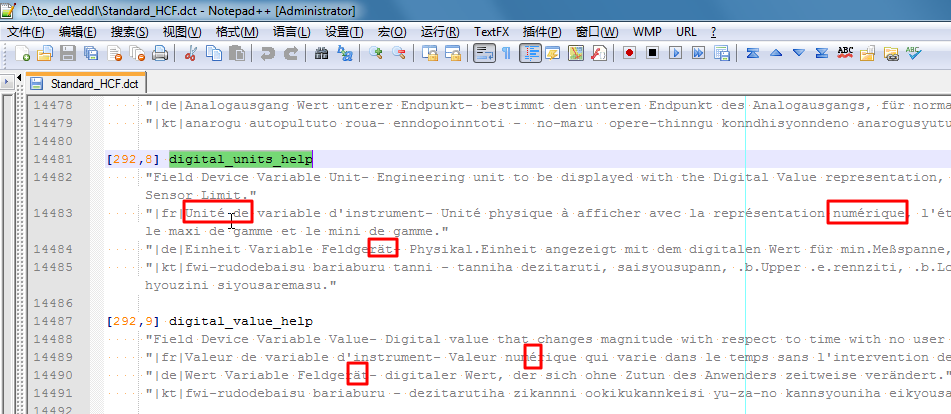 |
此处,很明显,由于对于编码稍微熟悉,所以一次就猜对了编码,而使得快速消除了乱码。
如果,你对于编码不是很熟悉,则可以多去尝试不同的编码,
最后,肯定也还是可以切换到正确的编码,可以正常显示字符的。
而随着对于字符编码的了解越来越深入,则自然会越加熟悉的,越容易一次或几次就猜对文件的正确的编码的。
很多时候,我们需要在不同字符编码之间,进行相互转换。
或者由于某些需要,要建立对应的编码的文件。
比如,写Python代码的时候,常需要文件本身的编码就是UTF-8的,
此时,就可以用Notepad++的字符编码转换方面的功能了。
比如,此处将本地一个UTF-8的xml文件:
 |
其中,中文字符所对应的16进制的如下:
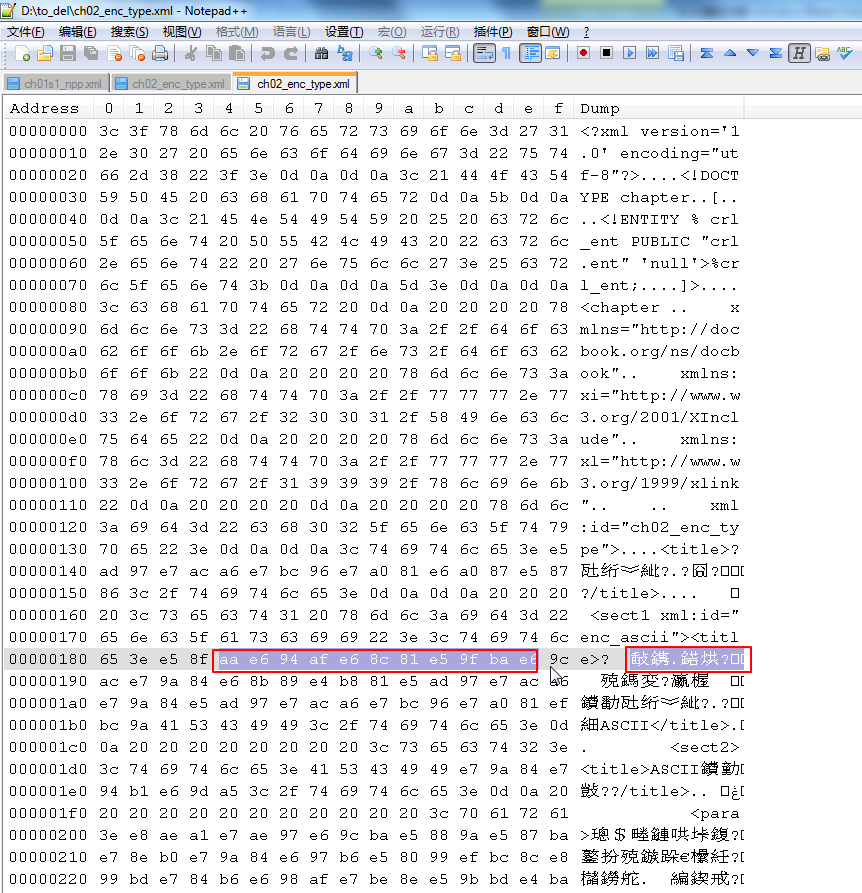 |
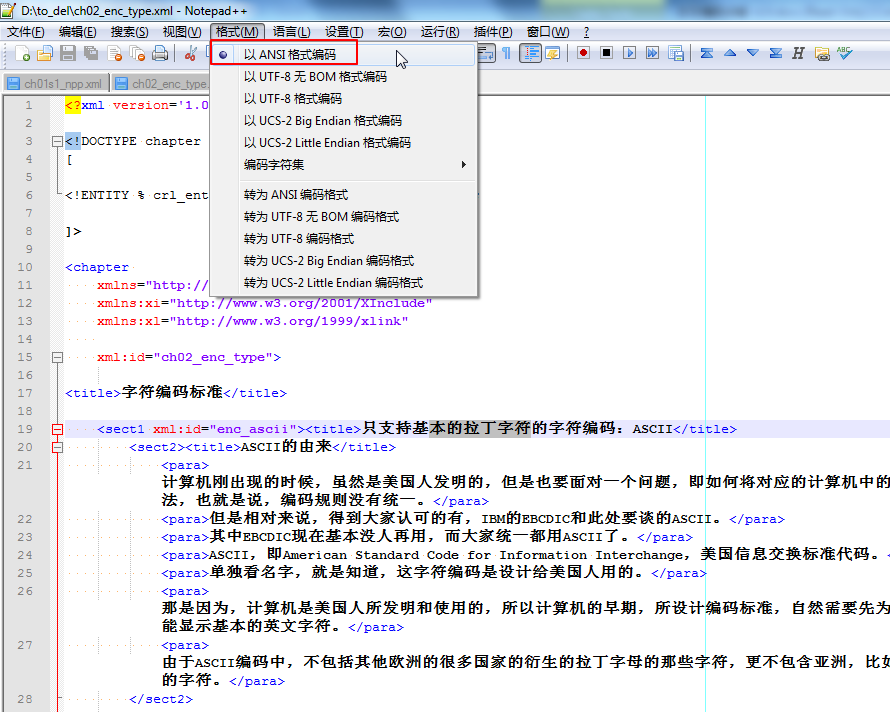
然后点击“转为 ANSI 编码格式”:
 |
即可转为ANSI编码了,此时文件已被修改,所以先保存一下该文件,然后再查看编码,就变为ANSI编码了:
 |
此时再去查看对应的中文字符所对应的16进制的值,就变了:
 |
而此处的ANSI编码,可以简单的理解为“本地”编码,而此处是本地编码是中文的GBK,所以此处ANSI即为GBK中文编码。
