FreeBSD 开发手册
The FreeBSD Documentation Project
FreeBSD 中文计划
版权 © 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010 The FreeBSD Documentation Project
版权 © 2005, 2006 FreeBSD 中文计划
欢迎您阅读《FreeBSD开发手册》。 这本手册还在不断由许多人继续书写。 许多章节还是空白,有的章节亟待更新。 如果您对这个项目感兴趣并愿意有所贡献,请发信给 FreeBSD 文档计划邮件列表。
本文档的最新英文原始版本可从 FreeBSD Web 站点 获得, 由 FreeBSD 中文计划 维护的最新译本可以在 FreeBSD 中文计划 快照 Web 站点 和 FreeBSD 中文计划 文档快照 处获得, 这一译本会不断向主站同步。 此外, 您也可以从 FreeBSD FTP 服务器 或众多的 镜像站点 得到这份文档的各种其他格式以及压缩形式的版本。
重要: 本文中许可证的非官方中文翻译仅供参考, 不作为判定任何责任的依据。如与英文原文有出入,则以英文原文为准。
在满足下列许可条件的前提下, 允许再分发或以源代码 (SGML DocBook) 或 “编译” (SGML, HTML, PDF, PostScript, RTF 等) 的经过修改或未修改的形式:
-
再分发源代码 (SGML DocBook) 必须不加修改的保留上述版权告示、 本条件清单和下述弃权书作为该文件的最先若干行。
-
再分发编译的形式 (转换为其它DTD、 PDF、 PostScript、 RTF 或其它形式), 必须将上述版权告示、本条件清单和下述弃权书复制到与分发品一同提供的文件, 以及其它材料中。
重要: 本文档由 FREEBSD DOCUMENTATION PROJECT “按现状条件” 提供, 并在此明示不提供任何明示或暗示的保障, 包括但不限于对商业适销性、 对特定目的的适用性的暗示保障。 任何情况下, FREEBSD DOCUMENTATION PROJECT 均不对任何直接、 间接、 偶然、 特殊、 惩罚性的, 或必然的损失 (包括但不限于替代商品或服务的采购、 使用、 数据或利益的损失或营业中断) 负责, 无论是如何导致的并以任何有责任逻辑的, 无论是否是在本文档使用以外以任何方式产生的契约、 严格责任或是民事侵权行为(包括疏忽或其它)中的, 即使已被告知发生该损失的可能性。
Redistribution and use in source (SGML DocBook) and 'compiled' forms (SGML, HTML, PDF, PostScript, RTF and so forth) with or without modification, are permitted provided that the following conditions are met:
-
Redistributions of source code (SGML DocBook) must retain the above copyright notice, this list of conditions and the following disclaimer as the first lines of this file unmodified.
-
Redistributions in compiled form (transformed to other DTDs, converted to PDF, PostScript, RTF and other formats) must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
重要: THIS DOCUMENTATION IS PROVIDED BY THE FREEBSD DOCUMENTATION PROJECT "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE FREEBSD DOCUMENTATION PROJECT BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS DOCUMENTATION, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
FreeBSD 是 FreeBSD基金会的注册商标
Apple, AirPort, FireWire, Mac, Macintosh, Mac OS, Quicktime, 以及 TrueType 是 Apple Computer, Inc. 在美国以及其他国家的注册商标。
IBM、 AIX、 EtherJet、 Netfinity、 OS/2、 PowerPC、 PS/2、 S/390 以及 ThinkPad 是国际商用机器公司在美国和其他国家的注册商标或商标。
IEEE, POSIX, 和 802 是 Institute of Electrical and Electronics Engineers, Inc. 在美国的注册商标。
Intel, Celeron, EtherExpress, i386, i486, Itanium, Pentium, 和 Xeon 是 Intel Corporation 及其分支机构在美国和其他国家的商标或注册商标。
Linux 是 Linus Torvalds 的注册商标。
Microsoft, IntelliMouse, MS-DOS, Outlook, Windows, Windows Media, 和 Windows NT 是 Microsoft Corporation 在美国和/或其他国家的商标或注册商标。
Motif, OSF/1, 和 UNIX 是 The Open Group 在美国和其他国家的注册商标; IT DialTone 和 The Open Group 是其商标。
Sun、 Sun Microsystems、 Java、 Java Virtual Machine、 JavaServer Pages、 JDK、 JRE、 JSP、 JVM、 Netra、 OpenJDK、 Solaris、 StarOffice、 Sun Blade、 Sun Enterprise、 Sun Fire、 SunOS、 Ultra 以及 VirtualBox 是 Sun Microsystems, Inc. 在美国和其他国家的商标或注册商标。
许多制造商和经销商使用一些称为商标的图案或文字设计来彰显自己的产品。 本文档中出现的, 为 FreeBSD Project 所知晓的商标,后面将以 '™' 或 '®' 符号来标注。
- 目录
- 第I部分. 基础
-
- 第1章 介绍
-
- 1.1 在 FreeBSD 上进行开发
- 1.2 BSD 理念
- 1.3 指导性架构设计原则
- 1.4 /usr/src的层次结构
- 第2章 编程工具
- 第3章 安全的编程
- 第4章 本地化与国际化 - L10N 和 I18N
- 第5章 源代码树指南和维护发展策略
-
- 5.1 Makefile 中的 MAINTAINER
- 5.2 第三方软件
- 5.3 妨碍性的 (Encumbered) 文件
- 5.4 共享库
- 第6章 回归与性能测试
-
- 6.1. 微性能测试列表
- 第II部分. 进程间通信
- 第III部分. 内核
-
- 第9章 联编并安装 FreeBSD 内核
-
- 9.1 以 “传统” 方式联编内核
- 9.2 以 “新” 方式联编内核
- 第10章 调试内核
-
- 10.1 如何将内核的崩溃转存数据保存成文件
- 10.2 使用 kgdb 调试内核的崩溃转存
- 10.3 使用 DDD 调试崩溃转存文件
- 10.4 使用 DDB 进行在线内核调试
- 10.5 使用远程 GDB 进行联机内核调试
- 10.6 如何调试控制台驱动
- 10.7 调试死锁
- 10.8 用于调试的内核选项术语表
- 第IV部分. 系统结构
- 第V部分. 附录
- 索引
- 范例清单
- 例2-1. 一个 .emacs 配置文件的例子
第I部分. 基础
- 目录
- 第1章 介绍
- 第2章 编程工具
- 第3章 安全的编程
- 第4章 本地化与国际化 - L10N 和 I18N
- 第5章 源代码树指南和维护发展策略
- 第6章 回归与性能测试
第1章 介绍
供稿:Murray Stokely 和 Jeroen Ruigrok van der Werven. 翻译:李 鑫.1.1 在 FreeBSD 上进行开发
欢迎您的到来。 现在您已经安装好操作系统, 并准备开始编程了。 但是, 从哪里开始呢? FreeBSD 提供了一些什么工具? 它能够为我, 一个程序员提供什么呢?
这些都是本章准备回答的问题。 当然, 与所有其他职业类似, 人们对程序设计的熟练程度总是存在差异的。 对有些人而言, 它只是一种爱好; 而对另一些人而言, 这则是他们的职业。 这一章中的内容主要是针对初学程序设计的人而撰写; 当然, 对于那些不熟悉 FreeBSD 平台的程序员来说, 它也十分有用。
1.3 指导性架构设计原则
下面的指导性设计原则描述了我们的设计理念
-
只要某一功能的缺失不会导致无法完成某个实际的应用程序, 就不新增该功能。
-
决定系统不做成什么样子, 与决定将它做成什么样子同样重要。 不去满足所有的需要, 而是让系统具备可扩展性, 使其能够向上兼容。
-
尽可能抽象代码中的通用部分, 除非没有可以用来抽象的实例。
-
如果没有完全理解一个问题, 最好干脆不提供任何解决方案。
-
如果能用 10% 的工作完成 90% 的工作, 则选择较简单的解决方案。
-
尽可能隔离复杂性。
-
提供机制而非策略。 具体而言, 将用户界面策略交由客户去选定。
摘自 Scheifler & Gettys: "X Window System"
1.4 /usr/src的层次结构
FreeBSD 的完整源代码都可以从我们公开的代码库中获取。 源代码通常会安装到 /usr/src 目录中, 它包括了下面这些目录:
| 目录 | 说明 |
|---|---|
| bin/ | 在 /bin 中的文件的源代码 |
| cddl/ | 采用 Common Development and Distribution License 的工具 |
| contrib/ | 由其他开发组织维护的源代码 |
| crypto/ | 与密码学有关的源代码 |
| etc/ | 在 /etc 中的文件的源代码 |
| games/ | 在 /usr/games 中的文件的源代码 |
| gnu/ | 采用 GNU Public License 授权的工具 |
| include/ | 在 /usr/include 中的文件的源代码 |
| kerberos5/ | 第 5 版 Kerberos 的源代码 |
| lib/ | 在 /usr/lib 中的文件的源代码 |
| libexec/ | 在 /usr/libexec 中的文件的源代码 |
| release/ | 用于制作 FreeBSD 发行版本的文件 |
| rescue/ | 建造系统时 /rescue中的工具 |
| sbin/ | 在 /sbin 中的文件的源代码 |
| secure/ | FreeSec 的源代码 |
| share/ | 在 /usr/share 中的文件的源代码 |
| sys/ | 内核的源代码文件 |
| tools/ | 用于维护和自动测试 FreeBSD 的工具 |
| usr.bin/ | 在 /usr/bin 中的文件的源代码 |
| usr.sbin/ | 在 /usr/sbin 中的文件的源代码 |
第2章 编程工具
供稿:James Raynard 和 Murray Stokely. 翻译:Jokhva.2.1 概述
这一章介绍了 FreeBSD 提供的一些编程工具,很多这些工具在其他版本的 UNIX 中都能使用。这里我们不会尝试描述任何编程细节。大 多数章节假设您以前没有或只有很少的编程知识,但我们希望程序员也能从中受益。
2.2 介绍
FreeBSD 提供了一个非常优秀的开发环境。 它的基本系统中自带了 C 和 C++ 编译器以及汇编器, 以及包括 sed 和 awk 等在内的很多经典 UNIX 工具。 如果还不够, Ports 套件中还有更多可用的编译器和解释器。 在下一节, 程序设计入门 中, 列出了一些可用的语言。 FreeBSD 与多种标准兼容, 比如 POSIX® 和 ANSI C, 当然还有它自己的 BSD 传统。 因此, 我们在 FreeBSD 平台上写的应用不加修改或稍加修改就能在很多平台上运行。
如果你从未在 UNIX 平台上写过程序,所有这些强大之处看起来会让人炫目。 这篇文档的目的就是帮助你迅速上手,而不许要深入更多高级论题。我们的目的就是让 这篇文档给你提供足够的基础知识来理解我们的文档。
这篇文档不要求你有编程知识,或者你只有很少的编程知识。当然,我们假定你 会使用 UNIX 并且愿意来学。
2.3 编程初步
程序就是一系列指令的集合,这些指令能驱使计算机去做不同的事情。有时候计 算机执行的一个指令取决于它所执行的前一个指令。本章将介绍两种主要的给出指令, 也叫 “命令”,的方式。一种方式是使用 解释器 ,另一种方式是使用 编译器。人类语言对 于计算机来说语义模糊太难于理解,因此计算机命令都用为了特定目的设计的的一种或 其他种计算机语言写的。
2.3.1 解释器
使用解释器的计算机语言就像一个环境。解释器给出提示符后,你输入一个命 令,解释器就会执行这个命令。对于更复杂的程序,可以把命令写入一个文件然后 让解释器装入这个文件再执行其中的命令。如果有错误发生,许多解释器会进入一个 调试环境让你来追踪问题。
这种方式的优点就是可以马上看见命令的执行结果,并且迅速的改正错误。如 果你想和别人分享自己的程序,最大的坏处就显现出来了。别人需要和你一样的解释 器,或者你必须把解释器给他们,而且他们还要知道怎么使用这个解释器。用户也不 希望在按错一个键的情况下就被扔到调试环境中。从程序执行效率来看,解释器会 使用很多内存,而且通常情况下生成的代码也不如编译器生成的有效率。
我觉得,如果你从未编过程序,最好从解释类语言开始。Lisp,Smalltalk, Perl 和 Basic 语言就提供了这样的环境。UNIX 中的 shell (sh, csh) 自身就是一个解释器。实际情 况中,很多人都在他们自己的机器上写 shell “scripts” 来做很多 “维护”工作。的确,UNIX 的哲学中有一部分就是提供很多小工具, 并使用 shell scripts 把这些工具组合起来去做有用的工作。
2.3.2 FreeBSD 提供的解释器
在 FreeBSD Ports Collection 中,有一个列表列出了提供的解释器。同时还简 单讨论了一些更受欢迎的解释类语言。
从 Ports Collection 中如何取得并安装应用程序的教程可以从手册的 Ports section 中找到。
- BASIC
-
Beginner's All-purpose Symbollic Instruction Code 的缩写。20世 纪50年代被开发出来给大学生学习编程。在20世纪80年代生产的个人电脑中包 含了这种语言。BASIC 语言是很多程序员学习的第一个 编程语言。同时,它也是 Visual Basic 的基础。
Bywater 的 Basic 解释器能在 Ports Collection 中的 lang/bwbasic 找到。Phil Cockroft 的 Basic 解释器 (以前叫 Rabbit Basic) 在 lang/pbasic 中。
- Lisp
-
20世纪50年代开发的一种语言,作为当时那些“基于数字 ”的语言的补充。Lisp不是基于数字的,而是基于列表;实际上这个语 言的名字就是 “List Processing”的缩写。在 AI (Artificial Intelligence) 圈子中非常受欢迎。
Lisp 是一种非常强大而复杂的语言。但也可能变得异常庞大而臃肿。
在 FreeBSD 中的 Ports Collection 里面有各种可以在 UNIX 系统上运 行的 Lisp 实现。GNU Common Lisp 在 lang/gcl 里可以找到。Bruno Haible 和 Michael Stoll 的 CLISP 在 lang/clisp 中可以找到。而像包含一个可以高 度优化代码的编译器的 CMUCL,或者像比较简单的 Lisp 的实现的 SLisp 则 用几百行 C 代码实现了大部分 Common Lisp 的功能。两个语言分别在 lang/cmucl 和 lang/slisp 中可以找到。
- Perl
-
对于系统管理员来说非常受欢迎的脚本语言;同时也经常被用来写万维 网服务器的 CGI 脚本。
Perl 在 Ports Collection 中的 lang/perl5.8 可以找到,适合所有 FreeBSD 版本。 而且在 4.X 版本中是作为基本系统的 /usr/bin/perl 来安装的。
- Scheme
-
Lisp 的一个变种。比 Common Lisp 更加紧凑而清晰。在大学里面相当 流行因为足够简单。往往当作第一门语言教给大学生,而且在研究领域也有一 定程度的吸引力。
Scheme 在 Ports Collection 中的 lang/elk 可以找到 Elk Scheme 解释器。 lang/mit-scheme 中的是 MIT 的 Scheme 解释器。在 lang/scm 中是 SCM Scheme 解释器。
- Icon
-
Icon 是一种高级语言,在很多方面适合处理字符和结构。FreeBSD 中的 Icon 版本在 lang/icon 中可以找到。
- Logo
-
Logo 是一种容易学习的语言,并且在许多课程里面都作为一个介绍性 的编程语言存在。如果给小孩子上编程课程,Logo 是一个非常棒的开始。因 为,即使对小孩子来说,要用 Logo 画图形也是很容易的事情。
FreeBSD 中的 Logo 最新版本可以在 lang/logo 中找到。
- Python
-
Python 是种面向对象的解释类语言。拥护的人都说 Python 是开始学 习编程的最佳语言。因为相对来说比较容易起步,而且与那些流行的能开发庞大而复 杂的解释类语言来比(Perl 和 Tcl 在这个方面很流行)一点也不差。
最新版本的 Python 可以在 Ports Collection 的 lang/python 中找到。
- Ruby
-
Ruby 是一个解释类语言,并且是纯面向对象的。因为其语法容易理解 而变化多端并且适合开发以及维护庞大而复杂的程序而广泛流行。
Ruby 可以在 Ports Collection 中的 lang/ruby18 中找到。
- Tcl 和 Tk
-
Tcl 是一个嵌入式的解释类语言,能够被移植到很多平台上面。因此变 得非常流行。它既可以快速地写出小的应用程序,也可以(和 Tk 一起使用, 一种图形工具)写出功能繁多的程序。
FreeBSD 中不同版本的 Tcl 都在 ports 里面。最新版本,Tcl 8.5,可以 在 lang/tcl85 中找到。
2.3.3 编译器
编译器则非常不同。首先,代码可以使用编辑器写到一个或多个文件里面。然 后再使用编译器来编译代码,看这些代码是否能被接受。如果编译不能通过,咬紧牙 关您再打开编辑器重新修改吧;如果编译通过,并且编译器给了你一个程序。您可以 在命令行下执行或者到调试环境中执行以便查看代码有没有被正确执行。 [1]
很明显,这种方式并不如解释器直接。但却可以让你做很多解释类语言无法做 的困难的甚至无法完成的工作。例如直接与操作系统交互──或者,你甚至可以 写自己的操作系统。如果你要写非常有效率的代码,编译器也很有用。编译器可以花 一些时间来优化代码,而解释器是无法完成的。另外,分享你写的编译类程序比解释 类语言要直接得多。只要把编译好的程序给别人就行,当然我们假定别人和你都有同 一类操作系统。
编译类语言包括 Pascal,C 和 C++。C 和 C++ 很严格,适合那些有更多经验 的程序员;而 Pascal,从另一方面来说,被设计成为一个教学语言,适合初学者。 FreeBSD 在基本系统中没有提供 Pascal。但是在 Ports 套件中提供了 Free Pascal Compiler, 可以从 lang/fpc 安装它。
如果你使用不同的程序来写编译类语言,编辑-编译-运行-调试 这个循环会变 得很烦人。很多商业编译器开发了 Integrated Development Environments (缩写为 IDE)。FreeBSD 在基本系统中没有包含 IDE,但是在 devel/kdevelop 提供了一个例子。你也可 以使用 Emacs 当作 IDE。把 Emacs 当作 IDE 在 第 2.7 节 中有讨 论。
2.4 用 cc 编译
这一章我们只讨论 GNU 的 C 和 C++ 编译器,因为在 FreeBSD 的基本系统中就 包含了。直接运行 cc 或 gcc 就可以。而 用解释器写程序的细节对于不同的解释器都很不相同,通常可以在特定的解释器文档或 者在线帮助中找到。
一旦你写完你的杰作,下一步就是把你的杰作转换成可以在 FreeBSD 上运行(希 望可以!)的东西。通常这包含几个步骤,不同的步骤由不同的程序来完成。
-
预处理你的源代码,去掉注释,以及其他技巧性的工作就像在 C 中展开宏。
-
检查代码的语法看你是否遵守了这个语言的规则。如果没有,编译器会给出 警告。
-
把源代码转换为汇编语言 ── 和机器代码很相似, 但是在一定情况下我们仍然可以理解。 [2]
-
把汇编语言转换为机器语言──是的,我们在说位元和字节,就是1和0。
-
检查你是否准确地使用了函数和全局变量类似的东西。例如,如果你调用了 一个不存在的函数,编译器就会给出警告。
-
如果你是从多个源代码文件编译,就要学会如何把这些文件组合到一起。
-
把产生出来的东西用系统的运行装载器装入内存并运行。
-
最后,把可执行文件写入文件系统。
编译 这个词的意思通常指 1 到 4 步──其他的 步骤叫做 连接。有时侯第一步叫做 预处理 。第三和第四步叫做 汇编 。
幸运的是,几乎所有这些细节都是隐藏的,因为 cc 只是 一个前端。它根据正确的参数调用程序来处理代码。只要输入
% cc foobar.c
就会把 foobar.c 通过以上的步骤编译出来。如果你有 多个文件要编译,只要输入
% cc foo.c bar.c
注意,语法检查就是──纯粹的检查语法。而不会检测你可能犯的任何逻辑 错误。比如无限循环,或者是你想用一元排序却使用了冒泡排序。 [3]
cc 有很多选项,在帮助手册中都可以找到。这里列出了一 些最重要的选项,并且有例子。
-o filename-
输出的文件名。如果你不使用这个选项,cc为产生 出一个叫 a.out 的执行文件。 [4]
-c-
仅仅编译文件,不会连接。如果你只想检查你写的测试程序的语法的话, 这个选项非常有用。或者你会使用 Makefile。
这会产生一个 目标文件 (不可执行) 叫做 foobar.o。这个文件可以和其他的目标文件连接在一起 构成一个可执行文件。
-g-
产生一个可调试的可执行文件。编译器会在可执行文件中植入一些信息, 这些信息能够把源文件中的行数和被调用的函数联系起来。在你一步一步调试程 序的时候,调试器能够使用这些信息来显示源代码。这是 非常 有用的;缺点就是被植入的信息让程序变得更大。通常情况下,开 发一个程序的时候我们经常使用
-g,但是我们在编译一个 “release 版本” 的程序的时候,如果程序工作得让人满意了,我 们就不使用-g编译。这会产生一个可调试版本的程序。 [5]
-O-
产生一个优化版本的可执行文件。编译器会使用一些聪明的技巧产生出比 普通编译产生的文件执行更快的可执行文件。可以在
-O加 上数字来使用更高级的优化。但是这样做经常会暴露出编译器的优化器中的一些 错误。例如,2.1.0 版本的 FreeBSD 中的 cc 在某些情况 下使用了-O2的话,会产生出错误的代码。优化通常只在编译一个 release 版本的时候才被打开。
这会产生一个优化版本的 foobar。
下面的三个参数会迫使 cc 检查你的代码是否符合一些国 际标准,经常被我们叫做 ANSI 标准,虽然严格的来说它是一个 ISO 标准。
-Wall-
打开所有 cc 的作者认为值得注意的警告。不要只 看这个选项的名字,它并没有打开所有 cc 能够注意到的 所有警告。
-ansi-
关闭大多数,但并不是所有,cc 提供的非 ANSI C 特性。不要只看选项的名字,它并不严格保 证你的代码会兼容标准。
-pedantic-
关闭 所有 cc 的非 ANSI C 特性。
没有这些选项,cc 能允许你按照标准使用一些非标准的扩 展。有一些扩展非常有用,但不能与其他编译器兼容──实际上,这个标准的主要 目的之一就是允许我们写出可以在任何系统上的由任何编译器编译的代码。这就叫做 可移植代码
通常来说,你应该让你的代码尽可能的可以移植。否则你就不得不完全重写你的 代码以便能够在其他地方运行之──而且谁知道几年后你是否还会用它?
这会在检查 foobar.c对标准的兼容性以后产生一个 foobar 可执行文件。
-llibrary-
在连接的时候指定一个函数库。
最常见的情况就是当你编译一个使用了一些 C 中的数学函数的时候。不 像大多数其他的平台,这些函数都不在 C 的标准库里面。你必须告诉编译器加 上这些库。
这个规则就是,如果库的名字叫做 libsomething.a,你就必 须给 cc 这样的选项
-lsomething。例如,数学库 叫做 libm.a,因此你给 cc 的选 项就是-lm。一般情况下,我们要把这个选项放到命令行的 最后。这个会把数学函数库连接到 foobar 里面。
如果你要编译 C++ 代码,你需要
-lg++,或者-lstdc++如果你使用的是 FreeBSD 2.2 或者更高版本,来 连接 C++ 库。或者,你可以运行 c++ 而不是 cc 来编译 C++ 代码。在 FreeBSD 上, c++ 也可以通过运行 g++ 来唤醒。% cc -o foobar foobar.cc -lg++ 对于 FreeBSD 2.1.6 或者更低的版本 % cc -o foobar foobar.cc -lstdc++ 对 FreeBSD 2.2 或者更高的版本 % c++ -o foobar foobar.cc两种情况都会从 C++ 源文件 foobar.cc产生一个 可执行文件 foobar。注意,在 UNIX 系统中,C++ 源 文件的传统后缀是 .C,.cxx 或 者 .cc,而不是 MS-DOS® 类型的 .cpp (这个后缀已经被用到了其他的地方)。 gcc 根据这个约定来确定应该使用何种类型的编译器来编 译源文件。但是,这个限制不再起作用了,因此现在你可以自由的使用 .cpp 这个后缀来命名你的 C++ 源文件!
2.4.1 常见 cc 问题
- 2.4.1.1. 我尝试写一个程序,其中使用了
sin()这个函 数。但是我却得到了如下的错误。这个错误是什么意思? - 2.4.1.2. 好的,我写了一个简单的程序,练习使用
-lm。也 就是计算 2.1 的 6 次方。 - 2.4.1.3. 那么我怎么才能改正这个错误?
- 2.4.1.4. 我编译了一个文件叫 foobar.c 但是我没有找 到叫 foobar 的执行文件。这个文件到哪里去了?
- 2.4.1.5. 好的,我有一个执行文件 foobar,我用命令 ls 可以看见,但是在命令行我输入 foobar 却得到提示说没有这个文件。为什么找不到呢?
- 2.4.1.6. 我的可执行文件叫做 test,但是我运行之后却 什么也没发生。到底怎么了?
- 2.4.1.7. 我编译了一个程序,开始看起来运行得不错。但是后来调试了,说什么 “core dumped”。这个是什么意思?
- 2.4.1.8. 挺不错,但现在我该怎么办呢?
- 2.4.1.9. 我的程序把 core dump 以后,说有一个什么 “segmentation fault”。这是什么?
- 2.4.1.10. 有时候当我得到一个 core dump,提示说 “bus error”。我的 UNIX 教材里面说这意味这硬件错误,但是计算 机看起来运行很正常。这是真的吗?
- 2.4.1.11. 如果我可以让 core dump 在需要的时候产生,那就真的很不错。我能 这样做吗,或者我得等直到发生一个错误?
2.4.1.2.
好的,我写了一个简单的程序,练习使用 -lm。也 就是计算 2.1 的
6 次方。
然后我编译:
就像你说的我应该做的那样。但是我在运行的时候却有如下提示:
这个 不 是正确的答案!到底怎么了?
当编译器看见你调用了一个函数,它会检查是否已经有了一个相配合的 原始类型 (prototype),如果没有,编译器会假定函数的返回值是 整 数,恰恰不是你的程序想要的结果。
core dump 这个名字可以追溯到 UNIX 的早 期历史,当时的计算机都使用线圈内存储存数据。通常情况下,如果一个程序 在一定的情况下执行失败了,系统就会把线圈内存的内容写到磁盘上的一个文 件中,这个文件就叫 core。通过研究这个文件,程序 员就可以发现问题之所在。
使用 gdb 分析这个 core 文件 (见 第 2.6 节)。
基本上是你的程序尝试对内存进行某种非法的操作导致的。UNIX 在 设计上要保护操作系统本身和其他程序不受非法程序的干扰。
通常的原因有如下这些:
-
尝试赋值给一个
NULL指针,例如char *foo = NULL; strcpy(foo, "bang!"); -
使用一个未被初始化的指针,例如
char *foo; strcpy(foo, "bang!");在某种情况下,指针所包含的值会指向内存中某个区域,这个区域 对你的程序是不可操作的。在你的程序造成任何破坏之前,内核会终止程 序。如果你运气不好,这个指针会指向你自己的程序在内存中的某个区域, 从而破坏自身的某些数据结构,导致程序奇怪地崩溃。
-
数组越界,例如
int bar[20]; bar[27] = 6; -
尝试在只读内存中储存数据,例如
char *foo = "My string"; strcpy(foo, "bang!");UNIX 编译器经常把像 "My string" 这样 的字符串放到只读内存中。
-
错误的使用函数
malloc()和free(),例如char bar[80]; free(bar);or
char *foo = malloc(27); free(foo); free(foo);
这些错误并不总会导致你的程序崩溃,但这些都是坏的习惯。有些系统 和编译器比其他的系统和编译器有更多的容错性,这就是为什么一些程序在一 个系统上可以运行很好,而在另一个系统上却会崩溃。
不是真的,很幸运不是(除非你真的遇见了一个硬件问题...)。这 通常是用另一种方式说你尝试读写一块无权读写的内存。
2.5 Make
2.5.1 什么是 make?
当你写一个简单的程序,只有一到两个源文件的时候,输入
% cc file1.c file2.c
就没什么问题,但如果有很多源文件就会很烦人──编译的时间也会很长。
一个方法就是使用目标文件,只在源文件有改变的情况下才重新编译源文件。 因此你可以这样做:
% cc file1.o file2.o ... file37.c ...
上次编译后,file37.c 发生了改变,但其他文 件没有。这样做可以让编译过程快很多,但是也不能解决累人的输入问题。
或者我们可以使用一个 shell script 来解决输入问题,但是也需要重新编译 所有文件,在大型项目上很没有效率。
如果有成百上千的源文件的话怎么办?如果我们在与很多人合作写程序,别人 对源文件进行了修改,又没有告诉你,该怎么办?
也许我们可以把以上两种方法结合,写一种像 shell script 一样的东西。这 种文件包含某种技巧可以决定什么时候该对源文件进行编译。现在所有我们要的就是 一个程序可以懂得这种技巧,因为要懂得这种技巧,shell 还没那么大的能耐。
这个程序就叫 make。它读入一个文件,叫 makefile,这个文件决定了源文件之间的依赖关系。而且 决定了源文件什么时候该编译什么时候不应该编译。例如,某个规则可以说 “ 如果 fromboz.o 比 fromboz.c 要旧, 意思就是有人修改了 fromboz.c,因此我们需要重新编译这 个文件。”这个 makefile 还有规则通知 make 该 怎么 重新编译源文件,因此 make 是一个强大得多的工具。
makefile 通常和相关的源文件保存在同一个目录下,可以叫做 makefile,Makefile 或者 MAKEFILE。大多数程序员会使用 Makefile 这个名字,因为这样可以让这个文件被放在目录列 表的顶端,可以很容易得看见。 [6]
2.5.2 使用 make 的例子
这是一个非常简单的 make 文件:
foo: foo.c
cc -o foo foo.c
包含两行,一行是依赖关系,一行是执行动作。
依赖关系的那一行包含了程序的名字 (叫做 target),紧跟着一个冒号,然后是空格,最后是源文件的 名字。当 make读入这一行的时候,会检查 foo 是否存在;如果存在,就比较 foo 和 foo.c 最后的修改时间有什 么不同。如果 foo 不存在,或者比 foo.c 要旧,就检查执行动作那一行看看该怎么做。换句话 说,就是 foo.c 需要重新编译的时候该怎么办。
执行动作那一行以一个 tab (按下 tab) 开始,然后是你在命令行下产生 foo 所执行的命令。如果 foo 过期了,或者不存在,make 就会 执行这个命令来产生 foo。换句话说,这就是重新编译 foo.c 的规则。
因此,当你输入 make 时,它会确定 foo 和 foo.c 在修改时间上是否同 步。这个原则可以在 Makefile 里扩展到成百上千的目标文 件上──实际上,在 FreeBSD 里,你只要在合适的目录下输入 make world 就可以编译整个操作系统!
makefile 另一个有用的特点就是目标文件不一定就是程序。例如,我们可以 有这样的 make 文件。
foo: foo.c
cc -o foo foo.c
install:
cp foo /home/me
我们可以输入如下的命令告诉 make 该执行哪个目标:
% make target
make 会只执行这个目标而忽略其他的目标。例如,如果 我们输入 make foo,就只有 foo 被执行,必要的情况下重新编译 foo 而不会继续执行 install 这个目标。
如果我们只是输入 make 这个命令,make 总会寻找 第一个目标,并且在执行完以后就不管其他的目标了。例如,如果我们输入 make foo,make 就会转到 foo 这个目标,在必要的情况下重新编译 foo,而不会执行 install 目标, 然后就停止了。
一定要注意,install 这个目标不依赖任何其他 的东西!这意味着我们一旦输入 make install,这个目标 下的所有命令都将被执行。这种情况下,foo 将被安装到用 户的家目录下。应用程序的 makefile 正是这样写的,以便程序在正确编译后可以被 安装到正确的目录。
要尝试解释的话会比较容易让人混淆。如果你不太懂 make 是如何工作的,最好的办法就是先写一个简单的程序例如 “hello world” 以及和上面的例子相同的 make 文件再去实验。然后 再进一步,使用多个源文件,或者让你的源文件包含一个头文件。 touch 命令在这里就非常有用了──它能让在不改变文件内 容的情况下改变文件的日期。
2.5.3 Make 和 include-文件
C 源码的开头经常有一系列被包含的头文件,例如 stdio.h。有一些是系统级的 头文件,有一些是你正在写的项目的头文件:
#include <stdio.h> #include "foo.h" int main(....
要确定在你的 foo.h 被改变之后,这个文件也会被重 新编译,就要在你的 Makefile 这样写:
foo: foo.c foo.h
当你的项目变得越来越大,你自己的头文件越来越多的时候,要追踪所有这些
头文件和所有依赖它的文件会是一件痛苦的事情。如果你改变了其中一个头文件,却
忘了重新编译所有依赖它的源文件,结果会是很失望的。gcc
有一个选项可以分析你的源文件然后产生一个头文件的列表和它的依赖关系: -MM。
如果你把下面的内容加到你的 Makefile 里面:
depend:
gcc -E -MM *.c > .depend
然后运行 make depend,就会产生一个 .depend,里面包含了目标文件,C 文件和头文件的列表:
foo.o: foo.c foo.h
如果你改变了 foo.h,下一次运行 make 的时候,所有依赖 foo.h 的文件 就会被重新编译。
每一次你增加一个头文件的时候,别忘了运行一次 make depend。
2.5.4 FreeBSD 的 Makefile 文件
写 Makefile 文件可以是很难的一件事情。幸运的是,像 FreeBSD 这样基于 BSD 的系统,系统本身就自带了一些非常强大的 Makefile 文件。一个很好的例子就 是 FreeBSD 的 ports 系统。这里列出了一个典型的 ports 的 Makefile 的重要部分:
MASTER_SITES= ftp://freefall.cdrom.com/pub/FreeBSD/LOCAL_PORTS/ DISTFILES= scheme-microcode+dist-7.3-freebsd.tgz .include <bsd.port.mk>
现在,如果我们进入这个 port 的目录然后输入 make,就有如下的步骤发生:
-
检查这个 port 的源文件在系统中是否存在。
-
如果不存在,根据
MASTER_SITES指定的 URL,系统 将会使用 FTP 连接下载这个源文件。 -
计算源文件的校检码,然后与先前被记录的,已知的,完好的源文件校检 码对比。这样做就是要确认源文件在传送过程中没有损坏。
-
执行任何让源文件可以在 FreeBSD 上运行的修改──这叫做 打补丁。
-
完成源文件需要的特殊的配置。(很多 UNIX 程序在被编译的时候都会 检测自己正在哪个版本的 UNIX 上面以及哪些可选的 UNIX 特性是存在的 ──这一步里面,在 FreeBSD 的 ports 框架中这些程序将会取得这些信息。
-
编译程序的源代码。实际上,我们将进入到源代码解压后生成的目录中, 然后再执行 make──程序自身的 make 文件包含了编 译程序所需要的信息。
-
现在我们有了一个编译好的程序。如果我们愿意,可以测试一下;当我们 对程序满意了以后,就输入 make install。这个命令 将把程序自身还有任何它依赖的文件都复制到正确的位置;在一个 包数据库 中会加上一条记录以便我们改变想法的时候可 以很简单的删除掉这个 port。
现在我想你一定会同意,对于一个只有四行的脚本,这让人印象非常深刻!
秘密就在最后一行,这一行告诉 make 去找系统级的 make 文件,叫做 bsd.port.mk。要忽略这一行很简单,但是 就是这一行做了所有聪明的工作──有人已经写好了一个 make 文件,让 make 去做刚才提到的步骤 (加上一些我没提到的,包括对可能 的错误的处理)。而且任何人都可以在自己的 make 文件中简单的加上一行命令来使 用这个文件!
如果你想看看这些系统级的 make 文件,可以到 /usr/share/mk 里面找找。不过最好等到你对 make 文件有 了一点点感性的经验以后再去看。因为这些文件都非常复杂(而且如果你在看的时 候,最好准备一大杯浓浓的绿茶!)。
2.5.5 更多 make 的高级用法
Make 是一个非常强大的工具,甚至还可以做比以上提到 的更复杂的工作。不幸的是,make 有不同的版本,各个版本之 间差别还很大。学习使用这个命令的最好的方法可能就是阅读文档──希望这一 章能够给你的学习打一个基础。
FreeBSD 自带的 make 叫做 Berkeley make; /usr/share/doc/psd/12.make 是一个教程。要看这个教程, 在那个目录中执行
% zmore paper.ascii.gz
Ports 中的很多应用程序使用 GNU make,它 包含一个非常棒的 “info” 页面的集合。如果你安装了任何一个这样 的 port,GNU make 就会自动被安装为 gmake 命令。当然你也可以用正常的 port 或 package 的方式 来安装。
要查看 GNU make 的 info 页面,你必须编辑 /usr/local/info 路径下的 dir 文 件,在其中添加一个条目。需要添加的内容可以是这样
* Make: (make). The GNU Make utility.
一旦你完成编辑,就可以输入命令 info 然后从菜 单中选择 make (或者在 Emacs 中,输入 C-h i)。
2.6 调试
2.6.1 调试器
FreeBSD 自带的调试器叫 gdb (GNU debugger)。要运行,输入
% gdb progname
然而大多数人喜欢在 Emacs 中运行这个命令。 可以这样来起动这个命令:
M-x gdb RET progname RET
调试器能让你在一个可控制的环境中运行一个程序。例如,你可以一次运行程 序的一行代码,检查变量的值,改变这些值,或者让程序运行到某个定点然后停止等 等。你甚至可以调试内核,当然这样会比我们将要讨论的问题要多一点点技巧。
gdb 有非常棒的在线帮助,还有同样棒的 info 页面。 因此这一章我们会把注意力集中到一些基本的命令上。
最后,如果你不习惯这个命令的命令行界面,在 Ports 中还有一个它的图形 前端 (devel/xxgdb)。
这一章准备只介绍 gdb 的使用方法,而不会牵涉到特殊 的问题比如调试内核。
2.6.2 在调试器中运行一个程序
要最大限度的利用 gdb,需要使用 -g 这个选项来编译你的程序。如果你没有这样做,那么你只会看
到你正在调试的函数名字,而不是它的源代码。如果 gdb起动
时提示:
... (no debugging symbols found) ...
你就知道你的程序在编译的时候没有使用 -g 选项。
当 gdb 给出提示符,输入 break
main。 这就是告诉调试器你对正在运行的程序中预先设置的代码没有兴趣,
并且调试器应该停在你的代码的开头。然后输入 run
来开始你的程序──这会从 预先设置的代码开始然后在调试器调用 main() 的时候就停 下来。(如果你曾迷惑 main() 是在哪里被调用的,现在应该 明白了吧!)
现在你可以一步一步来检查你的程序,按下 n一次就查 一行。一旦你碰见了一个函数调用,可以输入 f 从函数调用中 退出来。你可以输入 up 或 down 来快速 检查这个调用。
这里列出了一个简单的例子。展示了怎样用 gdb 定位一个错 误。这是我们的程序(其中有一个明显的错误):
#include <stdio.h>
int bazz(int anint);
main() {
int i;
printf("This is my program\n");
bazz(i);
return 0;
}
int bazz(int anint) {
printf("You gave me %d\n", anint);
return anint;
}
这个程序给 i 赋值 5
并把它传递给 一个函数 bazz(),这个函数将打印出我们给出的数值。
我们现在编译并运行这个程序,我们会得到
% cc -g -o temp temp.c % ./temp This is my program anint = 4231
但这并不是我们想要的!应该看看到底发生了什么!
% gdb temp GDB is free software and you are welcome to distribute copies of it under certain conditions; type "show copying" to see the conditions. There is absolutely no warranty for GDB; type "show warranty" for details. GDB 4.13 (i386-unknown-freebsd), Copyright 1994 Free Software Foundation, Inc. (gdb) break main Skip the set-up code Breakpoint 1 at 0x160f: file temp.c, line 9. gdb puts breakpoint atmain()(gdb) run Run as far asmain()Starting program: /home/james/tmp/temp Program starts running Breakpoint 1, main () at temp.c:9 gdb stops atmain()(gdb) n Go to next line This is my program Program prints out (gdb) s step intobazz()bazz (anint=4231) at temp.c:17 gdb displays stack frame (gdb)
停住!怎么 anint 会是 4231?难道 我们没有在函数 main()
中设定为 5 吗?现在我们转到 main()
来看看。
(gdb) up Move up call stack
#1 0x1625 in main () at temp.c:11 gdb displays stack frame
(gdb) p i Show us the value of i
$1 = 4231 gdb displays 4231
哦,天哪!看看这代码,我们忘了初始化 i 了。本来我们
是想的
...
main() {
int i;
i = 5;
printf("This is my program\n");
...
但是我们忘了 i=5; 这一行。因为我们没有初始化 i,这个变量在程序运行的时候就储存了偶然在那块内存中存在的
任意值。
注意: gdb 会显示我们进入或离开一个函数时的栈的值。即 使是我们在使用 up 或 down 的时候。 这会显示函数的名称还有参数的值,让我们知道自己的位置以及正在发生什么事情。 (栈能储存程序在调用函数的时使用的参数,以及调用时的位置,以便程序在从函 数调用结束后知道自己的位置。)
2.6.3 检查 core 文件
基本上 core 文件就是一个包含了程序崩溃时这个进程的所有信息的文件。在那 “遥远的黄金年代”,程序员不得不把 core 文件以十六进制的方式显示 出来,然后满头大汗的阅读机器码的手册,但是现在事情就简单得多了。顺便说一下, 在 FreeBSD 和其他的 4.4BSD 系统下,core 文件都叫作 progname.core 而不是简单叫 core,这样可以很清楚的表示出这个 core 文件是属于哪个 程序。
要检查一个 core 文件,以通常的方式起动 gdb。不要 输入 break 或者 run,而要输入
(gdb) core progname.core
如果你没有和 core 文件在同一个目录,首先要执行 dir /path/to/core/file。
你应该可以看见:
% gdb a.out GDB is free software and you are welcome to distribute copies of it under certain conditions; type "show copying" to see the conditions. There is absolutely no warranty for GDB; type "show warranty" for details. GDB 4.13 (i386-unknown-freebsd), Copyright 1994 Free Software Foundation, Inc. (gdb) core a.out.core Core was generated by `a.out'. Program terminated with signal 11, Segmentation fault. Cannot access memory at address 0x7020796d. #0 0x164a in bazz (anint=0x5) at temp.c:17 (gdb)
这种情况下,运行的程序叫 a.out,因此 core 文件 就叫 a.out.core。我们知道程序崩溃的原因就是函数 bazz 试图访问一块不属于它的内存。
有时候,能知道一个函数是怎么被调用的是非常有用处的。因为在一个复杂的 程序里面问题可能会发生在函数调用栈上面很远的地方。命令 bt 会让 gdb 输出函数调用栈的回溯追踪。
(gdb) bt #0 0x164a in bazz (anint=0x5) at temp.c:17 #1 0xefbfd888 in end () #2 0x162c in main () at temp.c:11 (gdb)
函数 end() 在一个程序崩溃的时候将被调用;在本例
中,函数 bazz() 是从 main()
中被 调用的。
2.6.4 粘付到一个正在运行的程序
gdb 一个最精致的特性就是它能粘付到一个已经在运行 的程序上。当然,我们得首先假定你有足够的权限这样去做。一个常见的问题就是, 当我们在追踪一个包含子进程的程序时,如果你要追踪子进程,但是调试器只允许你 追踪父进程。
你要做的就是起动另一个 gdb,然后用 ps 找出子进程的进程号。然后在 gdb中执行
(gdb) attach pid
就可以像平时一样调试了。
“这很好,”你可能在想,“当我这样做了以后,子进程就 会不见了”。别怕,亲爱的读者,我们可以这样来做(参照 gdb 的 info 页)
...
if ((pid = fork()) < 0) /* _Always_ check this */
error();
else if (pid == 0) { /* child */
int PauseMode = 1;
while (PauseMode)
sleep(10); /* Wait until someone attaches to us */
...
} else { /* parent */
...
现在所有你要做的就是粘付到子进程,设置 PauseMode 为
0,然后等待函数 sleep 返回!
2.7 使用 Emacs 作为开发环境
2.7.1 Emacs
很不幸,UNIX 系统不像其他的系统那样带有一种“你要的全有,不要的更多”的,包含所有 的,巨大的程序开发环境。 [7] 但是,你可以搭建一个自己的开发环境。可能不会很漂亮,也不会非常集成化。但 是你可以按自己的需求来搭建。而且是免费的。你将拥有所有的源码。
问题的答案就是 Emacs。如今有很多人厌恶它,也有很多喜欢它。如果你是前 者之一,恐怕这一章不会引起你的兴趣。而且,你需要一定量的内存来运行 Emacs──文字界面我推荐 8MB,而在 X 下最少需要 16MB 来获得合理的性能。
Emacs 基本上是一个高度可配置的编辑器──实际上,Emacs 更像一个操 作系统而不像一个编辑器!很多开发人员和系统管理员把所有的时间都花在 Emacs 里面,只在退出登陆的时候才退出这个编辑器。
要在这里概括所有 Emacs 能做的事情是不可能的,但是这里列出了一些开发人员可能感 兴趣的特性:
-
非常强大的编辑器,允许对字串和正则表达式(类型)进行搜索和替代。跳 至块结构的开始/末尾,等等。
-
下拉菜单和在线帮助。
-
语言相关的语法高亮显示和缩进。
-
完全可配置。
-
你可以在 Emacs 中编译和调试程序。
-
出现编译错误以后,你可以直接跳至出问题的那一行代码。
-
比较友好的 info 的前端,可以阅读 GNU 超文本文 档。当然包括 Emacs 自己的文档。
-
友好的 gdb 的前端,允许你在追踪程序的时候查看 源代码。
-
你可以在编译程序的同时查看 Usenet 新闻和阅读邮件。
毫无疑问还有很多被我忽略的。
在 FreeBSD 上可以用 editors/emacs port 来安装 Emacs。
一旦安装好了,就可以运行 Emacs,然后输入 C-h t 阅读 Emacs 教程──意思就是说按住 control,再按 h,松开 control,然后再按 t。(或者,你可以使用鼠 标从 Help 菜单重选择 Emacs Tutorial)。
尽管 Emacs 有菜单,最好还是学习一下键组合。因为在你编辑的时候,连续 地按下一系列按键,比找到鼠标然后点击正确的地方要快得多。而且,当你和一个老 Emacs 用户交流的时候,你经常会碰到下列的表达 “M-x replace-s RET foo RET bar RET”,因此知道这些东西会很有用。而且在任 何情况下,Emacs 的菜单里永远放不下所有它实际上拥有的有用的功能。
幸运的是,很容易学习键组合。因为菜单每个项目的后面都标示了对应的键组 合。我的建议就是,首先使用菜单项,比如,打开一个文件,直到你明白了其中的奥 妙,并且可以自信的使用这个菜单项,再尝试使用 C-x C-f。当你一点困难也没有的 时候,就可以转到下一个菜单项继续练习。
如果记不住一个特殊的键组合到底能做什么,可以从 Help 菜单中选择 Describe Key ,然后输入这个键组合──Emacs 会告诉你它到底能干什么。你也可以点击 Command Apropos来寻找包含一个特定词的命令, 后面紧跟的就是键组合。
另外,刚才那个表达式的意思就是按住 Meta 键,按下 x 键,松开 Meta 键,输入 replace-s (replace-string的简写 ──Emacs 另一个特性就是命令的缩写),按下 return键,输 入 foo(你要替换的字串),输入 bar (你要用来替换 foo 的字串) 然后再次按下 return 键。 Emacs 就会按你的要求进行搜索和替换操作。
你一定在疑惑 Meta 键是个什么键。这是一个很多 UNIX 工作站都有的特殊的键。很不幸,PC没有这样一个键。通常在 PC 上这个键是 alt 键(如果你运气不好,这个键在你的 PC 上会是 escape 键)。
哦,要退出 Emacs,键入 C-x C-c (意思就是按住 control 键,按下 x,按下 c,再松开 control 键)。如果你还有已经打 开的未保存的文件,Emacs 会问你是否要保存文件。(不要理会文档中说的退出 Emacs 的常用方法 C-z──这个键组合会把 Emacs 放到后 台,而且这个方法只在没有虚拟控制台的系统上有用)。
2.7.2 配置 Emacs
Emacs 能做很多有用的事情;一些是内置的,另外一些需要我们进行配置。
Emacs 没有用一种私有的宏语言来配置自身,而是使用了某种特别适应编辑器 的 Lisp 版本,叫做 Emacs Lisp。如果你要继续读下去并且想学习一点 Common Lisp,学习使用 Emacs Lisp 是很有用的。Emacs Lisp 有很多 Common Lisp 的特性, 虽然前者相当小 (因此更容易掌握)。
学习 Emacs Lisp 最好的方法就是下载 Emacs Tutorial。
但是,要配置 Emacs 并不需要任何实际的 Lisp 知识,因为我已经列出了一 个 .emacs 例子,足够让你顺利的开始工作。只要把这个文 件复制到你的家目录,如果 Emacs 已经在运行,就重新起动;Emacs 会从这个文件 中读取命令,然后(希望)能给你一个有用的基本设置。
2.7.3 一个 .emacs 配置文件的例子
不幸的是,要详细解释的话话就长了;但是还是有一两点值得注意。
-
以 ; 开头的是注释,会被 Emacs 忽略掉。
-
第一行里面的 -*- Emacs-Lisp -*- 能 让我们在 Emacs 里面编辑这个 .emacs,并且打开所 有 Emacs Lisp 的编辑特性。Emacs 一般会尝试根据文件名来猜测,而且很有可 能猜错。
-
在某些模式下,tab 键被绑定到一个缩进函数上。因 此按下 tab 键后,它能缩进一行代码。如果你想把 tab 当作 一个字符插入到你编辑的东西里面,需要在按下 tab 键的时 同时按住 control 键。
-
这个文件通过识别文件名后缀来支持 C,C++,Perl,Lisp 和 Scheme 的语法高亮。
-
Emacs 已经有一个预先定义的函数叫
next-error。 在一个编译错误输出窗口,按下 M-n 能让从一个编译错误 移动到另一个;我们还定义了一个类似的函数,previous-error,这个函数在你按下 M-p 后,能让你回到上一个编译错误。其中最好的特性就是按 下 C-c C-c 后,能根据错误打开相应的文件并且跳到相应 的那行代码。 -
我们打开了 Emacs 作为 服务端运行的特性,这样当你在 Emacs 外做一 些事情的时候,又需要编辑一个文件的时候,只需要输入
% emacsclient filename然后就可以在 Emacs 编辑那个文件了! [8]
例 2-1. 一个 .emacs 配置文件的例子
;; -*-Emacs-Lisp-*-
;; This file is designed to be re-evaled; use the variable first-time
;; to avoid any problems with this.
(defvar first-time t
"Flag signifying this is the first time that .emacs has been evaled")
;; Meta
(global-set-key "\M- " 'set-mark-command)
(global-set-key "\M-\C-h" 'backward-kill-word)
(global-set-key "\M-\C-r" 'query-replace)
(global-set-key "\M-r" 'replace-string)
(global-set-key "\M-g" 'goto-line)
(global-set-key "\M-h" 'help-command)
;; Function keys
(global-set-key [f1] 'manual-entry)
(global-set-key [f2] 'info)
(global-set-key [f3] 'repeat-complex-command)
(global-set-key [f4] 'advertised-undo)
(global-set-key [f5] 'eval-current-buffer)
(global-set-key [f6] 'buffer-menu)
(global-set-key [f7] 'other-window)
(global-set-key [f8] 'find-file)
(global-set-key [f9] 'save-buffer)
(global-set-key [f10] 'next-error)
(global-set-key [f11] 'compile)
(global-set-key [f12] 'grep)
(global-set-key [C-f1] 'compile)
(global-set-key [C-f2] 'grep)
(global-set-key [C-f3] 'next-error)
(global-set-key [C-f4] 'previous-error)
(global-set-key [C-f5] 'display-faces)
(global-set-key [C-f8] 'dired)
(global-set-key [C-f10] 'kill-compilation)
;; Keypad bindings
(global-set-key [up] "\C-p")
(global-set-key [down] "\C-n")
(global-set-key [left] "\C-b")
(global-set-key [right] "\C-f")
(global-set-key [home] "\C-a")
(global-set-key [end] "\C-e")
(global-set-key [prior] "\M-v")
(global-set-key [next] "\C-v")
(global-set-key [C-up] "\M-\C-b")
(global-set-key [C-down] "\M-\C-f")
(global-set-key [C-left] "\M-b")
(global-set-key [C-right] "\M-f")
(global-set-key [C-home] "\M-<")
(global-set-key [C-end] "\M->")
(global-set-key [C-prior] "\M-<")
(global-set-key [C-next] "\M->")
;; Mouse
(global-set-key [mouse-3] 'imenu)
;; Misc
(global-set-key [C-tab] "\C-q\t") ; Control tab quotes a tab.
(setq backup-by-copying-when-mismatch t)
;; Treat 'y' or <CR> as yes, 'n' as no.