相应地,可以根据自己需要,在多个不同的字符编码之间互相转换。
当我们在Notepad++中新建一个文件时,可以通过第 3.3.1 节 “用Notepad++查看当前文件编码”看到新建的文件所使用的字符编码:
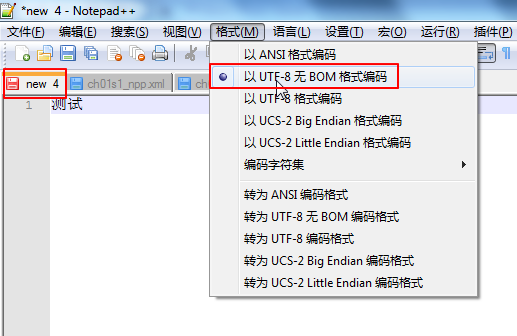 |
此处为UTF-8。
而想要改变新建文件的默认所用字符编码,可以通过:
设置(T) ⇒ 首选项...
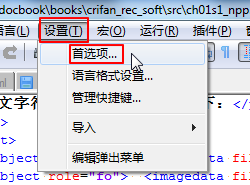 |
新建,中的“编码”:
 |
然后设置为自己所需要的编码格式。
![[注意]](images/note.png) |
Notepad++的bug:有时候执行编码转换会导致内容丢失 |
|---|---|
|
我遇到过好多次了,在执行代码转换的时候,结果是当前Notepad++打开页面变成空白了,即内容瞬间丢失了,按Ctrl+Z,也无法撤销此操作。 如果不是有备份文件的话,则就会导致文件内容丢失。 如果是很重要的文件的话,文件内容丢失,损失还是很严重的。 尽管Notepad++此编码转换导致文件内容丢失的bug,出现的概率很小,但是也还是建议,对于重要文件的编码转换,转换之前,先备份一下。 |
|
|
 |
|
| 3.2. Notepad++的语法高亮 |  |
3.4. Notepad++的正则表达式替换和替换 |