(fset 'yes-or-no-p 'y-or-n-p)
(define-key query-replace-map [return] 'act)
(define-key query-replace-map [?\C-m] 'act)
;; Load packages
(require 'desktop)
(require 'tar-mode)
;; Pretty diff mode
(autoload 'ediff-buffers "ediff" "Intelligent Emacs interface to diff" t)
(autoload 'ediff-files "ediff" "Intelligent Emacs interface to diff" t)
(autoload 'ediff-files-remote "ediff"
"Intelligent Emacs interface to diff")
(if first-time
(setq auto-mode-alist
(append '(("\\.cpp$" . c++-mode)
("\\.hpp$" . c++-mode)
("\\.lsp$" . lisp-mode)
("\\.scm$" . scheme-mode)
("\\.pl$" . perl-mode)
) auto-mode-alist)))
;; Auto font lock mode
(defvar font-lock-auto-mode-list
(list 'c-mode 'c++-mode 'c++-c-mode 'emacs-lisp-mode 'lisp-mode 'perl-mode 'scheme-mode)
"List of modes to always start in font-lock-mode")
(defvar font-lock-mode-keyword-alist
'((c++-c-mode . c-font-lock-keywords)
(perl-mode . perl-font-lock-keywords))
"Associations between modes and keywords")
(defun font-lock-auto-mode-select ()
"Automatically select font-lock-mode if the current major mode is in font-lock-auto-mode-list"
(if (memq major-mode font-lock-auto-mode-list)
(progn
(font-lock-mode t))
)
)
(global-set-key [M-f1] 'font-lock-fontify-buffer)
;; New dabbrev stuff
;(require 'new-dabbrev)
(setq dabbrev-always-check-other-buffers t)
(setq dabbrev-abbrev-char-regexp "\\sw\\|\\s_")
(add-hook 'emacs-lisp-mode-hook
'(lambda ()
(set (make-local-variable 'dabbrev-case-fold-search) nil)
(set (make-local-variable 'dabbrev-case-replace) nil)))
(add-hook 'c-mode-hook
'(lambda ()
(set (make-local-variable 'dabbrev-case-fold-search) nil)
(set (make-local-variable 'dabbrev-case-replace) nil)))
(add-hook 'text-mode-hook
'(lambda ()
(set (make-local-variable 'dabbrev-case-fold-search) t)
(set (make-local-variable 'dabbrev-case-replace) t)))
;; C++ and C mode...
(defun my-c++-mode-hook ()
(setq tab-width 4)
(define-key c++-mode-map "\C-m" 'reindent-then-newline-and-indent)
(define-key c++-mode-map "\C-ce" 'c-comment-edit)
(setq c++-auto-hungry-initial-state 'none)
(setq c++-delete-function 'backward-delete-char)
(setq c++-tab-always-indent t)
(setq c-indent-level 4)
(setq c-continued-statement-offset 4)
(setq c++-empty-arglist-indent 4))
(defun my-c-mode-hook ()
(setq tab-width 4)
(define-key c-mode-map "\C-m" 'reindent-then-newline-and-indent)
(define-key c-mode-map "\C-ce" 'c-comment-edit)
(setq c-auto-hungry-initial-state 'none)
(setq c-delete-function 'backward-delete-char)
(setq c-tab-always-indent t)
;; BSD-ish indentation style
(setq c-indent-level 4)
(setq c-continued-statement-offset 4)
(setq c-brace-offset -4)
(setq c-argdecl-indent 0)
(setq c-label-offset -4))
;; Perl mode
(defun my-perl-mode-hook ()
(setq tab-width 4)
(define-key c++-mode-map "\C-m" 'reindent-then-newline-and-indent)
(setq perl-indent-level 4)
(setq perl-continued-statement-offset 4))
;; Scheme mode...
(defun my-scheme-mode-hook ()
(define-key scheme-mode-map "\C-m" 'reindent-then-newline-and-indent))
;; Emacs-Lisp mode...
(defun my-lisp-mode-hook ()
(define-key lisp-mode-map "\C-m" 'reindent-then-newline-and-indent)
(define-key lisp-mode-map "\C-i" 'lisp-indent-line)
(define-key lisp-mode-map "\C-j" 'eval-print-last-sexp))
;; Add all of the hooks...
(add-hook 'c++-mode-hook 'my-c++-mode-hook)
(add-hook 'c-mode-hook 'my-c-mode-hook)
(add-hook 'scheme-mode-hook 'my-scheme-mode-hook)
(add-hook 'emacs-lisp-mode-hook 'my-lisp-mode-hook)
(add-hook 'lisp-mode-hook 'my-lisp-mode-hook)
(add-hook 'perl-mode-hook 'my-perl-mode-hook)
;; Complement to next-error
(defun previous-error (n)
"Visit previous compilation error message and corresponding source code."
(interactive "p")
(next-error (- n)))
;; Misc...
(transient-mark-mode 1)
(setq mark-even-if-inactive t)
(setq visible-bell nil)
(setq next-line-add-newlines nil)
(setq compile-command "make")
(setq suggest-key-bindings nil)
(put 'eval-expression 'disabled nil)
(put 'narrow-to-region 'disabled nil)
(put 'set-goal-column 'disabled nil)
(if (>= emacs-major-version 21)
(setq show-trailing-whitespace t))
;; Elisp archive searching
(autoload 'format-lisp-code-directory "lispdir" nil t)
(autoload 'lisp-dir-apropos "lispdir" nil t)
(autoload 'lisp-dir-retrieve "lispdir" nil t)
(autoload 'lisp-dir-verify "lispdir" nil t)
;; Font lock mode
(defun my-make-face (face color &optional bold)
"Create a face from a color and optionally make it bold"
(make-face face)
(copy-face 'default face)
(set-face-foreground face color)
(if bold (make-face-bold face))
)
(if (eq window-system 'x)
(progn
(my-make-face 'blue "blue")
(my-make-face 'red "red")
(my-make-face 'green "dark green")
(setq font-lock-comment-face 'blue)
(setq font-lock-string-face 'bold)
(setq font-lock-type-face 'bold)
(setq font-lock-keyword-face 'bold)
(setq font-lock-function-name-face 'red)
(setq font-lock-doc-string-face 'green)
(add-hook 'find-file-hooks 'font-lock-auto-mode-select)
(setq baud-rate 1000000)
(global-set-key "\C-cmm" 'menu-bar-mode)
(global-set-key "\C-cms" 'scroll-bar-mode)
(global-set-key [backspace] 'backward-delete-char)
; (global-set-key [delete] 'delete-char)
(standard-display-european t)
(load-library "iso-transl")))
;; X11 or PC using direct screen writes
(if window-system
(progn
;; (global-set-key [M-f1] 'hilit-repaint-command)
;; (global-set-key [M-f2] [?\C-u M-f1])
(setq hilit-mode-enable-list
'(not text-mode c-mode c++-mode emacs-lisp-mode lisp-mode
scheme-mode)
hilit-auto-highlight nil
hilit-auto-rehighlight 'visible
hilit-inhibit-hooks nil
hilit-inhibit-rebinding t)
(require 'hilit19)
(require 'paren))
(setq baud-rate 2400) ; For slow serial connections
)
;; TTY type terminal
(if (and (not window-system)
(not (equal system-type 'ms-dos)))
(progn
(if first-time
(progn
(keyboard-translate ?\C-h ?\C-?)
(keyboard-translate ?\C-? ?\C-h)))))
;; Under UNIX
(if (not (equal system-type 'ms-dos))
(progn
(if first-time
(server-start))))
;; Add any face changes here
(add-hook 'term-setup-hook 'my-term-setup-hook)
(defun my-term-setup-hook ()
(if (eq window-system 'pc)
(progn
;; (set-face-background 'default "red")
)))
;; Restore the "desktop" - do this as late as possible
(if first-time
(progn
(desktop-load-default)
(desktop-read)))
;; Indicate that this file has been read at least once
(setq first-time nil)
;; No need to debug anything now
(setq debug-on-error nil)
;; All done
(message "All done, %s%s" (user-login-name) ".")
2.7.4 扩展 Emacs 所支持语言的范围
现在,如果你只是想用 .emacs 设定好的语言 (C, C++, Perl, Lisp 和 Scheme) 来编程,事情就很好办。但是,如果突然一个新的语 言,叫 “whizbang”,有很多激动人心的特性,出来了,会发生什么事情?
第一件要做的事情就是找到是否有任何文件能够告诉 Emacs 关于这个语言的 信息。这种文件通常以 .el 结尾,是 “Emacs Lisp” 的缩写。例如,如果 whizbang 是 FreeBSD 的一个 port,那么我们 可以用如下命令来定位这些文件
% find /usr/ports/lang/whizbang -name "*.el" -print
然后安装这些文件到 Emacs 的系统级 Lisp 目录。在 FreeBSD 2.1.0-Release 里,这个目录就是 /usr/local/share/emacs/site-lisp。
例如,如果刚才的定位命令的输出是
/usr/ports/lang/whizbang/work/misc/whizbang.el
我们可以执行
# cp /usr/ports/lang/whizbang/work/misc/whizbang.el /usr/local/share/emacs/site-lisp
下一步,我们需要确定 whizbang 的源文件是以什么后缀结尾。我们假定这些 源文件都是以 .wiz 结尾。我们需要在 .emacs 加上一条使 Emacs 能够使用 whizbang.el 中的信息。
在 .emacs 中找到 auto-mode-alist
entry,为 whizbang 添加一行,例如:
...
("\\.lsp$" . lisp-mode)
("\\.wiz$" . whizbang-mode)
("\\.scm$" . scheme-mode)
...
意思就是,当你编辑一个以 .wiz 结尾的文件的时候, Emacs
会自动进入 whizbang-mode。
就在下面,你会发现 font-lock-auto-mode-list 这一条。
添加 whizbang-mode
;; Auto font lock mode (defvar font-lock-auto-mode-list (list 'c-mode 'c++-mode 'c++-c-mode 'emacs-lisp-mode 'whizbang-mode 'lisp-mode 'perl-mode 'scheme-mode) "List of modes to always start in font-lock-mode")
这意味着当你编辑 .wiz 文件的时候,Emacs 会自动 打开
font-lock-mode(就是语法高亮)。
这就是所有必要的步骤。如果在你打开一个 .wiz 文
件的时候,还有需要自动执行的任何其他步骤,你可以添加一个 whizbang-mode hook (查看 my-scheme-mode-hook 中添加 auto-indent 的步骤作为例子)。
2.8 补充阅读
关于 FreeBSD 下搭建开发环境的信息的修改,可以参看 development(7)。
-
Brian Harvey and Matthew Wright Simply Scheme MIT 1994. ISBN 0-262-08226-8
-
Randall Schwartz Learning Perl O'Reilly 1993 ISBN 1-56592-042-2
-
Patrick Henry Winston and Berthold Klaus Paul Horn Lisp (3rd Edition) Addison-Wesley 1989 ISBN 0-201-08319-1
-
Brian W. Kernighan and Rob Pike The Unix Programming Environment Prentice-Hall 1984 ISBN 0-13-937681-X
-
Brian W. Kernighan and Dennis M. Ritchie The C Programming Language (2nd Edition) Prentice-Hall 1988 ISBN 0-13-110362-8
-
Bjarne Stroustrup The C++ Programming Language Addison-Wesley 1991 ISBN 0-201-53992-6
-
W. Richard Stevens Advanced Programming in the Unix Environment Addison-Wesley 1992 ISBN 0-201-56317-7
-
W. Richard Stevens Unix Network Programming Prentice-Hall 1990 ISBN 0-13-949876-1
第3章 安全的编程
供稿:Murray Stokely. 翻译:susn @NewSMTH.3.1 提要
本章描述了十年间一些令UNIX程序员感到困惑的安全问题, 并提供了一些新的工具来帮助程序员避免生成可被利用的代码。
3.2 安全的设计方法
编写安全的应用程序要带着谨慎和略有悲观的生活观点。程序应该本着 “最小特权”的原则运行,这样就不会有带着大于足够能完成 其功能的权限的进程在运行。预先测试的代码应该随时可以重用以避免遇到 一些本已经修复的通常错误。
UNIX环境的陷阱之一就是很容易的制造一个稳健环境的假象。程序 应该永远不要相信用户的输入(以各种形式),系统资源,进程间通讯,或者 触发事件的时钟。UNIX进程不是同步运行,所以逻辑操作很少是原子类型。
3.3 缓冲区溢出
缓冲区溢出的漏洞随着冯・诺依曼 1 构架的出 现就已经开始出现了。 在1988年随着莫里斯互联网蠕虫的广泛传播他们开始声名狼藉。不幸的是, 同样的这种攻击一直持续到今天。 到目前为止,大部分的缓冲区溢出的攻击都是基于摧毁栈的方式。
大部分现代计算机系统使用栈来给进程传递参数并且存储局部变量。 栈是一种在进程映象内存的高地址内的后进先出(LIFO)的缓冲区。 当程序调用一个函数时一个新的“栈帧”会被创建。这个栈帧包含着 传递给函数的各种参数和一些动态的局部变量空间。“栈指针”记录着当前 栈顶的位置。 由于栈指针的值会因为新变量的压入栈顶而经常的变化,许多实现也提供了 一种"帧指针"来定位在栈帧的起始位置,以便局部变量可以更容易的被访问。 1调用函数的返回地址也同样存储在栈中, 由于在函数中的局部变量覆盖了函数的返回地址成为了栈溢出的一个原因, 这就潜在的准许了一个恶意用户可以执行他(她)所想运行的任何代码。
虽然基于栈的攻击是目前最广泛的,这也可以使基于堆的攻击(malloc/ free)变成可能。
C程序语言并不像其他一些编程语言一样自动的做数组或者指针的边 界检查。另外,C标准库还具有相当一些非常危险的操作函数。
strcpy(char *dest, const char *src) |
可导致dest缓冲区溢出 |
strcat(char *dest, const char *src) |
可导致dest缓冲区溢出 |
getwd(char *buf) |
可导致buf缓冲区溢出 |
gets(char *s) |
可导致s缓冲区溢出 |
[vf]scanf(const char *format, ...) |
可导致参数溢出 |
realpath(char *path, char resolved_path[]) |
可导致path缓冲区溢出 |
[v]sprintf(char *str, const char *format, ...) |
可导致str缓冲区溢出 |
3.3.1 缓冲区溢出示例
下面的示例代码包含了一个缓冲区溢出的情况,它会覆盖函数的返回地址并且 立即跳过了紧随此函数之后调用。(授权于5)
#include <stdio.h>
void manipulate(char *buffer) {
char newbuffer[80];
strcpy(newbuffer,buffer);
}
int main() {
char ch,buffer[4096];
int i=0;
while ((buffer[i++] = getchar()) != '\n') {};
i=1;
manipulate(buffer);
i=2;
printf("The value of i is : %d\n",i);
return 0;
}
让我们来查看一下如果在输入回车之前输入160个空格后这个小程序 的内存映象是个什么样子。
[XXX figure here!]
很明显更多的恶意输入能被设计出执行实际的编译指令(例如 exec(/bin/sh))。
3.3.2 避免缓冲区溢出
对于栈溢出的最直接的解决方法就是总是使用长度有限的内存和 字符串复制函数。strncpy和strncat
是C标准库的一部分。 这些函数接收一个不大于目标缓冲区长度的值作为参数。这些函数会从
源地址复制此值长的字节数到目标地址。然而这些函数还是有一些问题。
如果输入缓冲区的长度和目标缓冲区的一样长则函数不保证两者都以NUL 作为结束符。
长度参数在strncpy和strncat函数中同样的不一致很容易导致程序员在
正常使用时感到困惑。同时当复制一个较短的字符串到一个很大的缓冲 区中时相对于strcpy也有很重大的性能损失, 因为strncpy会用NUL填充所指定的长度。
在OpenBSD中,另一个内存复制的实现已经规避了这些问题。 函数strlcpy和strlcat
保证了当指定了非零的长度参数时目标字符串总是以NUL作为结束符。
关于这些函数的更多信息请参考7。OpenBSD 的strlcpy和strlcat
自从FreeBSD3.3的版本已经被引入了。
3.3.2.1 基于编译器运行时边界检查
不幸的是扔然有相当数量的代码在广泛使用盲目的内存复制功能 而不是我们所提及到的任何有限制的复制例程。 幸运的是有一种方法能帮助防止此类攻击 ── 一些 C/C++ 编译器实现了运行时边界检查。
ProPolice 就是一种这样的编译器特性, 而且被集成在 gcc(1) 4.1 及以后的版本中。 它替代并扩展了早期的 gcc(1) 中的 StackGuard 扩展。
ProPolice 有助于保护基于栈的缓冲区溢出和其他一些攻击, 比如调用任何函数之前在栈关键地方设置了伪随机数。 当一个函数返回时,就会检查这些 “canaries”, 如果发现他们被改变了就会立即停止运行。 因此任何企图修改返回地址或者修改存于栈上的变量以尝试运行恶意代码都多半不能成功, 因为攻击者还不得不设法防止伪随机的 canaries 不被改动。
使用 ProPolice 重新编译你的程序可以有效的防止大部分的缓冲 区溢出的攻击,但是这仍然是个折衷的办法。
3.3.2.2 基于库运行时边界检查
基于编译器的机制对于不能重新编译的只有二进制的软件完
全无用。对于这些情况仍还是有很多库可以对C库中的不安全的函数 (strcpy, fscanf, getwd等)重新实现并确保这些函数决不回写 栈指针。
-
libsafe
-
libverify
-
libparanoia
不幸的是这些基于库的防护有一些缺点。这些库仅仅保护和安全 相关的一小部分集合,他们忽略了实际的问题。如果程序使用参数 -fomit-frame-pointer进行编译的话这些防护也许会失败。同样,环境 变量LD_PRELOAD和LD_LIBRARY_PATH也可以被用户取消或者重置。
3.4 SetUID 问题
对于给定的进程至少有6个不同的ID与之关联。因此你不得不非常 关注你的程序在任何特定时刻的权限问题。特别的,所有seteuid的程序 在不需要的时候会立刻放弃他们的特权。
实际用户ID只能被超级用户进程改变。当用户初始登陆时 login程序设置它并且极少进行更改。
如果程序准许seteuid位设置的话有效用户ID会被exec()
函数设置。应用程序可以调用seteuid()
在任何时候设置有效的用户ID为任意的实际用户ID或者保存 设置-用户-ID。当有效用户ID被 exec()函数设置后, 前一个ID的值会被保存在设置-用户-ID中。
3.5 限制你的程序环境
传统的限制进程的方法是使用系统调用chroot()
。这个系统调用使得从进程及其任何子进程所引用的其他的
路径变为根路径。对于要使程序运行成功这个调用必须在引用的目录上
拥有执行(搜索)的权限。直到你使用了chdir()
在你的新环境中它才会实际的生效。同时应该注意到如果程序具有超级
用户的权限它很容易的摆脱chroot所设置的环境。它可能靠创建设备节点
来读取内核的内容,对程序在 chroot(8)
外绑定一个调试器, 或者靠其他创造性的方法来完成操作。
系统调用chroot()的行为可以被 sysctl变量kern.chroot_allow_open_directories
的值在一定程度上控制。当此值为0时,如果有任何目录被打开 chroot()将会返回EPERM并失败。当被置为默认值1,如果
任何目录被打开并且进程已经准备调用 chroot() 那么chroot()将会返回EPERM并失败。对于其他的
值,对打开目录的检查会被完全的忽视。
3.5.1 FreeBSD的jail功能
Jail的概念在chroot()之上作了延伸,它
靠限制超级用户的权力来创建了一个真正的"虚拟服务器"。一旦一个监
狱被设置好后整个网络必须通过特别的IP地址才能到达,在这里"超级用
户权限"的力量完全的受到限制。
当在jail中时,所有在内核中使用suser()
调用的超级用户权限的尝试都会失败。然而,一些对suser()
的调用已经被更改为新的接口suser_xxx()
。这个函数对认可或者拒绝被限制的进程去取得超级用户的权 限的行为负责。
一个在Jail环境中的超级用户进程有以下权力:
-
使用可信任的操作:
setuid,seteuid,setgid,setegid,setgroups,setreuid,setregid,setlogin -
使用
setrlimit设置资源限制 -
编辑一些sysctl节点值 (kern.hostname)
-
chroot() -
在 vnode 上设置标志:
chflags、fchflags -
设置 vnode 节点的属性, 如访问权限、 所有者、 所有组、 尺寸、 上次访问时间, 以及修改时间。
-
在互联网域上绑定特权端口 (端口号 < 1024)
Jail是一个对于在一个安全环境中
运行一个仍有一些缺点的程序非常有用的工具。目前,IPC机制还没有被 更改到suser_xxx以至于像MySQL之类的程序还不
能运行在jail中。在jail中超级用户的存取可能还有非常有限的含义,
但是没有途径能正确的指出"非常有限"意味着什么。
3.5.2 POSIX®.1e 处理能力
POSIX已经发布了一个工作草案,增加了事件审计,访问控制列表, 精细特权控制,信息标签和强制访问控制。
这是一个正在进展中的工作并且是 TrustedBSD项目的重点。一些初始化的工作已经被提交到 FreeBSD-CURRENT(cap_set_proc(3))。
3.6 信任
一个程序应该永远不要假设用户环境是健全的。这包括(但是决不限于此): 用户输入,信号,环境变量,资源,IPC,mmap(内存映射),工作目录的文件系统, 文件描述符,打开文件的数量,等等
你永远不要假设你可以捕捉到所有的用户可能产生的非法输入样式。 换言之,你的程序应该过滤只准许一些你认为安全的特别的输入子集。 不正确的确认数据会导致各种错误,特别是在互联网上的CGI脚本。 对于文件名你应该额外小心比如路径("../", "/"),符号连接和shell的退出符。
Perl有一个非常棒的特性叫做“Taint”模式能避免脚本从外部程序在不
安全的途径得到使用的数据。这个方式会检查命令行参数,环境变量,位置 信息确定系统调用
(readdir(), readlink(), getpwxxx()) 的结果和所有文件的输入。
3.7 竞态条件
竞态条件是由和事件时间相关的意料之外的依赖所导致的反常行为。 换句话说,一个程序员不正确的假设一个特殊的事件总是在另一个事件之前发生。
一些通常的导致竞态条件的原因是信号,存取检查和打开文件操作。
由于信号生来就是异步事件所以在处理他们时要特别当心。存取检查中使 用access(2)然后使用open(2)
是很明显的非原子操作。用户可以在两次调用中移走文件。换言之,有特 权的程序应该使用seteuid()然后直接调用 open()。沿着同一思路,一个程序应该总是在 open()之前设置正确的掩码来排除不合逻辑的 chmod()调用。
第4章 本地化与国际化 - L10N 和 I18N
翻译:susn @NewSMTH.4.1 编写适应国际化的应用程序
为了使你的程序对于使用其他语言的用户更加有用, 我们希望你的程序应该国际化。 GNU的gcc编译器和GUI库比如QT或者GTK等通过对字符串的特殊处理来支持国际化。 生成一个支持国际化的程序非常容易。 它使得发布者很快的把你的程序移植成其他语言。 请参看详细的I18N文档来获得更多的信息。
对比与通常的理解,兼容国际化的代码非常容易编写。 通常,它只需要使用一些特殊的功能函数来包装一下你的字符串。 另外,请确认支持了宽字符或者多字节字符。
4.1.1 整合I18N成果的号召
值得我们注意的是各个国家自己的I18N/L10N 的工作已经变成了重复彼此的工作。 我们中的许多人一直在做着重复的无效率的重复发明工作。 我们希望各个主要I18N的组织能聚集成一个大的组织担负起像 核心团队一样的责任。
当前,我们希望,当你在编写或者移植I18N程序时, 能够发布给各个国家相关的FreeBSD邮件列表作为测试。 将来,我们希望能生成可以直接使用各种语言的应用程序 而不是还要做一些混乱的破解。
FreeBSD 国际化邮件列表 已经建立。如果你是一个I18N/L10N的开发者, 请发送给我们任何你能想到的与之相关的说明,想法,问题等等。
4.2 使用 POSIX.1 本地语言支持 (NLS) 的本地化消息
原作 Gábor Kövesdán.除了基本的国际化功能, 例如支持不同的输入编码, 或支持类似十进制分割符之类的国民习惯之外, 还可以对程序输出的消息进行本地化。 一种比较常见的做法是使用 POSIX.1 NLS 函数, 它是作为 FreeBSD 基本系统的一部分提供的。
4.2.1 在编录文件 (Catalog Files) 中编排本地化消息
POSIX.1 NLS 是基于包含使用需要的编码编写的本地化消息所组成的编录文件工作的。 这些消息需要编写成以整数标识的集合。 习惯上, 编录文件应使用其编码命名, 并加上扩展名 .msg。 例如, 采用 ISO8859-2 编码的匈牙利文编录对应的文件名是 hu_HU.ISO8859-2。
这些编录文件都是带编号消息的普通文本文件。 如果希望在文件中添加注释, 可以在一行的开头加上 $ 作为标志。 每个集合的边界则是用特殊的注释加以区分, 这里使用的关键词 set 必须紧接注释符 $。 在关键词 set 之后则是集合的编号。 例如:
$set 1
接下来是消息项, 其内容是消息编号, 接着是本地化的消息内容。 在此处可以使用为人们所熟知的 printf(3) 格式串:
15 "File not found: %s\n"
语言编录文件必须首先编译成二进制格式才能为应用程序使用。 这个转换过程是通过 gencat(1) 工具来完成的。 它的第一个参数是输出的文件名, 随后的所有参数则都是作为输入的编录源文件。 是的, 本地化的消息也可以写到多个文件当中, 然后通过 gencat(1) 来汇集成一个文件。
4.2.2 在源代码中使用编录文件
使用编录文件比较简单, 要使用相关的函数, 需要引用头文件 nl_types.h。 在开始使用编录文件中的内容之前, 需要首先用 catopen(3) 打开它。 这个函数有两个参数。 第一个参数是安装好并事先编译过的编录的名字, 一般来说是应用程序的名字, 例如 grep。 系统会使用这个名字来查找事先编译的编录文件。 catopen(3) 函数会在 /usr/share/nls/locale/catname 以及 /usr/local/share/nls/locale/catname 中查找编录, 其中, locale 是 locale 的名字, 而 catname 则是前面调用时使用的编录名。 第二个参数是以下两者之一:
-
NL_CAT_LOCALE, 表示使用 LC_MESSAGES 的设置来查找编录。
-
0, 表示使用 LANG 来查找编录。
catopen(3) 函数会返回类型为 nl_catd 的编录描述符。 请参见联机手册以了解发生错误时返回代码的含义。
打开编录文件之后, 可以用 catgets(3) 来提取消息。 它的第一个参数是由 catopen(3) 返回的编录描述符, 第二个是消息集合的编号, 第三个是消息的编号, 第四个是当无法从编录中获得消息时使用的替代消息。
用完编录文件之后, 应使用 catclose(3) 将其关闭。 这个函数的参数是编录描述符。
4.2.3 实例
下面的例子展示了如何以灵活的方式使用 NLS 编录。
下面几行是放在一个用于在所有需要本地化消息的源代码中的公共头文件中的内容:
#ifdef WITHOUT_NLS #define getstr(n) nlsstr[n] #else #include <nl_types.h> extern nl_catd catalog; #define getstr(n) catgets(catalog, 1, n, nlsstr[n]) #endif extern char *nlsstr[];
接下来, 把这几行放到主源文件中的全局声明部分:
#ifndef WITHOUT_NLS
#include <nl_types.h>
nl_catd catalog;
#endif
/*
* Default messages to use when NLS is disabled or no catalog
* is found.
*/
char *nlsstr[] = {
"",
/* 1*/ "some random message",
/* 2*/ "some other message"
};
下面是实际的代码片段, 这里展示了如何打开, 读取和关闭编录:
#ifndef WITHOUT_NLS
catalog = catopen("myapp", NL_CAT_LOCALE);
#endif
...
printf(getstr(1));
...
#ifndef WITHOUT_NLS
catclose(catalog);
#endif
4.2.3.1 减少需要本地化的字符串数量
通过利用 libc 提供的错误信息可以减少必须本地化的字符串数量。 这种方法也能为多数程序经常遇到的错误提供更为一致的错误信息。
下面是没有使用 libc 错误信息的一个例子:
#include <err.h>
...
if (!S_ISDIR(st.st_mode))
err(1, "argument is not a directory");
上面这个例子可以改为显示与 errno 对应的错误信息:
#include <err.h>
#include <errno.h>
...
if (!S_ISDIR(st.st_mode)) {
errno = ENOTDIR;
err(1, NULL);
}
在这个例子中, 消除了自行撰写的字符串, 因而减轻了翻译人员的负担,
而用户则会看到更为熟悉的 “Not a directory” 信息。 请注意, 需要引入头文件 errno.h 才能直接读写 errno。
有时, 此前发生错误的函数可能已经设置了 errno,
对于这种情况就不需要另外加以赋值了:
#include <err.h>
...
if ((p = malloc(size)) == NULL)
err(1, NULL);
4.2.4 使用 bsd.nls.mk
使用编录文件需要一些重复的步骤, 例如编译编录, 并将它们安装到合适的位置。 为了进一步简化这些工作, bsd.nls.mk 提供了一些宏。 一般而言, 并不需要显式地引入 bsd.nls.mk, 因为其他公共 Makefiles, 如 bsd.prog.mk 和 bsd.lib.mk 会直接将其包含进来。
通常, 只要定义 NLSNAME 和 NLS 就可以了, 前者内容是前面提到的 catopen(3) 第一个参数即编录本身的名字, 而后者则是不包含 .msg 后缀的编录源文件的名字。 下面是一个例子, 它允许使用 make(1) 变量 WITHOUT_NLS 来控制是否在联编程序时加入 NLS 支持。
.if !defined(WITHOUT_NLS) NLS= es_ES.ISO8859-1 NLS+= hu_HU.ISO8859-2 NLS+= pt_BR.ISO8859-1 .else CFLAGS+= -DWITHOUT_NLS .endif
习惯上, 编录的源文件应放在程序源文件的 nls 子目录中, 这也是 bsd.nls.mk 的默认行为。 不过, 通过 make(1) 变量 NLSSRCDIR 可以改变默认的源文件目录。 预编译的编录文件名字默认也遵循前面的规范, 与此对应的 NLSNAME 变量则可以改变它。 还有一些其他微调编录文件处理方式的选项, 但通常并不需要调整那些配置, 此处不再赘述。 如欲了解进一步的详情, 请参阅 bsd.nls.mk 文件, 它很短并且很容易理解。
第5章 源代码树指南和维护发展策略
供稿:Poul-Henning Kamp 和 Giorgos Keramidas.这一章记述了 FreeBSD 源代码树各种各样的指南和有效的维护发展策略。
5.1 Makefile 中的 MAINTAINER
如果 FreeBSD src/ 中的某个部分是由某个或某一组人来维护的, 则通过 src/MAINTAINERS 文件来予以宣示。 与之对应, 在 Ports 套件中的维护关系, 是通过在 port 的 Makefile 中增加一行 MAINTAINER 来进行宣示的:
MAINTAINER= email-addresses
提示: 对于代码库中的其他部分、 没有指明维护人的部分, 或当您不确定当前维护人是谁时, 可以看看这部分最近的 commit 记录。 很多时候, 维护者可能并没有正式地予以宣示, 但一般而言在最近几年对某部分代码提交过变动的人会有兴趣对变动进行复审。 即使在文档或源代码中没有明确地予以说明, 礼貌性地要求代码复审, 也是合情合理的好习惯。
维护者的角色包括:
-
维护者拥有并对代码负责。 这表示他或她负责修正 bug, 并负责回应这些代码相关的问题报告, 对于第三方软件来说, 这还包括及时进行适当的版本更新。
-
在将变动提交到有明示维护者的目录之前, 应将变动发给维护者进行复审。 除非在发送了多封邮件之后, 维护者的回应仍然慢得无法接受。 不过, 如果可能的话, 您仍应让另外的某个人对变动进行复审。
-
当然, 直接将某人或某个小组增加到维护者的行列中是不能接受的, 除非他们同意承担这些责任。 另外, 维护者不一定必须是 committer, 此外, 它也完全可以是一个团队。
5.2 第三方软件
供稿:Poul-Henning Kamp、 David O'Brien 和 Gavin Atkinson. 翻译:李 鑫.FreeBSD 的发行版中, 可能有某些部分包含在 FreeBSD 项目之外活跃地维护着的软件。 由于历史原因, 我们将其称为 contributed 软件。 举例说来, 有 sendmail、 gcc 和 patch 等等。
在过去几年中, 我们尝试了许多不同的方法来处理这类软件, 这些方法都各有利弊, 因而也就没有明确的胜者。
基于这种情况, 在经历了一些争吵之后, 我们选定了一种作为在未来引入此类软件的 “官方” 做法。 更进一步, 我们强烈建议已有的第三方软件都逐渐过渡到使用这种方法, 因为与先前使用的做法相比, 它具有十分明显的优越性, 例如, 取得与其他软件作者 (即使没有提供直接的代码库访问权) “官方” 版本之间的差异会更容易, 等等。 这会使得将修正内容回馈给第三方软件的主要开发者变得非常容易。
当然, 最终这些方法是需要由具体的人来落实的。 如果这一模式十分不适于某个具体的软件包, 则在得到 core team 以及其他开发者认可的前提下, 可以适当地进行例外处理。 是否能够持续维护第三方软件包, 则是进行这类决策的关键因素。
注意: 由于 RCS 文件格式, 以及 vendor 分支使用上的一些不当设计, 强烈建议不要 进行任何小规模的代码修饰性的修改。 类似 “拼写错误” 这样的问题, 就属于前面提到的 “修饰性” 修改一类, 应该尽一切可能避免。 不恰当地修改一个字符, 都有可能会使代码库产生严重的膨胀。
5.2.1 在 CVS 中的 Vendor 汇入过程
用于检查文件格式的 file 工具, 在这里将作为如何进行这些操作的范例:
src/contrib/file 目录中包含了由软件包作者发布的代码。 完全不适于 FreeBSD 的那些部分可以完全删去。 对于 file(1) 而言, 在导入之前就可以删去 python 目录, 以及包含 lt 前缀的文件, 等等。
src/lib/libmagic 包含了 bmake 风格的使用标准 bsd.lib.mk makefile 规则的 Makefile 来联编函数库, 并安装文档。
src/usr.bin/file 包含了 bmake 风格的使用标准 bsd.prog.mk 规则的 Makefile, 能够联编并安装 file 程序, 以及与之相关的联机手册。
这里比较重要的事情是, src/contrib/file 目录是按照一定的规则创建的: 其中包含的源代码与原作者发布的相同 (也就是说, 这些文件会放到 vendor 分支上, 并且不进行 RCS 关键字扩展), 而只做尽可能少的专属于 FreeBSD 的改动。 如果对此有任何疑问, 则一定要先询问一下有经验的人, 而不要在对它能 “正常运转” 的期望中铸成大错。
由于前面提到的那些关于 vendor 分支设计的制约, 我们要求来自软件原作者的 “官方” 补丁, 必须首先打在其分发的源代码之上, 然后再将修改过的代码重新导入到 vendor 分支。 官方补丁在任何时候, 都不应直接应用于从 FreeBSD 源代码库检出的源代码, 并执行 “commit” 操作, 因为这会破坏 vendor 分支的一致性, 并且, 由于这样的操作会导致产生修改冲突, 会给未来导入新版时带来麻烦。
由于许多软件包可能会包含用于 FreeBSD 以外的体系结构和环境的文件, 我们允许在导入前从官方发行的代码中删去那些对 FreeBSD 无用的部分, 以期节省磁盘空间。 包含版权声明和发行说明, 以及其他类似的用于说明其他文件的文档, 则 不 应删除。
如果方便的话, 应尽可能使用使用某些工具生成的 bmake Makefile 文件, 这些工具可以使升级到未来的新版本时的工作变得简单。 如果您完成了这类工作, 请务必将这些工具 (如果需要的话) 放到 src/tools 目录中与您所移植的程序对应的目录中, 以便为将来的维护者所利用。
在 src/contrib/file 的顶级目录中, 应增加一个名为 FREEBSD-upgrade 的文件, 在其中说明一些类似下面的内容:
-
删去了哪些文件。
-
从何处可以获得原始的发行版本, 以及官方网站。
-
如果有补丁, 应如何反馈给原作者。
-
如果需要的话, 对专属于 FreeBSD 改动的概要说明。
下面是来自 src/contrib/groff/FREEBSD-upgrade 的例子:
$FreeBSD: src/contrib/groff/FREEBSD-upgrade,v 1.5.12.1 2005/11/15 22:06:18 ru Exp $
This directory contains virgin copies of the original distribution files
on a "vendor" branch. Do not, under any circumstances, attempt to upgrade
the files in this directory via patches and a cvs commit.
To upgrade to a newer version of groff, when it is available:
1. Unpack the new version into an empty directory.
[Do not make ANY changes to the files.]
2. Use the command:
cvs import -m 'Virgin import of FSF groff v<version>' \
src/contrib/groff FSF v<version>
For example, to do the import of version 1.19.2, I typed:
cvs import -m 'Virgin import of FSF groff v1.19.2' \
src/contrib/groff FSF v1_19_2
3. Follow the instructions printed out in step 2 to resolve any
conflicts between local FreeBSD changes and the newer version.
Do not, under any circumstances, deviate from this procedure.
To make local changes to groff, simply patch and commit to the main
branch (aka HEAD). Never make local changes on the FSF branch.
All local changes should be submitted to Werner Lemberg <wl@gnu.org> or
Ted Harding <ted.harding@nessie.mcc.ac.uk> for inclusion in the next
vendor release.
ru@FreeBSD.org - 20 October 2005
还有另一种方法来列出需要排除在汇入过程之外的文件, 如果需要排除的文件很多或很复杂, 或者经常要汇入的话, 这种方法会更加实用。 通过在汇入源代码的 vendor 源代码目录中加入 FREEBSD-Xlist, 并在其中逐行列出需要排除的文件名模式, 未来的汇入过程, 便可以通过下列操作来完成:
% tar-XFREEBSD-Xlist-xzfvendor-source.tgz
下面的示范 FREEBSD-Xlist 文件来自 src/contrib/tcsh:
*/BUGS */config/a* */config/bs2000 */config/bsd */config/bsdreno */config/[c-z]* */tests */win32
注意: 不要将 FREEBSD-upgrade 或 FREEBSD-Xlist 在汇入的过程中掺进第三方的源代码。 您应在首次汇入之后手工添加这些文件。
5.2.2 SVN 中的 Vendor 汇入过程
作者 Dag-Erling Smørgrav.这一节介绍了在使用 Subversion 时汇入第三方软件的详细过程。
-
准备源代码目录
如果这是转到 SVN 之后的首次汇入操作, 您应首先将 vendor 代码目录扁平化, 并在主目录中开始创建合并历史。 假如这不是首次汇入, 则可以略过这一步。
在将 CVS 转到 SVN 的过程中, vendor 分支以与主代码树相同的格局引入。 例如, foo 的 vendor 源代码, 会位于 vendor/foo/dist/contrib/foo, 但这不仅没有道理, 而且也很不方便。 我们希望的是将 vendor 源代码直接放在 vendor/foo/dist, 类似这样:
% cd vendor/foo/dist/contrib/foo % svn move $(svn list) ../.. % cd ../.. % svn remove contrib % svn propdel
-Rsvn:mergeinfo % svn commit请注意, propdel 这部分是必要的, 因为从 Subversion 1.5 开始, 在复制或移动目录时, 会自动添加 svn:mergeinfo 到对应的目录上。 在这种用法中, 并不需要保留这些信息, 因为您不会从删除的目录中再合并什么东西过来了。
注意: 您也可以用同样的方法来将 tag 也扁平化。 具体操作过程完全一样。 如果需要这样做, 请将所有的 commit 操作积攒到最后, 一次进行。
检查 dist 目录, 并进行必要的清理工作。 您可能会希望禁用关键词扩展, 因为这对未作修改的 vendor 代码来说是没有必要的。 有些时候, 关键词扩展甚至可能是有害的。
% svn propdel svn:keywords
-R. % svn commit此外, 在汇入新的代码之前, 还需要在目标目录 (主代码目录) 中创建 svn:mergeinfo, 将前一次在 vendor 代码基础上所作的改动标示出来:
% cd head/contrib/foo % svn merge
--record-onlysvn_base/vendor/foo/dist@12345678 . % svn commit此处 svn_base 是您 SVN 代码库的根目录, 例如 svn+ssh://svn.FreeBSD.org/base。
-
汇入新的源代码
准备完整的、 经过清理的 vendor 源代码。 采用 SVN 以后, 我们可以保持完整的发行包, 而不致引起主代码树的膨胀。 导入全部代码, 但只合并用到的那些就可以了。
注意, 您需要将在上次汇入操作之后增加的文件添加进来, 并删除那些原作者在新版中删除的文件。 要完成这项工作, 您需要准备一份内容为 vendor 代码树, 以及一份将要汇入的源代码树中文件的有序列表:
% cd vendor/foo/dist % svn list
-R| grep-v'/$' | sort > ../old % cd ../foo-9.9 % find .-typef | cut-c3- | sort > ../new有了这两个文件, 下列命令就能列出删除的文件了 (那些只在 old 中出现的文件):
% comm
-23../old ../new而下列命令则可以显示新增的文件 (只存在于 new 的文件):
% comm
-13../old ../new总结一下:
% cd vendor/foo/foo-9.9 % tar cf - . | tar xf -
-C../dist % cd ../dist % comm-23../old ../new | xargs svn remove % comm-13../old ../new | xargs svn add警告: 如果新版软件包中有新目录, 最后一个命令会失败。 您必须手工添加这些目录并重新执行那个命令。 类似地, 如果有目录被删掉, 也需要手工干预。
检查新文件上的属性:
-
所有文本文件的 svn:eol-style 都应设为 native。
-
所有二进制文件的 svn:mime-type 都应设为 application/octet-stream, 除非有更合适的多媒体类型。
-
可执行文件的 svn:executable 应设为 *。
-
除此之外, 目录中的文件不应具有任何其他属性。
注意: 现在可以进行 commit 操作了, 但在此之前, 还应再次检查 svn stat 和 svn diff 的输出, 以确保一切正常。
一旦完成了将新的 vendor 版本 commit 到代码库中的操作, 就应立即对其进行 tag, 以便于日后参考。 最佳也是最快的操作方法, 是直接在代码库上进行:
% svn copy svn_base/vendor/foo/dist svn_base/vendor/foo/9.9
要获得新的 tag, 可以在当前 vendor/foo 的工作副本上执行更新 (update) 操作。
注意: 如果您在签出 (checkout) 的版本上执行了复制操作, 不要忘记像前面那样删去 svn:mergeinfo 元数据。
-
-
合并到 -HEAD
准备好汇入之后, 就可以开始合并了。 选项
--accept=postpone会告诉 SVN 暂时不要合并冲突, 因为这将在稍后手工进行:% cd head/contrib/foo % svn update % svn merge
--accept=postponesvn_base/vendor/foo/dist接着解决本地修改与官方修改之间的冲突, 并确保官方版本添加或删除的文件在主代码树中也对应地添加或删除了。 检查与官方版本之间的差异是个好习惯:
% svn diff
--no-diff-deleted--old=svn_base/vendor/foo/dist--new=.选项
--no-diff-deleted的意思是让 SVN 不要检查那些只在官方代码树中出现, 而没有在主代码树中出现的文件。注意: 使用 SVN 时是没有 vendor 分支这样的概念的。 如果某个文件先前有过本地变动, 而现在没有了, 只需简单地删除掉剩余的那些东西, 例如 FreeBSD 版本标记就可以了。 这样一来, 这些文件就不会再出现在与官方代码树之间的差异中。
如果所作的变动需要联编 world 的话, 现在就做 ── 并测试到您确认全部联编通过, 且能够正常运行为止。
-
签入 (commit)
现在可以签入变动了。 请确保一次完成全部工作。 理想状态下, 您应在没有做过任何变动的代码树基础上进行工作, 这样可以直接在树的最顶部执行签入操作。 这种方法能最好地避免出现问题。 如果操作正确, 代码树会从旧代码所构成的一致状态原子地转移到新代码构成的一致状态。
5.3 妨碍性的 (Encumbered) 文件
偶尔可能会需要在 FreeBSD 源代码树上包含某些妨碍性的文件。 例如, 如果某个设备需要首先加载一小段二进制代码才能正常工作, 而我们并没有这些代码的源文件, 则这个二进制文件就被认为是妨碍性的。 在 FreeBSD 源码树上引入这类妨碍性文件时的规则如下。
-
由系统 CPU 解释或执行的任何以非源代码格式保存的文件, 都被认为是妨碍性的。
-
授权限制多于 BSD 或 GNU 的任何文件都是妨碍性的。
-
除非适用 (1) 或 (2) 条款, 包含可以下载到硬件设备的文件并不被认为是妨碍性的。 这些文件必须保存为平台中立的 ASCII 格式 (推荐使用 file2c 或 uuencode 来进行编码)。
-
妨碍性的文件, 在加入到代码库之前, 必须获得 核心小组 的明示批准。
-
妨碍性文件应置于 src/contrib 或 src/sys/contrib。
-
应保持模块的整体性。 除非在非妨碍性代码之间存在代码复用, 否则不应将其割裂开来。
-
预编译的目标文件, 应命名为 体系结构名/文件名.o.uu。
-
内核文件:
-
用户级文件:
5.4 共享库
供稿:浅见 贤、 Peter Wemm 和 David O'Brien. 翻译:CnYouker.如果你想添加共享库支持到一个原来不包含共享库支持的 port 或是其它软件, 共享库的版本号应该遵循如下规则。通常来说,由此得出的数字与软件的发行版本无关。
建立共享库的三个原则是:
-
从1.0开始
-
如果改动与以前版本相兼容,增加副版本号(注意,ELF系统忽略副版本号)。
-
如果是个不兼容的改动,增加主版本号。
例如,添加函数和修正错误导致副版本号增加, 而删除函数、函数调用语法改变等,会迫使主版本号改变。
保持这种形式的版本号:主版本号.副版本号 (x.y)。 我们的 a.out 动态链接器不能很好的处理 x.y.z 形式的版本号。在比较共享库版本号以决定跟哪个库文件链接的时候, 任何y以后的版本号(那是指第三个数字) 总是会被忽略。 如果给定的两个共享库的不同在于“细微”版本 (“micro” revision)的话, ld.so将会与较高修订版本的链接。即,如果你要与 libfoo.so.3.3.3链接,链接器只在(ELF文件的)头部记录 3.3, 并且在连接时,与文件名以 libfoo.so.3.(任何数字 >= 3).(现有的最高数字) 开头的任何文件链接。
注意: ld.so 总是会使用 “副”版本号最高的。例如,即使一个程序最初是(被设定)与 libc.so.2.0链接的, ld.so也会优先选择使用 libc.so.2.2,而不是 libc.so.2.0。
另外,我们的 ELF 动态链接器完全不处理副版本号。 可我们还是应该指定一个主版本号和副版本号,因为我们的 Makefile 会按系统类型“做正确的事”。
对于不属于某个 port 的库文件,我们的原则是在各个 FreeBSD 正式发行版 (RELEASE)之间只改变一次共享库版本号(译者注:一般只是副版本号)。 并且,在 FreeBSD 正式发行版 (RELEASE) 主版本之间(那是指像从 3.x 到 4.x), 也应该仅改变一次共享库主版本号。 当你需要对系统库做一些改变并要增加版本号时, 请查看 Makefile的提交日志。 这是 committer 的责任:确保自(最近的)正式发行版 (RELEASE) 之后只有第一次这样的改动会让在 Makefile 里的共享库版本号更新, 而随后的(在下一个 RELEASE 之前的)改动不会使共享库版本号更新。
第6章 回归与性能测试
翻译:Jokhva.回归测试通常用来检测系统中的特定部分是否如期工作, 并且要确定旧的错误没有重新出现。
FreeBSD 的回归测试工具能够在 FreeBSD 的源代码树 src/tools/regression 中找到。
6.1. 微性能测试列表
这一章包含了一些在 FreeBSD 上或者 FreeBSD 自身做适合的微性能测试的建议。
要在每一次单独的测试的时候使用所有我们给出的建议是不可能的。 但是你用得越多,你测试小差别的能力就会越好。
-
关闭 APM 和任何其他干扰时钟的东西 (ACPI ?)。
-
进入单用户模式。例如,cron(8) 和其他的守护进程只会增加测试的不准确性。sshd(8) 这个守护进程也会造成问题。如果在测试的时候需要 ssh 连接, 那么你或者关闭 SSHv1 的密匙再生功能,或者在测试的时候杀死 sshd 父进程。
-
不要运行 ntpd(8)。
-
如果有 syslog(3) 事件发生,使用一个空白的 /etc/syslogd.conf 运行 syslogd(8), 或者,不要运行它。
-
最小化磁盘 I/O,可能的话,要完全避免。
-
不要挂载不必要的文件系统。
-
可能的话,把 /, /usr, 和其他任何文件挂载为只读。 这样的话可以从 I/O 方面去掉到磁盘的异步更新(等等)。
-
使用 newfs(8) 来生成要测试读写的文件系统。 在每次测试运行前使用 tar(1) 或者 dump(8) 给测试文件系统灌输文件。测试开始前先卸载文件系统, 然后再挂载。这样做的话能得到一个连续的文件系统格局。 对于经典测试,我们要测试的目录是 /usr/obj(用 newfs 重新初始化,然后再挂载)。 要获得 100% 的再现,请使用 dd(1) 产生的文件来灌输文件系统。(也就是: dd if=myimage of=/dev/ad0s1h bs=1m)
-
使用基于 malloc 的或者预先装载的 md(4) 分区。
-
测试的每次单独迭代之间重启系统。 这可以给你一个更连续的状态。
-
从内核中去掉所有不重要的设备驱动。例如,如果测试不需要 USB, 那么就不要把 USB 放到内核中。驱动加载经常会产生延时。
-
不要配置不使用的硬件。如果测试不使用硬盘,使用 atacontrol(8) 和 camcontrol(8) 去掉硬盘。
-
除非必要,否则不要配置网络, 或者等到测试完要把测试结果传输到另一台机器的时候再启动网络。
如果系统必须连接到公共网络,一定要注意广播数据。 即使这些数据很难被注意到,也会占用 CPU 的时钟周期。 组播也有类似的情况。
-
把每一个文件系统放到它自己的硬盘上。 这可以最小化磁盘的磁头搜索优化的抖动。
-
尽量减少把结果输出到串口或 VGA 控制台。 将结果导入文件可以减少震动干扰。 (串口终端很容易变成一个瓶颈。) 在测试的时候不要触碰键盘,甚至space 或 back-space 键也会以数字形式显示出来。
-
确认你的测试足够长, 但不是太长。 如果测试太短, 就无法忽略时间戳的误差影响, 而如果太长, 温度的变化会影响计算机内的石英晶体的频率。 经验值: 多于一分钟, 少于一个小时。
-
尽量保证机器所在环境的温度恒定。 这会同时影响石英晶体和磁盘驱动器的算法。 要得到稳定的时钟,可以考虑使用 稳定时钟注入(stabilized clock injection)。例如,使用 OCXO + PLL, 把测试结果注入时钟电路而不是主板上的xtal。 要了解更多,请联系 Poul-Henning Kamp
<phk@FreeBSD.org>。 -
测试至少要运行三次。但是对于 “测试前” 和 “测试后” 的代码,最好分别都运行二十次以上。 尽可能交错执行测试,这样可以侦测测试环境对测试的影响。 不要 1:1 的交错,要 3:3 的交错, 这样就可以检测人机交互对测试的影响。
好的类型,比如:bababa{bbbaaa}*, 可以在 1+1 的运行后给出一些提示(在测试出错时可以停止测试), 以及在首次 3+3 运行后的标准差(如果测试时间较长可以给出一些), 和测试运行的趋势与稍后一些交互数字。
-
使用 ministat(1) 来查看数字是否具有统计学上的意义。 你可以买一本 “Cartoon guide to statistics” ISBN: 0062731025,高度推荐, 如果你已经忘记或者根本不知道标准差和 Student's T 测试。
-
不要使用后台 fsck(8) 除非你是在对后台 fsck进行 benchmark。同时,在 /etc/rc.conf 中关闭
background_fsck,除非在系统起动后, 你的 benchmark 在 fsck 运行 60+ 秒后仍然没开始。 因为一旦开启了后台 fsck,rc(8) 会把 fsck 唤醒并检查是否要在文件系统上运行之。 类似的,除非你的测试对象包括 snapshots, 就要确定系统中没有任何 snapshots。 -
如果你的 benchmark 有预期之外的性能低下问题, 就要检测有没有来自未知系统资源的高频率中断。 有一些版本的 ACPI 就有 “运行混乱” 的问题,并且会产生过多的中断。 要诊断奇怪的测试结果,可以抓一些 vmstat -i 的片段然后查看是否有不正常的现象。
-
要谨慎对待内核和用户空间的优化参数,对于调试也是这样。 因为很容易就会忽略一些东西, 然后才会意识到测试不能用来比较同样的事情。
-
除非你的测试对内核参数 WITNESS 和 INVARIANTS 有兴趣,否则不要在开启了这些内核参数后进行你的 benchmark。 WITNESS 会导致 400%+ 的性能损失。 类似的,用户态的 malloc(3) 参数在 -CURRENT 版本和生产版本中默认值都是不同的。
第7章 套接字
供稿:G. Adam Stanislav. 翻译:intron@intron.ac.7.1 概述
BSD 套接字(socket)将进程间通信推到一个新的水平。 彼此通信的进程可不再必须运行在同一计算机上。它们仍然还 能够运行在同一计算机上,但不再必须那样。
不仅这些进程不必运行在同一计算机上, 它们也不必运行在同一种操作系统上。 有了 BSD 套接字,你的 FreeBSD 软件能够与运行在 Macintosh®中的程序顺利的协同工作,也可以与另一个在Sun™ 工作站上的,或是另一个运行在 Windows® 2000中的, 只要这些系统用以太网型的局域网相连。
你的软件还可以很好的与运行在另一幢大楼,或是在另一个大陆、 在一艘潜艇中的,或是一架航天飞机中的进程协同工作。
它也能够与并非属于计算机一部分(至少从术语的严格意义上说不是) 的组件协同工作,这种设备像打印机、数码相机、医疗设备, 大致只要是任何能够进行数字通信的东西。
7.2 联网和多样性
我们已经暗示了联网的多样性问题。 许多不同的系统要彼此对话。它们必须说同一种语言。与此同时, 它们也必须理解同一种语言。
人们常常认为肢体语言是通用的。 事实并非如此。回想在我刚刚十几岁时,我的父亲带我去保加利亚。 一次我们正坐在索非亚一座公园里的桌子旁,一个小贩上来向我们 推销烤杏仁。
那时我还没有学习多少保加利亚语,我没有说“不”,而是摇了摇头, 那是“通用的”说不的肢体语言。 小贩很快开始装给我们一些杏仁。
然后我想起我曾被告知在保加利亚摇头表示是。 很快,我又开始上下点头。小贩注意到了,就拿起他的杏仁走开了。 对于一个统一的观察者,我没有改变肢体语言:我继续使用摇头和点头的语言。 被改变的是肢体语言的意义。最初,小贩和我 将同一种语言理解为完全不同的意义。我必须校正我自己对那种语言的了解, 这样小贩才会明白。
对于计算机也是同样的:同样的符号可能会有不同的,乃至 截然相反的意义。所以,为了让两台计算机明白彼此,它们不仅要 对于相同的语言有默契,还必须对这种语言的 理解有默契。
7.3 协议
当各种各样的编程语言动辄有着复杂的语法, 并且使用了许多多字母保留字(这使用它们易于被人类程序员明白); 数据通信的语言则倾向于简洁。它们经常使用一个个 二进制位,而不是多字节单词。 这有一个很令人信服的理由: 数据在你的计算机 内部 可以以光速高速行进, 而在计算机之间传递数据时, 速度却会慢得多。
因为数据通信中使用的语言很简洁,我们通常把它们称为 协议,而不是语言。
当数据从一台计算机行进到另一台时,它一般使用超过一种协议。 这些协议是 分层次的。 数据可以与一头洋葱的芯类比:只有你剥开几层“表皮” 后才可取得数据。这最好用一张图说明:
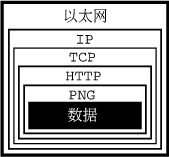
在这个例子中,我们尝试从用以太网连着的网页上获取一幅图像。
图像由原始数据组成,那是一个我们的软件能够处理的(转换为一幅 图片并显示在我们的显示器上)红绿蓝值序列。
唉,我们的软件无法知道原始数据是如何组织的:那是一个 红绿蓝值序列,还是一个灰度序列,或者可能是 CMYK编码的色彩?数据是表现为8位离散值,还是16位大小, 或是4位?图像由多少行和列组织?有的像素应当是透明的吗?
我想你得到了图片……
为了统一我们的软件处理原始数据的方式,数据被编码为 PNG文件。那也可以是 GIF,或JPEG文件, 不一定只是PNG文件。
于是PNG就是一种协议。
对于这一点,我可以听见你的喊声: “不,那不是!那是一种文件格式! ”
好,那当然是一种文件格式。但从数据通信的方面说, 一种文件格式也是一种协议: 文件结构是一种语言,而且还是一种简洁的语言, 与我们的进程通信,确定数据如何被组织。 因此,那是一种协议。
唉,假如我们接收到的只有PNG文件, 我们的软件将要面对一个严峻的问题:将如何知道数据代表一幅图像, 而不是一些文本、或可能是一段声音,或者这些都不是?其次,将如何 知道图像是PNG格式的,而不是 GIF,或是JPEG, 或是其它图像格式?
要取得那些信息,我们使用另一种协议: HTTP。这种协议能告诉我们数据确实代表一幅图像, 并且图像使用PNG协议。它也能告诉我们其它一些东西, 不过还是让我们把注意力停留在协议层次这里吧。
至此,我们有一些数据被包裹在PNG 协议中,而后又被包裹在HTTP协议中。 我们如何从服务器上取得它?
通过在以太网上使用TCP/IP,这就是方法。 实际上,有比三种更多的协议。我不再继续深入了,我现在开始说说以太网, 只因为这样更容易解释其余的问题。
以太网是一种有趣的系统,它将计算机连接在一个 局域网 (local area network,LAN)中。 每台计算机有一个网络接口卡(中文简称“网卡”) (network interface card,NIC)。 每个网卡有一个唯一的48位标识,称为它的 地址。世界上没有两块 网卡会有相同的地址。
这些网卡彼此相连。 一旦一台计算机要与在同一以太网局域网中的另一台计算机 通信时,就在网络上发送一条消息。每个网卡都会看见 这条消息。但是作为以太网协议的一部分, 数据包含目的网卡的地址(还有其它内容)。所以, 在所有网卡中只有一个会注意那条消息,其余的则会忽略。
但并非所有的计算机都被连接在同一网络上。 因为我们在我们的以太网上所接收到的数据并不意味着那一定源自于我们的局域网。 可能有来自其它通过Internet 与我们自己的网络相连的网络的数据来我们面前。
在Internet上传送的所有数据都使用IP。 IP表示网间协议 (Internet Protocol)。它的基本功能是让我们知道 世界上的数据从哪里到来,应该会到哪里去。它并不 保证我们一定会接收到数据, 只保证假如我们接收到数据时会知道它从哪里来。
甚至即使我们接收到数据,IP 也不保证我们会按照其它计算机发送数据段的顺序接收到这些数据段。 举个例子,我们接收到图像的中心部分可能在接收到左上角之前, 又可能在接收到右下角之后。
是TCP (Transmission Control Protocol,传输控制协议) 要求发送方重发丢失的数据,并且把数据都排成正确的顺序。
总结起来,一台计算机与另一台计算机通信一幅图像的样子需要 五个不同的协议。我们接收到的数据被包裹进 PNG协议,这又被包裹进 HTTP协议,而后又被包裹进 TCP协议,再后来又被包裹进 IP协议,最后被包裹进 Ethernet协议。
欧,顺便说一下,可能有几个其它的协议包含在那其中的某个位置。 例如,如果我们的局域网通过电话呼叫接入 Internet,就会在调制解调器上使用PPP协议, 而调制解调器还可能使用一个(或多个)调制解调器协议, 等等,等等,等等……
到现在为止作为一个开发者你应该问: “我应该如何掌握它们全部? ”
你是幸运的,你不必掌握它们全部。 你只要掌握其中的一部分,而不是全部。 尤其你不需要担心物理连接(在我们的情形中是以太网和 可能的PPP等)。你也不需要掌握网间协议, 或是传输控制协议。
换句话说,你不必为从其它计算机接收数据做所有的事情。 好,你又要问要做什么, 事实上就像打开一个文件一样简单。
一旦你收到数据,就需要你指出如何处理。 在我们的情形中,你需要明白HTTP协议和 PNG文件结构。
以此类推,所有联网协议变成一个灰色区域: 并非因为我们不明白它们如何工作,而是因为我们不必关心它们。 套接字接口为我们照管这些灰色区域:

我们只需要明白告诉我们如何理解数据的协议, 而不是如何从其它进程接收数据, 也不是如何向其它进程发送数据。
7.4 套接字模型
BSD套接字构建在基本的UNIX模型上: 一切都是文件。那么,在我们的例子中, 套接字将使我们接收一个HTTP文件, 就这么说。然后我们要负责将 PNG文件从中提取出来。
由于联网的复杂性,我们不能只使用 open系统调用,
或open() C 函数。而是我们需要分几步
“打开”一个套接字。
一旦我们做了这些,我们就能以处理任何文件描述符 的方式处理套接字。我们从它读取 (read),向它写入(write),
建立管道(pipe), 必定还要关闭(close)它。
7.5 重要的套接字函数
FreeBSD提供了与套接字相关的不同函数, “打开”一个套接字我们只需要四个函数。 有时我们只需要两个。
7.5.1 客户端-服务器差异
典型情况中,以套接字为基础的数据通信一端是一个 服务器,另一端是一个客户端。
7.5.1.1 通用元素
7.5.1.1.1 socket
这一个函数在客户端和服务器都要使用:socket(2)。 它是这样被声明的:
int socket(int domain, int type, int protocol);
返回值的类型与open的相同,一个整数。
FreeBSD从和文件句柄相同的池中分配它的值。
这就是允许套接字被以对文件相同的方式处理的原因。
参数domain告诉系统你需要使用什么 协议族。有许多种协议族存在,有些是某些厂商专有的,
其它的都非常通用。协议族的声明在 sys/socket.h中
使用PF_INET是对于 UDP, TCP 和其它
网间协议(IPv4)的情况。
对于参数type有五个定义好的值,也在 sys/socket.h中。这些值都以 “SOCK_”开头。 其中最通用的是SOCK_STREAM, 它告诉系统你正需要一个可靠的流传送服务 (和PF_INET一起使用时是指 TCP)。
如果指定SOCK_DGRAM, 你是在请求无连接报文传送服务
(在我们的情形中是UDP)。
如何你需要处理基层协议 (例如IP),或者甚至是网络接口 (例如,以太网),你就需要指定 SOCK_RAW。
最后,参数protocol取决于前两个参数,
并非总是有意义。在以上情形中,使用取值0。
7.5.1.1.2 sockaddr
各种各样的套接字函数需要指定地址,那是一小块内存空间
(用C语言术语是指向一小块内存空间的指针)。在 sys/socket.h中有各种各样如 struct
sockaddr的声明。 这个结构是这样被声明的:
/*
* 内核用来存储大多数种类地址的结构
*/
struct sockaddr {
unsigned char sa_len; /* 总长度 */
sa_family_t sa_family; /* 地址族 */
char sa_data[14]; /* 地址值,实际可能更长 */
};
#define SOCK_MAXADDRLEN 255 /* 可能的最长的地址长度 */
注意对于sa_data域的定义有些 不确定性。 那只是被定义为14字节的数组, 注释暗示内容可能超过14字节
这种不确定性是经过深思熟虑的。套接字是个非常强大的接口。 多数人可能认为比Internet接口强不到哪里 ──大多数应用现在很可能都用它 ──套接字可被用于几乎任何种类的进程间通信, Internet(更精确的说是IP)只是其中的一种。
sys/socket.h提到的各种类型的协议 将被按照地址族对待,并把它们就列在 sockaddr定义的前面:
/*
* 地址族
*/
#define AF_UNSPEC 0 /* 未指定 */
#define AF_LOCAL 1 /* 本机 (管道,portal) */
#define AF_UNIX AF_LOCAL /* 为了向前兼容 */
#define AF_INET 2 /* 网间协议: UDP, TCP, 等等 */
#define AF_IMPLINK 3 /* arpanet imp 地址 */
#define AF_PUP 4 /* pup 协议: 例如BSP */
#define AF_CHAOS 5 /* MIT CHAOS 协议 */
#define AF_NS 6 /* 施乐(XEROX) NS 协议 */
#define AF_ISO 7 /* ISO 协议 */
#define AF_OSI AF_ISO
#define AF_ECMA 8 /* 欧洲计算机制造商协会 */
#define AF_DATAKIT 9 /* datakit 协议 */
#define AF_CCITT 10 /* CCITT 协议, X.25 等 */
#define AF_SNA 11 /* IBM SNA */
#define AF_DECnet 12 /* DECnet */
#define AF_DLI 13 /* DEC 直接数据链路接口 */
#define AF_LAT 14 /* LAT */
#define AF_HYLINK 15 /* NSC Hyperchannel */
#define AF_APPLETALK 16 /* Apple Talk */
#define AF_ROUTE 17 /* 内部路由协议 */
#define AF_LINK 18 /* 协路层接口 */
#define pseudo_AF_XTP 19 /* eXpress Transfer Protocol (no AF) */
#define AF_COIP 20 /* 面向连接的IP, 又名 ST II */
#define AF_CNT 21 /* Computer Network Technology */
#define pseudo_AF_RTIP 22 /* 用于识别RTIP包 */
#define AF_IPX 23 /* Novell 网间协议 */
#define AF_SIP 24 /* Simple 网间协议 */
#define pseudo_AF_PIP 25 /* 用于识别PIP包 */
#define AF_ISDN 26 /* 综合业务数字网(Integrated Services Digital Network) */
#define AF_E164 AF_ISDN /* CCITT E.164 推荐 */
#define pseudo_AF_KEY 27 /* 内部密钥管理功能 */
#define AF_INET6 28 /* IPv6 */
#define AF_NATM 29 /* 本征ATM访问 */
#define AF_ATM 30 /* ATM */
#define pseudo_AF_HDRCMPLT 31 /* 由BPF使用,就不必在接口输出例程
* 中重写头文件了
*/
#define AF_NETGRAPH 32 /* Netgraph 套接字 */
#define AF_SLOW 33 /* 802.3ad 慢速协议 */
#define AF_SCLUSTER 34 /* Sitara 集群协议 */
#define AF_ARP 35
#define AF_BLUETOOTH 36 /* 蓝牙套接字 */
#define AF_MAX 37
用于指定IP的是 AF_INET。这个符号对应着常量 2。
在sockaddr中的域 sa_family指定地址族, 从而决定预先只确定下大致字节数的 sa_data的实际大小。
特别是当地址族 是AF_INET时,我们可以使用 struct
sockaddr_in,这可在 netinet/in.h中找到,任何需要 sockaddr的地方都以此作为实际替代。
/*
* 套接字地址,Internet风格
*/
struct sockaddr_in {
uint8_t sin_len;
sa_family_t sin_family;
in_port_t sin_port;
struct in_addr sin_addr;
char sin_zero[8];
};
我们可这样描绘它的结构:
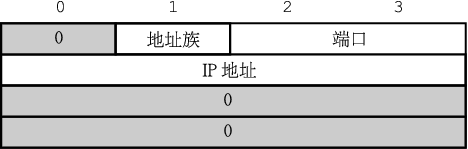
三个重要的域是: sin_family,结构体的字节1; sin_port,16位值,在字节2和3; sin_addr,一个32位整数,表示 IP地址,存储在字节4-7。
现在,让我们尝试填满它。让我们假设我们正在写一个 daytime协议的客户端,这个协议只是简单的规定
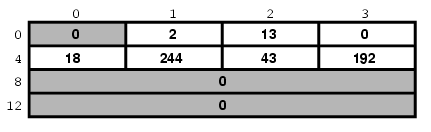
服务器写出一个代表当前日期和时间文本字符串到端口13。 我们需要使用 TCP/IP,所以我们需要指定在地址族域指定 AF_INET。 AF_INET被定义为 2。让我们使用 IP地址192.43.244.18,这指向 美国联邦政府(time.nist.gov)的服务器。

顺便说一下,域sin_addr被声明为类型 struct in_addr,这个类型定义在 netinet/in.h之中:
/*
* Internet 地址 (由历史原因而形成的结构)
*/
struct in_addr {
in_addr_t s_addr;
};
而in_addr_t是一个32位整数。
192.43.244.18 只是为了表示32位整数的方便写法,按每个八位字节列出, 以最高位的字节开始。
到目前为止,我已经看见了sockaddr。
我们的计算机并不将短整数存储为一个16位实体,
而是一个2字节序列。同样的,计算机将32位整数存储为4字节序列。
想象我们这样写程序:
sa.sin_family = AF_INET;
sa.sin_port = 13;
sa.sin_addr.s_addr = (((((192 << 8) | 43) << 8) | 244) << 8) | 18;
结果会是什么样的呢?
好,那当然是要依赖于其它因素的。在Pentium®或其它x86 为基础的计算机上,它会像这样:
在另一个不同的系统上,它可能会是:
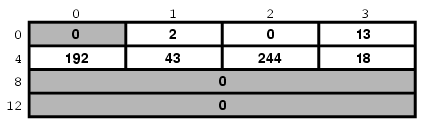
在一台PDP计算机上,它可能又是另一个样子。 不过上面两种情况是今天最常用的了。
译者注: PDP的字节顺序在英语中称为middle-endian或mixed-endian。 例如,原数0x44332211会被PDP存储为0x33441122。 VAX也采用这种字节顺序。
通常,要书写可移植的代码,程序员假设不存在那些差异。 他们回避这种差异(除了他们使用汇编语言写代码的时候)。 唉,可你不能在为套接字写代码时那样轻易的回避这种差异。
为什么?
因为当与另一台计算机通信时, 你通常不知道对方存储数据时是先存放最高位字节 (MSB)还是最低位字节 (LSB)。
你可能会有问题,“那么, 套接字可以为我把握这种差异吗?”
它不能。
这个回答可能先是让你感到惊讶, 请记住通用的套接字接口只明白结构体sockaddr 中的域sa_len和sa_family。 你不必担心那里的字节顺序(当然, 在FreeBSD上sa_family只有一个字节, 但是许多其它的 UNIX 系统没有 sa_len 并使用2字节给
sa_family,
而且数据使用何种顺序都取决于计算机(译者注:此处英文原文的用词为“is native to”))。
其余的数据,也就只剩下sa_data[14]。 依照地址族,套接字只是将那些数据转发到目的地。
事实上,我们输入一个端口号, 是为了让其它计算机知道我们需要什么服务。 并且,当我们提供服务时, 只有读取了端口号我们才知道其它计算机期望从我们这里获得什么服务。 另一方面,套接字只将端口号作为数据转发, 完全不去理会(译者注:此处英文原文用词为“interpret”)其中的内容。
同样的,我们输入IP地址, 告诉途经的每台计算机要将我们的数据发送到哪里。 套接字依然只将其按数据转发。
那就是为什么我们(指程序员, 而不是套接字)不得不把使用在我们的计算机上的 字节顺序和发送给其它计算机时使用的传统字节顺序区分开来。
我们将把我们的计算机上使用的字节顺序称为 主机字节顺序, 或者就是主机顺序.
有一个在IP发送多字节数据的传统: 最高位字节(MSB)优先。 这,我们将用网络字节顺序提及, 或者简单的称为网络顺序。
现在,如果我们在Intel计算机上编译上面的代码, 我们的主机字节顺序将产生:
但是网络字节顺序 要求我们先存储数据的最高位字节(MSB):
不幸的是,我们的主机顺序 恰恰与网络顺序相反。
我们有几种方法解决这个问题。一种是在我们的代码中 倒置数值:
sa.sin_family = AF_INET;
sa.sin_port = 13 << 8;
sa.sin_addr.s_addr = (((((18 << 8) | 244) << 8) | 43) << 8) | 192;
这将欺骗我们的编译器 把数据按网络字节顺序存储。 在一些情形中,这的确是个有效的办法 (例如,用汇编语言编程)。然而,在多数情形中, 这会导致一个问题。
想象一下,你用C语言写了一个套接字程序。 你知道它将运行在一台Pentium计算机上, 于是你倒着输入你的所有常量,并且把它们强置为 网络字节顺序。 它工作正常。
然而,有一台,你所信任的旧 Pentium 变成一台生了锈的旧 Pentium。你把它更换为一个 主机顺序与 网络顺序相同的系统。 你需要重新编译你的所有软件。 你的所有软件中除了你写的那个程序,都继续工作正常。
你早已经忘记你将全部常量强置为与 主机顺序相反。你花费宝贵时间拽头发, 呼唤你曾经听到过的(有些是你编造的)所有上帝的名字, 用击球棍敲打你的显示器, 还上演所有其它的传统仪式 试图找到一个原本好端端的程序突然完成不能工作的原因。
最终,你找到了原因,发了一通誓言, 开始重写你的代码。
幸运的是,你不是第一个面对这个问题的人。 其它人已经创建 htons(3) 和 htonl(3) C
语言函数分别将 short and long
从主机字节顺序转换为 网络字节顺序, 并且还有 ntohs(3) 和 ntohl(3) C
语言函数进行着另外的转换。
在最高位字节(MSB)-最前 的系统上,这些函数什么都不做。在 最低位字节(LSB)-最前的系统上 它们将值转换为正确的顺序。
这样一来,无论你的软件在什么系统上编译, 如果你使用这些函数, 你的数据最终都将是正确的顺序。
7.5.1.2 客户端函数
典型情况中,客户端初始化到服务器的连接。 客户端知道要呼叫哪台服务器: 它知道服务器的IP地址,并且知道服务器驻守的 端口。这就好比你拿起电话拨号码 (地址),然后,有人应答, 呼叫负责狂欢的人 (端口)。
7.5.1.2.1 connect
一旦一个客户端已经建立了一个套接字, 就需要把它连接到一个远方系统的一个端口上。这使用 connect(2):
int connect(int s, const struct sockaddr *name, socklen_t namelen);
参数 s 是套接字, 那是由函数socket返回的值。 name 是一个指向
sockaddr的指针,这个结构体我们已经展开讨论过了。 最后,namelen通知系统 在我们的sockaddr结构体中有多少字节。
如果 connect 成功, 返回 0。否则返回 -1 并将错误码存放于
errno之中。
有许多种connect可能失败的原因。
例如,试图发起一个Internet连接时, IP
地址可能不存在,或可能停机, 或者就是太忙,或者可能没有在指定端口上有服务器监听。
或者直接拒绝任何特定代码的请求。
7.5.1.2.2 我们的第一个客户端
现在我们知道足够多去写一个非常简单的客户端, 一个从192.43.244.18获取当前时间并打印到 stdout的程序。
/*
* daytime.c
*
* G. Adam Stanislav 编程
*/
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main() {
register int s;
register int bytes;
struct sockaddr_in sa;
char buffer[BUFSIZ+1];
if ((s = socket(PF_INET, SOCK_STREAM, 0)) < 0) {
perror("socket");
return 1;
}
bzero(&sa, sizeof sa);
sa.sin_family = AF_INET;
sa.sin_port = htons(13);
sa.sin_addr.s_addr = htonl((((((192 << 8) | 43) << 8) | 244) << 8) | 18);
if (connect(s, (struct sockaddr *)&sa, sizeof sa) < 0) {
perror("connect");
close(s);
return 2;
}
while ((bytes = read(s, buffer, BUFSIZ)) > 0)
write(1, buffer, bytes);
close(s);
return 0;
}
继续,把它输入到你的编辑器中,保存为 daytime.c,然后编译并运行:
% cc -O3 -o daytime daytime.c % ./daytime 52079 01-06-19 02:29:25 50 0 1 543.9 UTC(NIST) * %
在这一情形中,日期是2001年6月19日,时间是 02:29:25 UTC。你的结果会很自然的变化。
7.5.1.3 服务器函数
典型的服务器不初始化连接。 相反,服务器等待客户端呼叫并请求服务。 服务器不知道客户端什么时候会呼叫, 也不知道有多少客户端会呼叫。服务器就是这样静坐在那儿, 耐心等待,一会儿,又一会儿, 它突然发觉自身被从许多客户端来的请求围困, 所有的呼叫都同时来到。
套接字接口提供三个基本的函数处理这种情况。
7.5.1.3.1 bind
端口像是电话线分机:在你拨一个号码后, 你拨分机到一个特定的人或部门。
有65535个 IP 端口, 但是一台服务器通常只处理从其中一个端口进入的请求。 这就像告诉电话室操作员我们处于工作状态并在一个特定分机应答电话。 我们使用 bind(2) 告诉套接字我们要服务的端口。
int bind(int s, const struct sockaddr *addr, socklen_t addrlen);
除了在 addr 中指定端口, 服务器还可以包含其自身的
IP 地址。不过,也可以就使用符号常量 INADDR_ANY,指示服务于无论哪个 IP上的指定端口上的请求。 这个符号和几个相同的常量,声明在 netinet/in.h之中。
#define INADDR_ANY (u_int32_t)0x00000000
想象我们正在为 daytime协议在
TCP/IP的基础上写一个服务器。 回想起使用端口13。我们的sockaddr_in 结构应当像这样:
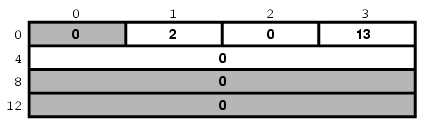
7.5.1.3.2 listen
继续我们的办公室电话类比, 在你告诉电话中心操作员你会在哪个分机后, 现在你走进你的办公室,确认你自己的电话已插上并且振铃已被打开。 还有,你确认呼叫等待功能开启,这样即使你正在与其它人通话, 也可听见电话振铃。
服务器执守所有经过函数 listen(2) 操作的套接字。
int listen(int s, int backlog);
在这里,变量backlog
告诉套接字在忙于处理上一个请求时还可以接受多少个进入的请求。
换句话说,这决定了挂起连接的队列的最大大小。
7.5.1.3.3 accept
在你听见电话铃响后,你应答呼叫接起电话。 现在你已经建立起一个与你的客户的连接。 这个连接保持到你或你的客户挂线。
服务器通过使用函数 accept(2) 接受连接。
int accept(int s, struct sockaddr *addr, socklen_t *addrlen);
注意,这次 addrlen 是一个指针。
这是必要的,因为在此情形中套接字要 填上 addr,这是一个 sockaddr_in 结构体。
返回值是一个整数。其实, accept 返回一个 新
套接字。你将使用这个新套接字与客户通信。
老套接字会发生什么呢?它继续监听更多的请求 (想起我们传给listen的变量 backlog了吗?),直到我们 close(关闭)
它。
现在,新套接字仅对通信有意义,是完全接通的。 我们不能再把它传给 listen接受更多的连接。
7.5.1.3.4 我们的第一个服务器
我们的第一个服务器会比我们的第一个客户端复杂一些: 我们不仅用到了更多的套接字函数, 还需要把程序写成一个守护程序。
这最好写成:在绑定端口后建立一个子进程。 主进程随后退出,将控制权交回给 shell (或者任何调用主进程的程序)。
子进程调用 listen,
然后启动一个无休止循环。这个循环接受连接,提供服务, 最后关闭连接的套接字。
/*
* daytimed - 端口 13 的服务器
*
* G. Adam Stanislav 编程
* 2001年6月19日
*/
#include <stdio.h>
#include <string.h>
#include <time.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#define BACKLOG 4
int main() {
register int s, c;
int b;
struct sockaddr_in sa;
time_t t;
struct tm *tm;
FILE *client;
if ((s = socket(PF_INET, SOCK_STREAM, 0)) < 0) {
perror("socket");
return 1;
}
bzero(&sa, sizeof sa);
sa.sin_family = AF_INET;
sa.sin_port = htons(13);
if (INADDR_ANY)
sa.sin_addr.s_addr = htonl(INADDR_ANY);
if (bind(s, (struct sockaddr *)&sa, sizeof sa) < 0) {
perror("bind");
return 2;
}
switch (fork()) {
case -1:
perror("fork");
return 3;
break;
default:
close(s);
return 0;
break;
case 0:
break;
}
listen(s, BACKLOG);
for (;;) {
b = sizeof sa;
if ((c = accept(s, (struct sockaddr *)&sa, &b)) < 0) {
perror("daytimed accept");
return 4;
}
if ((client = fdopen(c, "w")) == NULL) {
perror("daytimed fdopen");
return 5;
}
if ((t = time(NULL)) < 0) {
perror("daytimed time");
return 6;
}
tm = gmtime(&t);
fprintf(client, "%.4i-%.2i-%.2iT%.2i:%.2i:%.2iZ\n",
tm->tm_year + 1900,
tm->tm_mon + 1,
tm->tm_mday,
tm->tm_hour,
tm->tm_min,
tm->tm_sec);
fclose(client);
}
}
我们开始于建立一个套接字。然后我们填好 sockaddr_in
类型的结构体 sa。注意, INADDR_ANY的特定使用方法:
if (INADDR_ANY)
sa.sin_addr.s_addr = htonl(INADDR_ANY);
这个常量的值是0。由于我们已经使用 bzero于整个结构体, 再把成员设为0将是冗余。 但是如果我们把代码移植到其它一些 INADDR_ANY可能不是0的系统上, 我们就需要把实际值指定给 sa.sin_addr.s_addr。多数现在C语言 编译器已足够智能,会注意到 INADDR_ANY是一个常量。由于它是0,
他们将会优化那段代码外的整个条件语句。
在我们成功调用bind后, 我们已经准备好成为一个 守护进程:我们使用 fork建立一个子进程。 同在父进程和子进程里,变量s都是套接字。 父进程不再需要它,于是调用了close, 然后返回0通知父进程的父进程成功终止。
此时,子进程继续在后台工作。 它调用listen并设置
backlog 为 4。这里并不需要设置一个很大的值, 因为 daytime 不是个总有许多客户请求的协议,
并且总可以立即处理每个请求。
最后,守护进程开始无休止循环,按照如下步骤:
-
调用
accept。 在这里等待直到一个客户端与之联系。在这里, 接收一个新套接字,c, 用来与其特定的客户通信。 -
使用 C 语言函数
fdopen把套接字从一个 低级 文件描述符 转变成一个 C语言风格的FILE指针。 这使得后面可以使用fprintf。 -
检查时间,按 ISO 8601格式打印到 “文件”
client。 然后使用fclose关闭文件。 这会把套接字一同自动关闭。
我们可把这些步骤 概括 起来, 作为模型用于许多其它服务器:
这个流程图很好的描述了顺序服务器, 那是在某一时刻只能服务一个客户的服务器, 就像我们的daytime服务器能做的那样。 这只能存在于客户端与服务器没有真正的“对话”的时候: 服务器一检测到一个与客户的连接,就送出一些数据并关闭连接。 整个操作只花费若干纳秒就完成了。
这张流程图的好处是,除了在父进程 fork之后和父进程退出前的短暂时间内, 一直只有一个进程活跃:
我们的服务器不占用许多内存和其它系统资源。
注意我们已经将初始化守护进程
加入到我们的流程图中。我们不需要初始化我们自己的守护进程
(译者注:这里仅指上面的示例程序。一般写程序时都是需要的。), 但这是在程序流程中设置signal 处理程序、 打开我们可能需要的文件等操作的好地方。
几乎流程图中的所有部分都可以用于描述许多不同的服务器。 条目 serve 是个例外,我们考虑为一个 “黑盒子”, 那是你要为你自己的服务器专门设计的东西, 并且 “接到其余部分上”。
并非所有协议都那么简单。许多协议收到一个来自客户的请求, 回复请求,然后接收下一个来自同一客户的请求。 因此,那些协议不知道将要服务客户多长时间。 这些服务器通常为每个客户启动一个新进程 当新进程服务它的客户时, 守护进程可以继续监听更多的连接。
现在,继续,保存上面的源代码为 daytimed.c (用字母d 结束守护程序名是个风俗)。在你编译好后,尝试运行:
% ./daytimed bind: Permission denied %
这里发生了什么?正如你将回想起的, daytime协议使用端口13。 但是所有1024以下的端口保留给超级用户 (否则,任何人都可以启动一个守护进程伪装一个常用端口的服务, 这就导致了一个安全漏洞)。
再试一次,这次以超级用户的身份:
# ./daytimed #
怎么……什么都没有?让我们再试一次:
# ./daytimed bind: Address already in use #
在一个时刻,每个端口只能被一个程序绑定。 我们的第一个尝试真的成功了:启动了守护子进程并安静的返回。 守护子进程仍然在运行,并且继续运行到你关闭它, 或是它使用的系统调用失败,或是你重启计算机时。
好,我们知道它正在后台运行着。 但是它正在正常工作吗?我们如何知道它是个正常的 daytime 服务器?只需简单的:
% telnet localhost 13 Trying ::1... telnet: connect to address ::1: Connection refused Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. 2001-06-19T21:04:42Z Connection closed by foreign host. %
telnet 尝试新协议 IPv6,失败了。又重新尝试 IPv4,而后成功了。守护进程工作正常。
如果你可以通过telnet 访问另一个 UNIX 系统,你可以用测试远程访问服务器。 我们计算机没有静态 IP 地址, 所以我这样做:
% who whizkid ttyp0 Jun 19 16:59 (216.127.220.143) xxx ttyp1 Jun 19 16:06 (xx.xx.xx.xx) % telnet 216.127.220.143 13 Trying 216.127.220.143... Connected to r47.bfm.org. Escape character is '^]'. 2001-06-19T21:31:11Z Connection closed by foreign host. %
又工作正常了。使用域名还会工作正常吗?
% telnet r47.bfm.org 13 Trying 216.127.220.143... Connected to r47.bfm.org. Escape character is '^]'. 2001-06-19T21:31:40Z Connection closed by foreign host. %
顺序说一句,telnet
在我们的守护进程关闭套接字之后打印消息 Connection closed by foreign host
(连接被外部主机关闭)。这告诉我们,实际上,在我们的代码中使用 fclose(client); 的工作情况就像前面说的一样。
7.6 辅助函数
FreeBSD C 语言库包含了许多套接字编程的辅助函数。 例如,在样例客户端中,我们硬性指定了 time.nist.gov 的IP地址。但是我们并非总是知道 IP地址。甚至即使我们知道, 允许用户输入IP地址甚至域名 将使用我们的软件更有弹性。
7.6.1 gethostbyname
域名是不能直接传送给任何套接字函数的, FreeBSD C 语言库携带了函数 gethostbyname(3)和gethostbyname2(3), 声明在netdb.h中。
struct hostent * gethostbyname(const char *name); struct hostent * gethostbyname2(const char *name, int af);
这两个函数都返回hostent结构指针,
内含有关域的许多信息。对于我们的情况,结构体中的域 h_addr_list[0]指向长度 h_length字节的地址, 也按网络字节顺序存储。
这允许我们建立一个要有弹性得多的──也要有用得多的 ──版本的daytime程序:
/*
* daytime.c
*
* G. Adam Stanislav 编程
* 2001年6月19日
*/
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
int main(int argc, char *argv[]) {
register int s;
register int bytes;
struct sockaddr_in sa;
struct hostent *he;
char buf[BUFSIZ+1];
char *host;
if ((s = socket(PF_INET, SOCK_STREAM, 0)) < 0) {
perror("socket");
return 1;
}
bzero(&sa, sizeof sa);
sa.sin_family = AF_INET;
sa.sin_port = htons(13);
host = (argc > 1) ? (char *)argv[1] : "time.nist.gov";
if ((he = gethostbyname(host)) == NULL) {
herror(host);
return 2;
}
bcopy(he->h_addr_list[0],&sa.sin_addr, he->h_length);
if (connect(s, (struct sockaddr *)&sa, sizeof sa) < 0) {
perror("connect");
return 3;
}
while ((bytes = read(s, buf, BUFSIZ)) > 0)
write(1, buf, bytes);
close(s);
return 0;
}
现在我们可以在命令行打一个域名(或者一个IP地址, 两种方式都可以),程序将尝试连接daytime服务器。 否则,将仍然缺省为time.nist.gov。然后, 即使在使用缺省值的情形中我们将使用gethostbyname 而不是硬性指定192.43.244.18。这样,即使将来 IP地址变更,我们也能找到。
由于从我们的本地计算机获取时间几乎不需要时间, 你可以一并运行daytime两次: 第一次从time.nist.gov取得时间, 第二次从你自己的系统取得时间。然后你可以比较结果, 看看你的系统时钟到底怎么样:
% daytime ; daytime localhost 52080 01-06-20 04:02:33 50 0 0 390.2 UTC(NIST) * 2001-06-20T04:02:35Z %
正如你看见的,我的系统比NIST时间快两秒钟。
7.6.2 getservbyname
有时你不能确定某种服务该用什么端口。 函数getservbyname(3),也声明在 netdb.h中,此时就很上手:
struct servent * getservbyname(const char *name, const char *proto);
结构体servent包含 s_port,这是正确的端口号, 已经按照网络字节顺序存储。
假如我们不知道daytime服务的正确端口, 我们可以这样找到:
struct servent *se;
...
if ((se = getservbyname("daytime", "tcp")) == NULL {
fprintf(stderr, "Cannot determine which port to use.\n");
return 7;
}
sa.sin_port = se->s_port;
你通常知道端口。但是如何你正开发一个新协议, 你可能正在一个非正式端口上测试。
有一天,你要注册那个协议和端口 (如果不在别处,至少要在你的 /etc/services里,那是 getservbyname查找的地方)。
上面的代码就不再会返回错误,你就可以使用临时端口号。 一旦你已经将协议列入/etc/services, 你的软件不必重写代码也可以找到端口。
7.7 并发服务器
不同于顺序服务器,并发服务器 就要能在一个时间为多个客户端提供服务。 例如,一个聊天服务器可能服务一个特定的客户端数小时 ──在停止为这个客户端服务之前服务器不能等待, 除非是在等待一下个客户端到来之前的间隙才能等待。
这需要在我们的流程图中做一个重要的更改:
我们将提供服务从 守护进程移至它自己的服务进程。
然而,因为每个子进程都继承所有打开的文件(套接字被像文件一样处理), 新进程不仅继承“accept()返回的句柄,” 那是指调用accept返回的套接字;新进程也继承 顶级套接字,这是顶级进程一开始打开的套接字。
然而,服务进程不需要这个套接字, 应该立即关闭(close)它。同样的, 守护进程不再需要 accept()返回的套接字, 不仅应该,还必须 关闭(close)它──否则,
那迟早会耗尽可用的文件描述符。
在服务进程完成服务之后,
它将关闭accept()返回的套接字。
它不会返回到accept,而是退出进程。
在UNIX上,一个进程并不真正的退出, 而是返回至父进程。典型情况中, 父进程等待(wait)子进程, 并取得一个返回值。但是,我们的守护进程
不能简单的停止或等待,那有违建立其它进程的整个目的。 但是如果从不使用wait, 它的子进程可能会成为僵尸── 不再有功用可仍然徘徊着。
出于那样的原因,守护进程
需要在初始化守护进程阶段设置 信号处理程序。 至少要处理信号SIGCHLD,
这样守护进程可以从系统清除僵尸返回值并释放僵尸占用的系统资源。
这是现在我们的流程图包含一个进程信号框的原因,
它不与任何其它框相连接。顺便说一句,许多服务器程序也处理SIGHUP, 作为超级用户发出的要求重读配置文件的信号。
这允许我们不必终止或重启服务器程序就改变设置。
第8章 IPv6内部
8.1 IPv6/IPsec的实现
供稿:井上 良信. 翻译:intron@intron.ac.本节解释IPv6和IPsec相关的实现内部。 这些功能衍生于 KAME 工程。
8.1.1 IPv6
8.1.1.1 一致性
IPv6 相关的函数与最新的 IPv6 规格一致或努力保持一致。 为了以后的引用,我们将一些相关文档列在下面 (注释: 这不是一个完整的清单 ── 那将太难于维护……)。
详细信息请参考文档中的特定章节、 RFC、手册页或源代码中的注释。
一致性测试由TAHI工程的KAME STABLE kit进行。 结果可在 http://www.tahi.org/report/KAME/查看。 过去我们也用快照参加新罕布什尔大学互操作性实验室(Univ. of New Hampshire IOL) (http://www.iol.unh.edu/)的测试。
-
RFC1639: 大地址记录上的FTP操作 (FOOBAR)
-
RFC2428比RFC1639更受欢迎。FTP客户端将 先尝试RFC2428,如果失败了才尝试RFC1639。
-
-
RFC1886: 支持IPv6的DNS扩展
-
RFC1933: IPv6主机和路由器的过渡机制
-
RFC1981: IPv6的路径最大传输单元的发现
-
RFC2080: IPv6的RIPng
-
usr.sbin/route6d支持此功能。
-
-
RFC2292: IPv6的高级套接字应用程序接口(API)
-
对于已被支持的库函数/内核API,参见 sys/netinet6/ADVAPI。
-
-
RFC2362: 协议无关的组播稀疏模式(Protocol Independent Multicast-Sparse Mode, PIM-SM)
-
RFC2362定义PIM-SM的包格式 draft-ietf-pim-ipv6-01.txt据此写成。
-
-
RFC2373: IPv6寻址结构
-
支持结点要求的地址,与作用域要求一致。
-
-
RFC2374: 一种IPv6可聚合全局单播地址格式
-
支持接口标识的64位长度。
-
-
RFC2375: IPv6组播地址分派
-
用户程序使用的众所周知的地址就被在此RFC中分派。
-
-
RFC2428: IPv6和NAT的FTP扩展
-
RFC2428比RFC1639更受欢迎。FTP客户端会先尝试RFC2428, 如果失败了再尝试RFC1639。
-
-
RFC2460: IPv6规格
-
RFC2461: IPv6的邻居发现
-
详细情况请参见本文档23.5.1.2节。
-
-
RFC2462: IPv6无状态地址自动配置
-
详细情况请参见本文档23.5.1.4节。
-
-
RFC2463: IPv6的ICMPv6规格
-
详细情况请参见本文档23.5.1.9节。
-
-
RFC2464: 以太网上IPv6包的传输
-
RFC2465: IPv6的MIB:正文惯例和通用群
-
必要的统计由内核收集。实际的 IPv6 MIB支持以一个补丁包提供给ucd-snmp。
-
-
RFC2466: IPv6的MIB:ICMPv6群
-
必要的统计由内核收集。实际的 IPv6 MIB支持以一个补丁包提供给ucd-snmp。
-
-
RFC2467: 在FDDI网络上IPv6包的传输
-
RFC2497: 在ARCnet网络上IPv6包的传输
-
RFC2553: IPv6的基本套接字接口扩展
-
IPv4映射地址(3.7)和IPv6通配绑定套接字(3.8)的特殊行为都被支持 详细情况请参见本文档的23.5.1.12节。
-
-
RFC2675: IPv6特大报文
-
详细情况请参见本文档的23.5.1.7节。
-
-
RFC2710: IPv6的组播监听者发现
-
RFC2711: IPv6路由器警报选项
-
draft-ietf-ipngwg-router-renum-08: IPv6 的路由器重编号
-
draft-ietf-ipngwg-icmp-namelookups-02: 通过ICMP的IPv6名字查找
-
draft-ietf-ipngwg-icmp-name-lookups-03: 通过ICMP的IPv6名字查找
-
draft-ietf-pim-ipv6-01.txt: IPv6的PIM
-
draft-itojun-ipv6-tcp-to-anycast-00: 关闭向着IPv6任意传播类型(译者注:指单播、组播之类)地址的TCP连接
-
draft-yamamoto-wideipv6-comm-model-00
-
详细情况请参见本文档的23.5.1.6节。
-
-
draft-ietf-ipngwg-scopedaddr-format-00.txt : IPv6作用域地址格式的一种扩展
8.1.1.2 近邻发现
近邻发现是相当稳定的。当前,地址解析(Address Resolution)、 重复地址侦测(Duplicated Address Detection), 以及近邻不可到达侦测(Neighbor Unreachability Detection)都得到了支持。 在不久的将来,我们将在内核中加入代理近邻公告(Proxy Neighbor Advertisement)支持,并加入自发近邻公告(Unsolicited Neighbor Advertisement)传输命令管理工具。
如果DAD(重复地址侦测)失败,地址将被标记为“重复”, 会有消息产生至syslog中(并且通常会在控制台上有显示)。 “重复”标记可用ifconfig(8)检查。 检查出DAD失败并从失败中恢复是管理员的职责。 这样的行为应该在不久的将来得到改进。
一些网络驱动器将组播包回环至其自身, 即使已被命令不要这样(尤其在混杂模式)。 在这样DAD可能失败的情况中,DAD引擎可以看见进入的NS包 (实际是从结点自身)并且考虑为表明重复的标志。 你可能需要在查看位于sys/netinet6/nd6_nbr.c:nd6_dad_timer()中 被标记为“heuristics”(试探性的)的#if条件作为这种问题的解释。 (注意在“heuristics”节中的代码片段不与规格一致)。
近邻发现(Neighbor Discovery)规格书(RFC2461)没有谈及 在如下情形中的近邻缓存处理:
-
在没有近邻缓存条目时 结点自发的 RS/NS/NA/重定向 包, 不含数据链路层地址
-
介质上的近邻缓存处理,不含数据链路层地址 (我们一个近邻缓存条目给IsRouter位)
对于第一种情形,我们在IETF ipngwg信件列表讨论的基础上实际解决方法。 更多详细情况请参见源代码中的注释和从(IPng 7155,日期1999年2月6日) 开始的信件线索。
IPv6的链路上决定规则(RFC2461)与BSD网络代码的假定有很大不同。 在这时,缺省路同器清单为空时,没有链路上决定规则得到支持 (RFC2461,第5.2节,第2段最后一句 ── 注意规格书这一节中有几处错用 词语“host”(主机)和“node”(结点))。
为避免可能的DoS攻击和无限循环,现在只有ND包中的10个选项被接受。 所以,如果你有20个前缀选项附在RA中,只有前10个前缀会被辨认。 如果这使你遇到麻烦,请在FREEBSD-CURRENT信件列表询问, 和/或修改sys/netinet6/nd6.c中的nd6_maxndop。 如果有大的需求,我们可以为这个变量提供sysctl开关。
8.1.1.3 作用域索引
IPv6使用有作用域的地址。所以对IPv6地址指定作用域索引是非常重要的 (对于链路-本地地址,为接口索引;对于站点-本地地址,为站点索引)。 没有作用域索引,有作用域的IPv6地址对于内核是意义不明确的。 内核将无法确定一个包的向外接口。
普通用户级应用程序应当使用高级应用程序接口(API) (RFC2292)来指定作用域索引,或接口索引。与此目的相同的结构体 sockaddr_in6的成员sin6_scope_id被定义在 RFC2553。然而,sin6_scope_id的语义相当含糊。 如果你要照顾到你的应用程序的移植性, 我们建议你使用高级应用程序接口,而不是sin6_scope_id。
在内核中,一个链路-本地有作用域地址的接口索引被嵌入到 IPv6地址中的第2个16位字(第3、4字节)。 例如,你可以看见
fe80:1::200:f8ff:fe01:6317
位于路由表和接口地址结构体(struct in6_ifaddr)之中。上面的地址是一个链路-本地单播地址, 属于接口标识为1的网络接口。 被嵌入的索引允许我们有效的鉴别在多个接口上的链路-本地地址, 仅凭一点小的代码改动。
路由守护程序和配置程序,像 route6d(8) 和 ifconfig(8),将需要使用“被嵌入的”作用域索引。 这些程序使用路由套接字和ioctl(像 SIOCGIFADDR_IN6),内核应用程序接口将返回填入了第2个16位字的IPv6地址。 应用程序接口用来使用内核内部结构体。 总之,使用这些应用程序接口的程序应被准备好应付各种内核的差异。
当你在命令行指定有作用域地址时,绝不要 写成嵌入形式(例如ff02:1::1或fe80:2::fedc)。这恐怕不行。 请一直使用标准形式,像ff02::1或 fe80::fedc,带上指定接口的命令行选项(像 ping6 -I ne0 ff02::1)。通常, 如果一条命令里没有带上指定外发接口的命令行选项, 那条命令就没有准确接受有作用域地址。 这似乎有悖于IPv6支持“牙科医生办公室”况状的承诺。 我们认为规格书需要对此的改进。
用户级工具中有一些支持扩展数字IPv6语法, 就像记述于文档 draft-ietf-ipngwg-scopedaddr-format-00.txt中的。 你能指定向外的链路,通过使用像“fe80::1%ne0”的外发接口名。 用这种方法你将没有多少麻烦就能指定链路-本地有作用域地址。
为了在你的程序中使用这个扩展,你需要使用 getaddrinfo(3),并使用getnameinfo(3)与NI_WITHSCOPEID。 这些实现目前假定一个链路和一个接口的1对1的关系, 这比规格书说的更强。
8.1.1.4 即插即用
无状态地址自动配置大部分被实现在内核中。 近邻发现函数被实现在内核中,并与内核成为一个整体。 主机的路由器公告(Router Advertisement, RA)输入被实现在内核中。 末端主机的路由器请求(Router Solicitation, RS)输出、 路由器的RS输入和路由器的RA输出被实现在用户级。
8.1.1.4.1 链路-本地和特殊地址的指定
IPv6链路-本地地址生成自IEEE802地址 (以太网MAC地址)。当接口启用时(IFF_UP),每个接口被自动指定一个IPv6 链路-本地地址。并且链路-本地地址的直接路由被加入到路由表中。
这里是netstat命令的输出:
Internet6: Destination Gateway Flags Netif Expire fe80:1::%ed0/64 link#1 UC ed0 fe80:2::%ep0/64 link#2 UC ep0
只要有可能,没有IEEE802地址的接口(伪接口, 像隧道接口,或PPP接口)会从其它接口借用IEEE802地址, 例如以太网地址。如果没有IEEE802硬件相连, 一个最近得到的伪随机值,MD5(hostname), 会被用来作为链路-本地地址的来源。如果这对你不适用, 你就需要手工配置链路-本地地址。
如果一个接口不能处理IPv6(例如缺少组播支持), 链路-本地地址就不会被指定到那个接口。详情参考第2节。
每个接口将请求得到的组播地址和链路-本地全结点组播地址 (例如分别是fe80::1:ff01:6317和ff02::1,在接口相连的链路上)。 除了一个链路-本地地址,回环地址(::1)也会被指定给回环接口。 同时,::1/128和ff01::/32被自动的加入到路由表, 回环接口连接结点-本地组播群ff01::1。
8.1.1.4.2 主机上的无状态地址自动配置
在IPv6规格中,结点被分为两类: 路由器和主机。 路由器转发包至其它结点,主机不转发包。 net.inet6.ip6.forwarding定义这个结点是路由器还是主机 (如果是1则为路由器,如果是0则为主机)。
当一台主机监听到来自路由器的路由器公告时, 主机可以自行无状态地址自动配置。 这种行为由net.inet6.ip6.accept_rtadv控制 (如果设为1主机就自动配置自己)。通过自动配置, 接收接口的网络地址前缀 (通常为全局地址前缀)被添加。缺省路由也被配置。 路由器周期性的产生路由器公告包。 为了要求一个相连路由器产生RA包, 主机可以发送路由器请求。 使用rtsol命令在任何时刻产生路由器请求包。 守护程序rtsold(8)也是可用的。 rtsold(8)在任何必要的时候产生路由器请求, 这在移动使用时(笔记本/膝上型计算机)工作的很好。 如果希望忽略路由器公告,使用sysctl设置 net.inet6.ip6.accept_rtadv为0。
使用守护程序rtadvd(8)产生路由器公告。
注意,IPv6规格假定如下几条成立, 不一致的情形不被规定:
-
只有主机会监听路由器公告
-
主机只有一个网络接口(除了回环)
所以,在路由器或多接口主机上使能net.inet6.ip6.accept_rtadv是不明智的。 一个被错误配置的结点可能行为古怪 (不一致的配置为那些要做某些实验的人们而被允许)。
总结sysctl开关:
accept_rtadv 转发 结点的角色
--- --- ---
0 0 主机 (待手工配置)
0 1 路由器
1 0 被自动配置的主机
(规格假定主机只有一个接口,
有多个接口的自动配置的主机
在作用域外)
1 1 非法,或实验性的
(规格中的“作用域外”)
RFC2462有针对输入路由器公告前缀信息选项的合法性规则, 位于 5.5.3 (e)。这是为了保护主机免受恶意的 (或被错误配置的)以很短的前缀周期公告的路由器的侵害。 有一个来自Jim Bound发给ipngwg信件列表 (在该文档中查找“(ipng 6712)”)的更新, 这些合法性规则在Jim的更新中被实现。
参看本文档23.5.1.2 对DAD(重复地址侦测)和自动配置的关系的描述。
8.1.1.5 通用隧道接口
GIF(通用接口, Generic InterFace)是用于可配置隧道的虚接口。 详细情况被描述在gif(4)。目前有
-
v6 包裹于 v6
-
v6 包裹于 v4
-
v4 包裹于 v6
-
v4 包裹于 v4
可用。使用gifconfig(8)指派物理(外部)源和目的地址给GIF接口。 source and destination address to gif interfaces. Configuration that 对内部和外部IP头部(v4包裹于v4,或v6包裹于v6)使用相同地址族的配置是危险的。 这很容易将接口和路由表配置为无限级隧道。 请警惕。
GIF可被配置为与ECN匹配。参看23.5.4.5中隧道的ECN匹配问题, 以及gif(4)中的配置方法。
如果你要用GIF接口配置一个IPv4-in-IPv6隧道, 请仔细阅读gif(4)。你将需要自动删除指派给GIF接口的链路-本地IPv6地址。
8.1.1.6 源地址选择
当前源选择规则是面向作用域的(有一些例外──见下文)。 对于一个给定的目的,一个源IPv6地址被按如下规则选择:
-
如果源地址显式的由用户指定 (例如,通过高级API),则使用被指定地址。
-
如果有一个地址被指派给与目的地址有着相同作用域的外发接口 (常常通过查找路由表决定),则使用这个被指派的地址。
这是最典型的情形。
-
如果没有地址满足上述条件, 选择一个指派给发送结点上的一个接口的全局地址。
-
如果没有地址满足上述条件, 并目的地址有着站点-本地作用域, 选择一个指派给发送结点上的一个接口的站点-本地地址。
-
如果没有地址满足上述条件, 选择与路由表目的对应入口相关联的地址。
例如,对于ff01::1则::1被选择, 对于fe80:1::2a0:24ff:feab:839b则fe80:1::200:f8ff:fe01:6317选择(注意, 被嵌入的地址索引 ── 描述于23.5.1.3 ── 帮助我们选择正确的源地址。那些被嵌入的索引将不会在线 )。如果外发接口对作用域有多个地址, 地址将会被按最长匹配被选择(规则3)。 假想 2001:0DB8:808:1:200:f8ff:fe01:6317 和 2001:0DB8:9:124:200:f8ff:fe01:6317 被给予外发接口。 2001:0DB8:808:1:200:f8ff:fe01:6317 被选择作为目的 2001:0DB8:800::1 的源。
注意,上述规则并未在IPv6规格书中载明。 而是被考虑为“由实现决定的”条目。有些我们不使用上述规则的情况。 一个例子是已连接的TCP会话, 我们使用保存在传输控制块(TCB)中的地址作为源。 另一个例子是近邻公告(Neighbor Advertisement, NA)的源地址。 在规格书(RFC2461 7.2.2)里NA的源应该是对应的NS目标的目标地址。 在这种情形中,我们依照规格书而不是上述最长匹配规则。
对于新连接(此时规则1不适用),如果有其它选择, 不合适的地址(而是首选 lifetime = 0 的地址)将不被选择为源地址。 如果没有其它选择,不合适的地址将被作为最后的选择。 如果不合适的地址有多个选择, 上述的作用域规则将会被用来从那些不合适的地址中做出选择。 如果你要按照某些理由禁用不合适的地址, 配置net.inet6.ip6.use_deprecated为0。 与不合适的地址相关的话题被描述在 RFC2462 5.5.4 (注意: 对于如何使用“不合适的”地址有一些进行中的争论)。
8.1.1.7 超大有效负载
译者注: 此处英文原文“Jumbo Payload”的原义为“巨大有效负载”。 此处的“有效负载”实指报文承载的用户数据。
超长报文的逐跳(hop-by-hop)选项已被实现,并可用于发送带有长于 65536 个八位字节有效负载的 IPv6 包。但是现在没有物理接口的最大传输单元 (MTU) 大于 65536 个八位字节,所以那样的有效负载只能在回环接口(那是指 lo0)上看见。
如果你需要尝试超长报文,你首先要重新配置内核使得回环接口的 最大传输单元大于 65536 字节;将如下内容添加至内核配置文件:
options "LARGE_LOMTU" # 测试超长报文
并重新编译内核。
然后你可以用命令 ping6(8) 并加 -b 和 -s 选项测试超长报文。 选项 -b 必须被指定以增大套接字缓冲区大小; 选项 -s 指定包的长度,应大小 65535。例如,打如下命令:
% ping6 -b 70000 -s 68000 ::1
IPv6 规格要求超长报文不可用于承载分段头部的包。 如果这个条件被打破,一个 ICMPv6 Parameter Problem (参数问题) 报文 必须被发往发送者。(即使)规格被遵守了, 但是你也可能不会总是看见由那个要求而导致的 ICMPv6 错误。
当收到一个 IPv6 包时,帧长度被检查并与 IPv6 头部中指出的有效负载长度 或超大有效负载选项中的值(如果有的话)相比较。 如果前者短于后者,包就被抛弃,相应的统计计量被增加。 你可以在加上选项`-s -p ip6'的命令 netstat(8) 的输出中看见统计数字:
% netstat -s -p ip6
ip6:
(略)
1 with data size < data length
所以,除非出错的包是超长有效负载包(包长度超过 65535 字节) 内核不会发送 ICMPv6 出错包。如上所述, 现在还没有物理接口支持超长的最大传输单元 (MTU), 所以很少会返回 ICMPv6 错误信息。
这样的话,超长报文承载的 TCP/UDP 也没有被支持。 这是因为我们没有介质 (除了回环设备) 来进行测试。 如果你需要这些测试,请与我们联系。
IPsec 不能在超长报文上工作。这是因为一些规格歪曲了超长报文的 AH 支持。(AH 头部大小影响有效负载长度, 这使得鉴别既有 AH 又有超长有效负载选项的输入的包变的很困难。)
对于 *BSD 支持超长报文还有一些基本问题。 我们想解决这些问题,不过我们需要更多的时间来完成。 其中的一些问题罗列如下:
-
mbuf 的域 pkthdr.len 在 4.4BSD 中被定义为“int”, 所以在32位系统结构的CPU上 mbuf 不会承载 len > 2G 的超长报文。 如果我们想要支持超长报文,域 pkthdr.len 必须被扩展以适应 4G + IPv6 头部 + 数据链路层头部。 所以,该域至少被扩展为 int64_t (u_int32_t 是不够的)。
-
我们在许多地方错误的使用“int”保存包长度。 我们需要把它们转换为更大的整数类型。 在计算包长度时我们可能遇到溢出,这时需要非常小心。
-
在许多地方我们错误的检查 IPv6 头部的域 ip6_plen 以获知包的有效负载。 相反,我们应该检查 mbuf 的 pkthdr.len 。 ip6_input() 会完善的检查输入中的超长有效负载选项, 在这之后我们就可以安全的使用 mbuf 的 pkthdr.len 了。
-
当然, TCP 代码的很多地方需要更新。
8.1.1.8 头部处理过程中的防止死循环(loop)
IPv6 规格任意多的扩展头部被放入包中。 如果我们安装 BSD IPv4 代码的方式实现 IPv6 包处理, 内核堆栈可能会因为很长的函数调用链而溢出。 sys/netinet6 代码被仔细的设计以避免内核堆栈溢出。 因此,sys/netinet6 代码定义了自己的协议交换数据结构, 例如 “struct ip6protosw” (参见 netinet6/ip6protosw.h)。然而并没有与此兼容的对 IPv4 部分 (sys/netinet) 的更新,不过一些小的修改已被加入到原型 pr_input() 之中。所以“struct ipprotosw”也被定义了。 所以,如果你收到有许多个 IPsec 头部的 IPsec-over-IPv4 包, 内核堆栈可能会爆炸。 IPsec-over-IPv6 是没有问题的。 (当然,对于那些所有要处理的 IPsec 头部,每个这样的 IPsec 头部必须通过每一次 IPsec 检查。所以一个匿名攻击者将无法完全这样的攻击。 )
8.1.1.9 ICMPv6
在 RFC2463 发布之后,IETF ipngwg 决定 禁止针对 ICMPv6 重定向的 ICMPv6 错误包,以防止网络介质上的 ICMPv6 风暴。这样在内核中得到实现。
8.1.1.10 应用程序
对于用户级程序的编程,我们提供 IPv6 套接字应用程序接口的支持, 正如 RFC2553、RFC2292 和将要发布的草案 (Internet drafts) 中规定的那样。
IPv6 基础上的 TCP/UDP 已经可用并且相当稳定。你可以享用 telnet(1), ftp(1), rlogin(1), rsh(1), ssh(1), 等。这样应用程序是与协议无关的。 那意味着他们根据域名系统 (DNS) 自动选择 IPv4 或 IPv6 。
8.1.1.11 内核的内部
当 ip_forward() 调用 ip_output() 时,ip6_forward() 则直接 调用 if_output(),因为路由器不能切分 IPv6 包。
ICMPv6 应该包含原始包,而原始包可能长于 1280。 例如,“UDP6/IP6 端口不可到达”应该包含所有的扩展头部 和 *未改变的* UDP6 和 IP6 头部。 所以,除 TCP 外的所有 IP6 函数都不能将网络字节顺序转换为主机字节顺序, 以便保存原始的包。
tcp_input(), udp6_input() 和 icmp6_input() 不能假设 IP6 头部前置于传输头部,因为还会有扩展头部。 所以,实现 in6_cksum() 时考虑了 IP6 头部与传输头部不连续的包。 TCP/IP6 和 UDP6/IP6 头部结构都不参与检查和计算。
为了方便的处理 IP6 头部、扩展头部和运输头部, 现在,网络驱动程序被要求可在内部的 mbuf 或一至多个外部 mbuf 存储包。 一个典型的旧驱动程序准备两个内部 mbufs 以存储 96 - 204 字节的数据, 然而,现在这样的包数据被存储在一个外部 mbuf 之中。
netstat -s -p ip6 告诉你 你的驱动程序是否符合这样的要求。在如下的例子中, “cce0” 违反了要求。(详情请参考 第 2 节)
Mbuf statistics:
317 one mbuf
two or more mbuf::
lo0 = 8
cce0 = 10
3282 one ext mbuf
0 two or more ext mbuf
每个输入函数在一开始就调用 IP6_EXTHDR_CHECK, 以检查在 IP6 和其头部之间是否是连续的。 IP6_EXTHDR_CHECK 只在 mbuf 有 M_LOOP 标志时调用 m_pullup(), 这也意味着包来自于回环接口。m_pullup() 从不因为来自于物理网络接口的包而被调用。
IP 和 IP6 的重整函数都不调用 m_pullup()。
8.1.1.12 IPv4 映射地址和 IPv6 通配套接字
RFC2553 描述了 IPv4 映射地址 (3.7) 和 IPv6 通配绑定套字的特殊行为 (3.8)。规格允许你:
-
通过 AF_INET6 通配绑定套接字接受 IPv4 连接。
-
使用特殊形式的地址 (像 ::ffff:10.1.1.1 ) 通过 AF_INET6 套接字 传输 IPv4 包。
但是规格自己就非常复杂, 没有指定套接字层应当有怎样的行为。这里我们称前者为 “监听方”,称后者为“初始化方”, 以便引用。
你可以在两种地址族和同一端口上做通配绑定。
下面的表格表明了 FreeBSD 4.x 的行为。
监听方 初始化方
(AF_INET6 通配套接字 (连接到 ::ffff:10.1.1.1)
获得 IPv4 连接)
--- ---
FreeBSD 4.x 可配置缺省:已被允许 已被支持
随后几节将给你更多的详细信息,并告诉你如何配置那些行为。
对于监听方的注释:
似乎 RFC2553 太少提及通配绑定的问题, 尤其是端口空间问题、失败模式和 AF_INET/INET6 通配绑定的关系。 对于这个 RFC ,有几种不同的相符解释,但这些解释却有着不同的行为。 所以,为了实现可执行的应用程序,你不能想当然的假定内核中有关这些行为的一切。 使用 getaddrinfo(3) 是最安全的方式。 端口号空间和通配绑定问题于 1999 年三月中旬在 ipv6imp 信件列表上被详细讨论,似乎没有具体的一致意见 (意思是,由实现者负责)。 你可能需要查看信件列表。
如果服务器应用程序要接受 IPv4 和 IPv6 连接,会有两种选择。
一种是使用 AF_INET 和 AF_INET6 套接字 (你将需要两个套接字 )。使用 getaddrinfo(3) (用 AI_PASSIVE 填上 ai_flags), 还有 socket(2) 和 bind(2) 应对所有返回的地址。 通过打开多个套接字,你可以在地址族正确的套接字上接受连接。 IPv4 连接将用 AF_INET 套接字接受,IPv6 连接将用 AF_INET6 套接字接受。
另一种方式是使用一个 AF_INET6 通配绑定套接字。使用 getaddrinfo(3) (AI_PASSIVE 填入 ai_flags, AF_INET6 填入 ai_family),并设置第一个参数 hostname 为 NULL。并用 socket(2) 和 bind(2) 应对所有返回的地址。 (应当是未明确的 IPv6 地址)。你既可以通过这个套接接受 IPv4 包,也可以接受 IPv6 包。
为了可移植的在 AF_INET6 通配绑定套接字上支持只有 IPv6 的通信, 要在用 AF_INET6 监听套接字建立连接时一直检查对方的地址。 如果对方地址是 IPv4 映射地址,你可能需要拒绝这个连接。 你可以使用宏 IN6_IS_ADDR_V4MAPPED() 检查这个条件。
为了更容易的解决这个问题,有一个与系统相关的 setsockopt(2) 选项,IPV6_BINDV6ONLY,使用方法如下。
int on;
setsockopt(s, IPPROTO_IPV6, IPV6_BINDV6ONLY,
(char *)&on, sizeof (on)) < 0));
当这个调用成功时,这个套接字就只接收 IPv6 包。
对于初始化方的注释:
对应用程序实现者的建议:为了实现一个可移植的 IPv6 应用程序 (这个程序可工作在多种 IPv6 内核上), 我们认为如下是成功的关键:
-
决不要定死 AF_INET 或 AF_INET6。
-
在整个系统使用 getaddrinfo(3) 和 getnameinfo(3)。 决不要使用 gethostby*(),getaddrby*(), inet_*() 或 getipnodeby*()。(为了方便的更新现存应用程序为支持 IPv6 的,有时 getipnodeby*() 会有用。但是如果可能,尝试用 getaddrinfo(3) 和 getnameinfo(3) 重写代码。)
-
如果你要连接到目的地,使用 getaddrinfo(3) 并尝试所有返回的目的地址, 正如 telnet(1) 所做的那样。
-
一些 IPv6 协议栈的 getaddrinfo(3) 有错误。在你的应用程序也携带一份该函数代码最小的可工作版本, 以作为最后的解决办法。
如果你要使用 AF_INET6 套接字同时处理 IPv4 和 IPv6 向外连接,你需要使用 getipnodebyname(3)。 当你需要以最小改动更新你的应用程序以支持 IPv6, 就可以选择这种方式。 但是请注意这是一种临时解决办法,因为 getipnodebyname(3) 自己由于完全不能处理有作用域的 IPv6 地址而不被推荐。 对于 IPv6 名字解析,getaddrinfo(3) 是首选的应用程序接口 (API)。所以你有时间的时候, 应该用 getaddrinfo(3) 重写你的应用程序。
在写建立向外连接的应用程序时, 如果你把 AF_INET 和 AF_INET6 按照完全不同的地址族对待,情况就大大简单了。 {set,get}sockopt 的问题比较简单, DNS 的问题也会变的比较简单。我们不推荐你依赖 IPv4 映射地址。
8.1.1.12.1 联合的 tcp 和 inpcb 代码
FreeBSD 4.x 在 IPv4 和 IPv6 之间使用共享的 tcp 代码 (sys/netinet/tcp*) 和彼此独立的 udp4/6 代码。 这些代码中使用联合的 inpcb 结构体。
这个平台可被配置以支持 IPv4 映射地址。 内核配置被总结如下:
-
缺省时,AF_INET6 套接字将在特定条件下抓取 IPv4 连接,并能初始化连接到 IPv4 目的地,该这个目的地址嵌在 IPv4 映射的 IPv6 地址中。
-
你可以用下述的 sysctl 项在整个系统禁用此功能。
sysctl net.inet6.ip6.mapped_addr=0
8.1.1.12.1.1 监听方
每个套接字可被配置已支持特殊的 AF_INET6 通配绑定 (缺省是被开启的)。你可以用 setsockopt(2) 在每个套接字上禁用此功能:
int on;
setsockopt(s, IPPROTO_IPV6, IPV6_BINDV6ONLY,
(char *)&on, sizeof (on)) < 0));
通配 AF_INET6 套接字抓取 IPv4 连接当且仅当 下列条件被满足:
-
没有 AF_INET 套接字匹配 IPv4 连接
-
AF_INET6 套接字被配置接受 IPv4 通信,这是指 getsockopt(IPV6_BINDV6ONLY) 返回 0。
打开/关闭 的顺序不会引起问题。
8.1.1.13 sockaddr_storage
在 RFC2553 的结尾,有一些关于 struct sockaddr_storage 的成员该如何命名的讨论。一个建议是 冠以“__”到成员的名字上 (就像 “__ss_len”),表示他们不能碰。 另一个建议是不加前缀 (就像 “ss_len”), 表示我们需要直接接触那些成员。在这个问题上,最终也没有清晰的一致意见。
结果,RFC2553 定义 struct sockaddr_storage 如下:
struct sockaddr_storage {
u_char __ss_len; /* 地址长度 */
u_char __ss_family; /* 地址族 */
/* 以及一些填充 */
};
相反,XNET 草案定义如下:
struct sockaddr_storage {
u_char ss_len; /* 地址长度 */
u_char ss_family; /* 地址族 */
/* 以及一些填充 */
};
在 1999 年 12 月,一致意见形成了,RFC2553bis 应选择 后一种 (XNET) 定义。
现在的实现符合 XNET 定义, 以 RFC2553bis 的讨论为基础。
如果你看过多种 IPv6 实现,你将可以看到这两种定义。 对于一个用户程序编程者,对此移植性最好的方法是:
-
保证该平台有 ss_family 和/或 ss_len, 可使用 GNU autoconf,
-
设置 -Dss_family=__ss_family 以统一所有的相应成员名称 (包括头文件) 为 __ss_family,或
-
决不要碰 __ss_family。强制转换为 sockaddr * 并这样使用 sa_family:
struct sockaddr_storage ss; family = ((struct sockaddr *)&ss)->sa_family
8.1.2 网络驱动程序
现在如下两项被要求由标准驱动程序支持:
-
mbuf聚集。在这个稳定发行版中, 我们为所有操作系统将MINCLSIZE改为MHLEN+1, 以便使所有驱动程序按照我们期望的那样工作。
-
组播。如果ifmcstat(8)没有对一个接口产生组播群, 此接口就需要被打补丁。
如果驱动程序中的任何一个不支持这些要求, 那么驱动程序不能用于IPv6和/或IPsec通信。 如果你发觉你的使用IPv6/IPsec的网卡有问题,那么, 请报告给FreeBSD 问题报告邮件列表。
(注意:过去我们要求所有PCMCIA驱动程序有一个对in6_ifattach()的调用。 我们现在不再有那样的要求。)
8.1.3 翻译器
我们将IPv4/IPv6翻译器分为4类:
-
翻译器 A ── 被用于过度的早期阶段,使得从IPv6岛中的IPv6主机建立一个到 IPv4海中的IPv4主机成为可能。
-
翻译器 B ── 被用于过度的早期阶段,使得从IPv4海中的IPv4主机建立一个到 IPv6岛中的IPv6主机成为可能。
-
翻译器 C ── 被用于过度的晚期阶段,使得从IPv4岛中的IPv4主机建立一个到 IPv6海中的IPv6主机成为可能。
-
翻译器 D ── 被用于过度的晚期阶段,使得从IPv6海中的IPv6主机建立一个到 IPv4岛中的IPv4主机成为可能。
A类的TCP延时翻译器已被支持。 这被称为“FAITH”。我们也提供A类的IP头部翻译器。 (后者还没有被放入FreeBSD 4.x。)
8.1.3.1 FAITH TCP 延时翻译器
FAITH系统使用TCP延时守护程序,被称为faithd(8), 由内核支持。FAITH将保留一个IPv6地址前缀, 并且把向该前缀的TCP连接中转到IPv4目的。
例如,如果被保留的IPv6前缀是 2001:0DB8:0200:ffff::,TCP连接的IPv6目的是 2001:0DB8:0200:ffff::163.221.202.12, 连接将被中转到IPv4目的163.221.202.12。
目的 IPv4 结点 (163.221.202.12)
^
| IPv4 tcp toward 163.221.202.12
FAITH-中转 双堆栈结点
^
| IPv6 TCP toward 2001:0DB8:0200:ffff::163.221.202.12
源 IPv6 结点
faithd(8)必须在FAITH-中转双栈结点上被调用。
更多详细信息,参考 src/usr.sbin/faithd/README 。
8.1.4 IPsec
IPsec主要按三个部分组织。
-
策略管理
-
钥匙管理
-
AH和ESP处理
8.1.4.1 策略管理
内核实现了实验性的策略管理代码。 有两种方法管理安全策略。 一种是使用setsockopt(2)配置每个套接字的策略。这种情况下, 相关策略配置被描述在ipsec_set_policy(3)。 另一种是通过setkey(8)使用PF_KEY接口配置以内核包过滤器为基础的策略。
策略条目不按其索引重排序, 所以在你添加时的条目顺序是非常重要的。
8.1.4.2 钥匙管理
在工具包(sys/netkey)中实现的钥匙管理代码是一个自造的PFKEY第2版的实现。 这符合RFC2367。
自造的IKE管理程序“racoon”包含在工具包(kame/kame/racoon)。 一般说来,你需要将racoon运行为守护程序, 然后建立一条策略请求钥匙(就像 ping -P 'out ipsec esp/transport//use')。 内核将会按需要与racoon守护程序联系以交换钥匙。
8.1.4.3 AH 和 ESP 处理
IPsec模块作为标准IPv4/IPv6处理的“钩子”被实现。 当发送一个包时,ip{,6}_output()通过检查是否可以找到一个匹配用的SPD (Security Policy Database),来检查是否需要ESP/AH处理。 如果需要ESP/AH,{esp,ah}{4,6}_output()将被调用,mbuf将被随之更新。 当收到一个包时,{esp,ah}4_input()将被按协议号调用,即 (*inetsw[proto])()。 {esp,ah}4_input()将解密/检查包的真实性, 并剥去菊花链头部,ESP/AH的填充。 在包受理时剥去ESP/AH部分是安全的, header on packet reception, since we 因为我们从不受理接收到的“原样的”包。
通过使用ESP/AH,TCP4/6有效数据段大小将受 ESP/AH插入的附加菊花链头部的影响。 我们的代码考虑了这样的情况。
基本的加密函数可在目录"sys/crypto"中找到。 ESP/AH 转换被列在 {esp,ah}_core.c,带有包裹函数。 使用你希望添加一些算法,就把包裹函数添加至 {esp,ah}_core.c,并添加你的加密算法代码至 sys/crypto。
这个发行版部分实现了隧道模式, 有如下限制:
-
IPsec隧道不与GIF通用隧道接口组合。 这需要特别注意,因为我们可能会造成在 ip_output() 和 tunnelifp->if_output() 之间的无限循环。 对于是否将他们联合起来更好的观点一直在变化。
-
MTU 和 “不切分”位(Don't Fragment)(IPv4) 还需要进一步考察, 不过一般说来工作情况良好。
-
AH 隧道的认证模式必须被复议。 我们需要改善策略管理引擎, 最终要做的。
8.1.4.4 遵守 RFC 和 ID
内核中的 IPsec 代码遵守 (或努力去遵守) 如下标准:
“旧 IPsec”规格,载于 rfc182[5-9].txt
“新 IPsec”规格,载于 rfc240[1-6].txt、 rfc241[01].txt、rfc2451.txt 和 draft-mcdonald-simple-ipsec-api-01.txt (草案已过期,但是你可以取自 ftp://ftp.kame.net/pub/internet-drafts/)。 (注意:IKE 规格,rfc241[7-9].txt 在用户级实现,如“racoon”IKE 守护程序)
当然支持的算法是:
-
旧 IPsec AH
-
空加密检查和 (无文档, 仅为排错)
-
加锁的 MD5 带128位加密检查和 (rfc1828.txt)
-
加锁的 SHA1 带128位加密检查和 (无文档)
-
HMAC MD5 带128位加密检查和 (rfc2085.txt)
-
HMAC SHA1 带128位加密检查和 (无文档)
-
-
旧 IPsec ESP
-
无加密 (无文档,相同于 rfc2410.txt)
-
DES-CBC 模式 (rfc1829.txt)
-
-
新 IPsec AH
-
空加密检查和 (无文档, 仅为排错)
-
加锁的 MD5 带96位加密检查和 (无文档)
-
加锁的 SHA1 带96位加密检查和 (无文档)
-
HMAC MD5 带96位加密检查和 (rfc2403.txt)
-
HMAC SHA1 带96位加密检查和 (rfc2404.txt)
-
-
新 IPsec ESP
-
无加密 (rfc2410.txt)
-
DES-CBC 带衍生的 IV (draft-ietf-ipsec-ciph-des-derived-01.txt, 草案已过期)
-
DES-CBC 带显式的 IV (rfc2405.txt)
-
3DES-CBC 带显式的 IV (rfc2451.txt)
-
BLOWFISH CBC (rfc2451.txt)
-
CAST128 CBC (rfc2451.txt)
-
RC5 CBC (rfc2451.txt)
-
上面每种情形可以与下列组合:
-
ESP HMAC-MD5 认证 (96位)
-
ESP HMAC-SHA1 认证 (96位)
-
-
如下算法不被支持:
-
旧 IPsec AH
-
HMAC MD5 带128位加密检查和 + 64位 防重复 (rfc2085.txt)
-
加锁的 SHA1 带160位加密检查和 + 32位填充 (rfc1852.txt)
-
IPsec (在内核中) 和 IKE (用户级的“racoon”) 已被在几种互操作测试情形中测试,与许多其它实现互操作良好。 并且,当前的 IPsec 实现对于载于RFC中的加密算法有很大的覆盖面 (我们只覆盖了无智能属性的算法)。
8.1.4.5 IPsec 隧道兼容 ECN
与 ECN 兼容良好的 IPsec 隧道的支持被描述在 draft-ipsec-ecn-00.txt。
普通的 IPsec 隧道被描述在 RFC2401 。加封装时, IPv4 TOS 域 (或 IPv6 交换类域) 将被从内部 IP 头部复制到 外部 IP 头部。 去封装时,外部 IP 头部会被简单的抛弃。 去封装的规则与 ECN 不兼容, 这是因为外部 IP TOS/交换类域中的 ECN 位会被丢失。
为了使 IPsec 隧道与 ECN 配合良好, 我们应该修改加封装和去封装的步骤。 这被描述在 http://www.aciri.org/floyd/papers/draft-ipsec-ecn-00.txt, 第 3 章。
IPsec 隧道的实现可以给我们三种选择,这些选择通过设置 net.inet.ipsec.ecn (或 net.inet6.ipsec6.ecn) 为一些特定的值来指定:
-
RFC2401: 未考虑 ECN (sysctl 项的值为 -1)
-
ECN 被禁用 (sysctl 项的值为 0)
-
ECN 被允许 (sysctl 项的值为 1)
注意,以上选项在每个结点都可配置, 而不是按每安全关联 (Security Association, SA) 的方式。 (draft-ipsec-ecn-00 要求按每安全关联进行配置, 但是对于我来说那显得太多了)
各选项总结如下 (详见源代码):
加封装 去封装
--- ---
RFC2401 把所有 TOS 位 抛弃外部的 TOS 位
从内部复制到外部 (原样的使用内部 TOS 位)
ECN 被禁用 除 ECN (掩码 0xfc) 外将 抛弃外部的 TOS 位
TOS 位从内部复制到外部。 (原样的使用内部 TOS 位)
设置 ECN 位为 0 。
ECN 被允许 除 ECN CE (掩码 0xfe) 外将 使用内部 TOS 位,有一些改变。
TOS 位从内部复制到外部。 如果外部 ECN CE 位是1,
设置 ECN CE 位为 0 。 则在内部使能 ECN CE 位。
通用配置方法如下:
-
如果两个 IPsec 隧道端点能兼容 ECN 你最好将两个端点配置为 “ECN 被允许” (sysctl 项的值为 1)。
-
如果另一端对 TOS 位的控制很严格,使用“RFC2401” (sysctl 项的值为 -1)。
-
在其它情形中,使用“ECN 被禁用” (sysctl 项的值为 0)。
缺省行为是“ECN 被禁用” (sysctl 项的值为 0)。
更多信息请参考:
http://www.aciri.org/floyd/papers/draft-ipsec-ecn-00.txt, RFC2481 (显式拥塞通知), src/sys/netinet6/{ah,esp}_input.c
(感谢长・健二朗 <kjc@csl.sony.co.jp> 的详细分析 )
8.1.4.6 互操作性
KAME 的代码已经在一些平台上测试了 IPsec/IKE 的互操作性。 注意,互操作性测试的两边都已修改了它们的实现, 所以如下清单仅供参考。
Altiga, Ashley-laurent (vpcom.com), Data Fellows (F-Secure), Ericsson ACC, FreeS/WAN, 日立, IBM AIX®, IIJ, Intel, Microsoft® Windows NT®, NIST (linux IPsec + plutoplus), Netscreen, OpenBSD, RedCreek, Routerware, SSH, Secure Computing, Soliton, 东芝, VPNet, Yamaha(在日本还用日文假名写作“ヤマハ”,对应汉字为繁体的“山叶”, 为其创始人山叶寅楠的姓氏,但日本人并不习惯于用汉字“山叶”指称该公司) RT100i
第III部分. 内核
- 目录
- 第9章 联编并安装 FreeBSD 内核
- 第10章 调试内核
第9章 联编并安装 FreeBSD 内核
作为内核开发人员, 了解内核的联编过程是十分重要的。 要调试 FreeBSD 内核, 首先要能够联编它才能够开始。 有两种方法能够完成这个任务:
-
“传统” 方式
-
“新” 方式
注意: 本章假定读者熟悉在 FreeBSD 使用手册中 联编并安装定制的内核 一章所介绍的方法。 如果不是这样的话, 请阅读这一章, 以了解联编过程是如何进行的。
9.1 以 “传统” 方式联编内核
在 FreeBSD 4.X 版本之前, 这是推荐的联编内核的方式。 在新版本中这一方式仍然可以使用 (推荐的方式并不是这样, 而是使用位于 /usr/src/ 的那些 makefile 所提供的 “buildkernel”)。 以这种方式联编内核, 在修改内核代码时可能会比较有用, 并且它在只调整了一两个内核选项时, 有可能比 “新” 联编流程更快。 而另一方面, 新手或使用新版本的 FreeBSD 时, 这种方法也可能导致一些非预期的问题。
第10章 调试内核
供稿:Paul Richards、 Jörg Wunsch 和 Robert Watson. 翻译:李 鑫.10.1 如何将内核的崩溃转存数据保存成文件
在极端条件下在使用尚有待进一步完善的内核 (例如 FreeBSD-CURRENT) 时 (比如系统在非常高的负载下运行, 数以万计的连接, 过多的用户同时登录使用, 或使用成百上千的 jail(8)), 或在 FreeBSD-STABLE 上使用新特性或新驱动 (例如 PAE) 时, 内核都可能发生崩溃。 本章将针对这些情况, 介绍在内核崩溃时提取有价值的信息的方法。
内核崩溃时, 系统不可避免地要重启。 而系统重启将使物理内存 (RAM) 以及交换设备上的数据荡然无存。 为保存内存中的数据, 内核使用交换设备临时储存崩溃前 RAM 上的数据。 这样做使得 FreeBSD 重启后, 可从中得到当时内核的镜像, 从而为进一步调试提供基础。
注意: 交换设备在被配置成内核存档设备后仍可作为交换设备正常使用。 目前尚不支持将其它设备 (如磁带、 CDRW等) 配置为内核崩溃时的转存设备。 这里所说的 “交换设备” 就是 “交换分区。”
内核的转存方式有很多种: 完整的内存转存 (full memory dump) 会保存物理内存中的全部内容; 内核内存转存 (minidump) 则只转存由内核使用的那些内存页 (需要 FreeBSD 6.2 或更高版本); 文本化转存 (textdump), 则只保存由脚本或交互式调试器输出的内容 (FreeBSD 7.1 或更高版本)。 从 FreeBSD 7.0 开始, 默认的转存类型是只转存内核内存, 由于多数问题都可以仅通过内核的状态来进行诊断, 因此即使不使用全内存转存方式, 在多数情况下, 这种方式也已经能够提供足够多的信息了。
10.1.1 配置内核转存设备
只有在配置内核转存设备之后, 内核才会向其写入崩溃时内存中的数据。 dumpon(8)
命令告诉内核在何处保存崩溃的内核。 dumpon(8)
只能在已经通过 swapon(8)
配置好的交换分区上使用。 通常, 只需在 rc.conf(5) 中把 dumpdev 变量设为交换分区的设备路径既可
(推荐用这种方法提取内核转存数据); 另外, 也可以将其设置为 AUTO
表示使用第一个交换设备。 从 FreeBSD 6.0 开始, AUTO
成为了系统默认的配置。
提示: 可以通过查看 /etc/fstab 或 swapinfo(8) 的输出来了解系统中现有的交换设备。
重要: 在分析内核崩溃之前, 首先确认一下 rc.conf(5) 所设置的
dumpdir确实存在!# mkdir /var/crash # chmod 700 /var/crash需要注意的是, 对外界而言, /var/crash 中保存的数据可能包含敏感信息, 因为其中可能包含一些机密内容, 如用户密码等等。
10.1.2 提取内核转存数据
一旦内核转存到转存设备之后, 就需要在下次交换设备挂载之前,
将其提取并保存到文件中。 要从转存设备中提取内核转存数据, 就需要使用 savecore(8) 程序。
如果在 rc.conf(5) 中配置了
dumpdev, 则崩溃之后的首次多用户方式启动过程中,
在配置交换区设备之前便会自动执行 savecore(8)。
提取出来的内核数据将存放在 rc.conf(5) 变量 dumpdir 所指定的位置, 其默认值为 /var/crash, 而保存的文件名则是 vmcore.0。
若 /var/crash 目录下 (或 dumpdev设置的其它目录), 已存在了名为 vmcore.0 的文件, 则每次保存内核转存数据时, 其末尾的数字会顺次递增
(例如 vmcore.1) 以避免覆盖之前存档的转存数据。 所以,
调试内核时, /var/crash 目录下序号最大的 vmcore 通常就是希望找的那个 vmcore。
提示: 如果正在调试新的内核, 但需要从另一能支持系统正常运行的内核启动, 就应在屏幕出现启动提示时, 使用
-s选项进入单用户模式, 再按下列步骤操作:# fsck -p # mount -a -t ufs # make sure /var/crash is writable # savecore /var/crash /dev/ad0s1b # exit # exit to multi-user上述操作将指示 savecore(8) 从 /dev/ad0s1b 中抽取内核的崩溃转存数据, 并保存至 /var/crash。 在此之前, 应确保目标目录 /var/crash 中有足以保存转存数据的空间。 此外, 请确认交换设备的路径是正确的, 因为它很可能不是 /dev/ad0s1b!
10.2 使用 kgdb 调试内核的崩溃转存
注意: 这一节介绍了 FreeBSD 5.3 及更高版本中的 kgdb(1)。 在较早的版本中, 需要使用 gdb -k 来阅读内核的转存文件。
通常, 一旦得到了转存数据, 就很容易从中得到关于简单问题的有用信息了。 在开始使用
kgdb(1)
来调试崩溃转存文件之前, 您应找出调试版本的内核 (通常叫做 kernel.debug) 以及用于构建您的内核的源代码 (一般是 /usr/obj/usr/src/sys/KERNCONF,
其中 KERNCONF 是通过 config(5) 所指定的
ident)。 有了这两部分信息, 就可以开始着手调试了!
要进入调试器并从转存文件中获取信息, 至少需要完成下列操作:
# cd /usr/obj/usr/src/sys/KERNCONF # kgdb kernel.debug /var/crash/vmcore.0
配合内核的源代码, 就可以像调试其他程序那样调试崩溃转存文件了。
第一个转存文件来自一 5.2-BETA 的内核, 导致内核崩溃的是相当深层次的原因。 下面的输出结果左侧加入了行号, 以便于阅读。 第一个回溯检查了指令指针, 并获得了调用栈的内容。 在第 41 行指定给 list 命令的地址, 可以在第 17 行找到。 如果您自己无法自行调试并解决问题, 多数内核开发人员都会要求您提供前述的信息以帮助他们找到问题所在。 不过, 如果您自己解决了问题, 一定要设法让它通过问题报告、 邮件列表, 或直接 commit 的方法回到源代码树上!
1:# cd /usr/obj/usr/src/sys/KERNCONF
2:# kgdb kernel.debug /var/crash/vmcore.0
3:GNU gdb 5.2.1 (FreeBSD)
4:Copyright 2002 Free Software Foundation, Inc.
5:GDB is free software, covered by the GNU General Public License, and you are
6:welcome to change it and/or distribute copies of it under certain conditions.
7:Type "show copying" to see the conditions.
8:There is absolutely no warranty for GDB. Type "show warranty" for details.
9:This GDB was configured as "i386-undermydesk-freebsd"...
10:panic: page fault
11:panic messages:
12:---
13:Fatal trap 12: page fault while in kernel mode
14:cpuid = 0; apic id = 00
15:fault virtual address = 0x300
16:fault code: = supervisor read, page not present
17:instruction pointer = 0x8:0xc0713860
18:stack pointer = 0x10:0xdc1d0b70
19:frame pointer = 0x10:0xdc1d0b7c
20:code segment = base 0x0, limit 0xfffff, type 0x1b
21: = DPL 0, pres 1, def32 1, gran 1
22:processor eflags = resume, IOPL = 0
23:current process = 14394 (uname)
24:trap number = 12
25:panic: page fault
26 cpuid = 0;
27:Stack backtrace:
28
29:syncing disks, buffers remaining... 2199 2199 panic: mi_switch: switch in a critical section
30:cpuid = 0;
31:Uptime: 2h43m19s
32:Dumping 255 MB
33: 16 32 48 64 80 96 112 128 144 160 176 192 208 224 240
34:---
35:Reading symbols from /boot/kernel/snd_maestro3.ko...done.
36:Loaded symbols for /boot/kernel/snd_maestro3.ko
37:Reading symbols from /boot/kernel/snd_pcm.ko...done.
38:Loaded symbols for /boot/kernel/snd_pcm.ko
39:#0 doadump () at /usr/src/sys/kern/kern_shutdown.c:240
40:240 dumping++;
41:(kgdb) list *0xc0713860
42:0xc0713860 is in lapic_ipi_wait (/usr/src/sys/i386/i386/local_apic.c:663).
43:658 incr = 0;
44:659 delay = 1;
45:660 } else
46:661 incr = 1;
47:662 for (x = 0; x < delay; x += incr) {
48:663 if ((lapic->icr_lo & APIC_DELSTAT_MASK) == APIC_DELSTAT_IDLE)
49:664 return (1);
50:665 ia32_pause();
51:666 }
52:667 return (0);
53:(kgdb) backtrace
54:#0 doadump () at /usr/src/sys/kern/kern_shutdown.c:240
55:#1 0xc055fd9b in boot (howto=260) at /usr/src/sys/kern/kern_shutdown.c:372
56:#2 0xc056019d in panic () at /usr/src/sys/kern/kern_shutdown.c:550
57:#3 0xc0567ef5 in mi_switch () at /usr/src/sys/kern/kern_synch.c:470
58:#4 0xc055fa87 in boot (howto=256) at /usr/src/sys/kern/kern_shutdown.c:312
59:#5 0xc056019d in panic () at /usr/src/sys/kern/kern_shutdown.c:550
60:#6 0xc0720c66 in trap_fatal (frame=0xdc1d0b30, eva=0)
61: at /usr/src/sys/i386/i386/trap.c:821
62:#7 0xc07202b3 in trap (frame=
63: {tf_fs = -1065484264, tf_es = -1065484272, tf_ds = -1065484272, tf_edi = 1, tf_esi = 0, tf_ebp = -602076292, tf_isp = -602076324, tf_ebx = 0, tf_edx = 0, tf_ecx = 1000000, tf_eax = 243, tf_trapno = 12, tf_err = 0, tf_eip = -1066321824, tf_cs = 8, tf_eflags = 65671, tf_esp = 243, tf_ss = 0})
64: at /usr/src/sys/i386/i386/trap.c:250
65:#8 0xc070c9f8 in calltrap () at {standard input}:94
66:#9 0xc07139f3 in lapic_ipi_vectored (vector=0, dest=0)
67: at /usr/src/sys/i386/i386/local_apic.c:733
68:#10 0xc0718b23 in ipi_selected (cpus=1, ipi=1)
69: at /usr/src/sys/i386/i386/mp_machdep.c:1115
70:#11 0xc057473e in kseq_notify (ke=0xcc05e360, cpu=0)
71: at /usr/src/sys/kern/sched_ule.c:520
72:#12 0xc0575cad in sched_add (td=0xcbcf5c80)
73: at /usr/src/sys/kern/sched_ule.c:1366
74:#13 0xc05666c6 in setrunqueue (td=0xcc05e360)
75: at /usr/src/sys/kern/kern_switch.c:422
76:#14 0xc05752f4 in sched_wakeup (td=0xcbcf5c80)
77: at /usr/src/sys/kern/sched_ule.c:999
78:#15 0xc056816c in setrunnable (td=0xcbcf5c80)
79: at /usr/src/sys/kern/kern_synch.c:570
80:#16 0xc0567d53 in wakeup (ident=0xcbcf5c80)
81: at /usr/src/sys/kern/kern_synch.c:411
82:#17 0xc05490a8 in exit1 (td=0xcbcf5b40, rv=0)
83: at /usr/src/sys/kern/kern_exit.c:509
84:#18 0xc0548011 in sys_exit () at /usr/src/sys/kern/kern_exit.c:102
85:#19 0xc0720fd0 in syscall (frame=
86: {tf_fs = 47, tf_es = 47, tf_ds = 47, tf_edi = 0, tf_esi = -1, tf_ebp = -1077940712, tf_isp = -602075788, tf_ebx = 672411944, tf_edx = 10, tf_ecx = 672411600, tf_eax = 1, tf_trapno = 12, tf_err = 2, tf_eip = 671899563, tf_cs = 31, tf_eflags = 642, tf_esp = -1077940740, tf_ss = 47})
87: at /usr/src/sys/i386/i386/trap.c:1010
88:#20 0xc070ca4d in Xint0x80_syscall () at {standard input}:136
89:---Can't read userspace from dump, or kernel process---
90:(kgdb) quit
下一组回溯信息来自 FreeBSD 2 时代一个古老的转存文件, 但它更为棘手, 并展示了更多 gdb 的功能。 为了便于阅读, 对较长的行进行了折行处理, 并增加了行号。 这是一个现实环境中, 在开发pcvt 控制台驱动时发现的问题。
1:Script started on Fri Dec 30 23:15:22 1994
2:# cd /sys/compile/URIAH
3:# gdb -k kernel /var/crash/vmcore.1
4:Reading symbol data from /usr/src/sys/compile/URIAH/kernel
...done.
5:IdlePTD 1f3000
6:panic: because you said to!
7:current pcb at 1e3f70
8:Reading in symbols for ../../i386/i386/machdep.c...done.
9:(kgdb) backtrace
10:#0 boot (arghowto=256) (../../i386/i386/machdep.c line 767)
11:#1 0xf0115159 in panic ()
12:#2 0xf01955bd in diediedie () (../../i386/i386/machdep.c line 698)
13:#3 0xf010185e in db_fncall ()
14:#4 0xf0101586 in db_command (-266509132, -266509516, -267381073)
15:#5 0xf0101711 in db_command_loop ()
16:#6 0xf01040a0 in db_trap ()
17:#7 0xf0192976 in kdb_trap (12, 0, -272630436, -266743723)
18:#8 0xf019d2eb in trap_fatal (...)
19:#9 0xf019ce60 in trap_pfault (...)
20:#10 0xf019cb2f in trap (...)
21:#11 0xf01932a1 in exception:calltrap ()
22:#12 0xf0191503 in cnopen (...)
23:#13 0xf0132c34 in spec_open ()
24:#14 0xf012d014 in vn_open ()
25:#15 0xf012a183 in open ()
26:#16 0xf019d4eb in syscall (...)
27:(kgdb) up 10
28:Reading in symbols for ../../i386/i386/trap.c...done.
29:#10 0xf019cb2f in trap (frame={tf_es = -260440048, tf_ds = 16, tf_\
30:edi = 3072, tf_esi = -266445372, tf_ebp = -272630356, tf_isp = -27\
31:2630396, tf_ebx = -266427884, tf_edx = 12, tf_ecx = -266427884, tf\
32:_eax = 64772224, tf_trapno = 12, tf_err = -272695296, tf_eip = -26\
33:6672343, tf_cs = -266469368, tf_eflags = 66066, tf_esp = 3072, tf_\
34:ss = -266427884}) (../../i386/i386/trap.c line 283)
35:283 (void) trap_pfault(&frame, FALSE);
36:(kgdb) frame frame->tf_ebp frame->tf_eip
37:Reading in symbols for ../../i386/isa/pcvt/pcvt_drv.c...done.
38:#0 0xf01ae729 in pcopen (dev=3072, flag=3, mode=8192, p=(struct p\
39:roc *) 0xf07c0c00) (../../i386/isa/pcvt/pcvt_drv.c line 403)
40:403 return ((*linesw[tp->t_line].l_open)(dev, tp));
41:(kgdb) list
42:398
43:399 tp->t_state |= TS_CARR_ON;
44:400 tp->t_cflag |= CLOCAL; /* cannot be a modem (:-) */
45:401
46:402 #if PCVT_NETBSD || (PCVT_FREEBSD >= 200)
47:403 return ((*linesw[tp->t_line].l_open)(dev, tp));
48:404 #else
49:405 return ((*linesw[tp->t_line].l_open)(dev, tp, flag));
50:406 #endif /* PCVT_NETBSD || (PCVT_FREEBSD >= 200) */
51:407 }
52:(kgdb) print tp
53:Reading in symbols for ../../i386/i386/cons.c...done.
54:$1 = (struct tty *) 0x1bae
55:(kgdb) print tp->t_line
56:$2 = 1767990816
57:(kgdb) up
58:#1 0xf0191503 in cnopen (dev=0x00000000, flag=3, mode=8192, p=(st\
59:ruct proc *) 0xf07c0c00) (../../i386/i386/cons.c line 126)
60: return ((*cdevsw[major(dev)].d_open)(dev, flag, mode, p));
61:(kgdb) up
62:#2 0xf0132c34 in spec_open ()
63:(kgdb) up
64:#3 0xf012d014 in vn_open ()
65:(kgdb) up
66:#4 0xf012a183 in open ()
67:(kgdb) up
68:#5 0xf019d4eb in syscall (frame={tf_es = 39, tf_ds = 39, tf_edi =\
69: 2158592, tf_esi = 0, tf_ebp = -272638436, tf_isp = -272629788, tf\
70:_ebx = 7086, tf_edx = 1, tf_ecx = 0, tf_eax = 5, tf_trapno = 582, \
71:tf_err = 582, tf_eip = 75749, tf_cs = 31, tf_eflags = 582, tf_esp \
72:= -272638456, tf_ss = 39}) (../../i386/i386/trap.c line 673)
73:673 error = (*callp->sy_call)(p, args, rval);
74:(kgdb) up
75:Initial frame selected; you cannot go up.
76:(kgdb) quit
关于前述记录的一些说明:
- 第 6 行:
-
这是一份从 DDB (参见下面的说明) 中直接获得的转存文件, 因此崩溃说明是 “because you said to!”, 而且其调用栈较长; 不过, 最初进入 DDB 的原因是在内核中发生了一次缺页 trap。
- 第 20 行:
-
这是函数
trap()在调用栈中的位置。 - 第 36 行:
-
强制使用新的栈帧; 现在已经不再需要这样做了。 即使发生了 trap, 也可以认为栈帧指向了正确的位置。 通过观察源代码的第 403 行可以发现, 要么对指针 “tp” 的访问出现了问题, 要么访问数组时发生了越界。
- 第 52 行:
-
这个指针看起来值得怀疑, 但它曾经是一个有效地址。
- 第 56 行:
-
但是, 它很明显指到了不该指的位置, 因此我们找到错误了! (如果您不熟悉这段代码: tp->t_line 表示此控制台设备所用的线路, 它应该是一个较小的整数。)
提示: 如果您的系统经常崩溃, 并因此导致磁盘空间不足, 删除 /var/crash 中的 vmcore 文件应该能够省出大量的磁盘空间!
10.3 使用 DDD 调试崩溃转存文件
除了前面介绍的方法之外, 您还可以使用类似 ddd
这样的图形化调试器 (需要首先安装 devel/ddd port 才能使用 ddd 调试器)。
在您通常的 ddd 的命令行中增加一个 -k
选项就可以了。 例如:
# ddd --debugger kgdb kernel.debug /var/crash/vmcore.0
这样就可以使用 ddd 的图形界面来调试内核的崩溃转存文件了。
10.4 使用 DDB 进行在线内核调试
尽管作为离线调试方式的 kgdb 提供了非常高级的用户界面, 但它仍然有许多无法完成的工作。 最重要的几项功能是设置断点, 以及以单步方式执行内核代码。
如果您需要对内核进行较为底层的调试, 则可以利用称为 DDB 的在线调试器。 它能够让您设置断点、 单步执行内核函数, 查看或修改内核变量等。 然而, 它不能访问内核源代码文件, 而且只能访问全局和静态符号, 而不像 gdb 那样能访问全部调试符号。
要配置您的内核使其包含 DDB, 需要在您的内核配置文件中加入
options KDB
options DDB然后重新编译。 (参见 FreeBSD 使用手册 以了解如何配置 FreeBSD 内核的进一步详情)。
注意: 如果您使用的引导块版本较早, 则可能完全无法加载调试符号。 遇到这种情况时请更新引导块; 新版本的引导块能够自动加载 DDB 符号了。
只要使用了包含 DDB 功能的内核, 就可以通过多种途径进入 DDB 了。 第一种,
同时也是最简单的方式, 是在启动时指定引导参数 -d。 这样,
内核就会以调试方式启动, 并在开始检测设备之前进入 DDB。 这样一来,
即使是那些用于设备检测/挂接的函数, 也都能很容易地进行调试了。 使用 FreeBSD-CURRENT
的用户, 则需要在引导菜单中选择第六项来进入引导加载器提示符。
第二种情形, 是在系统启动之后进入调试器。 有两种简单的方法来达到这一目的。 如果您希望从命令行进入调试器, 只需简单地输入下面的命令:
# sysctl debug.kdb.enter=1
注意: 如果需要强制产生一次 panic, 可以使用下面的命令:
# sysctl debug.kdb.panic=1
另外, 如果您能操作系统的控制台, 也可以使用一组热键。 默认情况下, 可以通过连续按下 Ctrl+Alt+ESC 来进入调试器。 对 syscons 而言, 还可以重新映射具体的按键序列, 因此您应仔细检查来确认实际的按键。 此外, 在使用串口控制台时, 也可以使用串口线的 BREAK 来进入 DDB (在内核配置文件中, 需要加入 options BREAK_TO_DEBUGGER)。 这一选项并非默认值, 因为许多串口适配器会莫名其妙地生成 BREAK, 例如在拔下电缆时。
第三种方式是, 如果事先对内核进行了配置,在发生 panic 时, 就会自动进入 DDB。 显然, 将一台无人看管的服务器的内核进行这样的配置, 不是一项理性的做法。
如果希望启用无人值守的功能, 则可以增加:
options KDB_UNATTENDED
到内核的编译配置文件中, 并重新联编和安装内核。
DDB 的命令和某些 gdb 命令大体类似。 您需要做的第一件事可能是设置断点:
break function-name address
默认情况下, 调试器接受十六进制的数字。 不过, 为了与符号的名字相区分, 以字母 a-f 开头的数字必须带有 0x 前缀 (对其他数字而言, 这是可选的)。 除此之外, 也可以使用简单的表达式, 例如: function-name + 0x103。
要退出调试器并继续执行, 只需输入:
continue
要查看调用堆栈, 则可以使用:
trace
注意: 需要说明的是, 如果您是使用热键进入 DDB, 则内核正在执行中断服务, 因而此时的调用堆栈可能用处不大。
要去掉一处断点, 可以使用:
del del address-expression
第一种形式可以在遇到断点之后使用, 起作用是删除当前的断点。 第二种形式可以用来删除任意的断点, 但您需要精确地指定地址; 这些地址可以通过下面的命令来获得:
show b
或者:
show break
要单步执行内核, 则可以使用:
s
这个命令会跟入函数, 但您也可以让 DDB 跟踪指令的执行, 直到对应的返回语句为止:
n
注意: 这个命令与 gdb 的 next 语句不同; 它更像 gdb 的 finish。 多按几次 n 则表示继续执行。
要检查内存中的数据, 可以用 (下面是一个例子):
x/wx 0xf0133fe0,40 x/hd db_symtab_space x/bc termbuf,10 x/s stringbuf来完成对 字/半字/字节 的访问, 并使用 十六进制/十进制/字符/字符串 的格式来显示。 在逗号后的数字是对象的数量。 要显示接下来的 0x10 项, 可以简单地使用:
x ,10
类似地, 使用
x/ia foofunc,10可以对
foofunc 的前 0x10 条指令进行反汇编,
并同时显示它们相对于 foofunc 起点的偏移量。要修改内存, 应使用 write 命令:
w/b termbuf 0xa 0xb 0 w/w 0xf0010030 0 0
这个命令的修饰参数 (b/h/w) 指定了将要写的数据的尺寸, 其后的第一个表达式表示将要写入的地址, 而余下的责备认为是写入连续内存位置的数据。
如果需要知道寄存器的当前内容, 使用:
show reg
除此之外, 也可以显示单个寄存器的值, 例如:
p $eax并修改之:
set $eax new-value
如果希望从 DDB 调用某个内核函数, 可以简单地使用:
call func(arg1, arg2, ...)
调试器将显示其返回值。
如果想查看 ps(1) 风格的进程表, 使用:
ps
了解了内核出现了什么问题之后, 一般会希望重新启动系统。 您应牢记的一点是, 取决于内核之前出现问题的严重程度, 内核中的某些组件可能已经无法正常工作。 此时, 应执行下列操作之一来关闭和重新启动系统:
panic
这会让内核执行转存操作并重新启动, 这样, 您就可以在之后使用 gdb 进行更高级的分析了。 这个命令通常还需要配合使用一个 continue 语句才能够完成。
call boot(0)
这个命令可能是一种完好地关闭正运行的系统, 对所有磁盘执行 sync() 操作, 并正常重启系统的好办法。
假如内核中的磁盘和文件系统接口没有遭到破坏的话, 这样做能够几乎完全正常地关闭系统。
call cpu_reset()
这是在发生重大问题时的终极解决方法, 其作用与按下复位按钮是一样的。
假如需要简短的命令介绍, 可以使用:
help
我们强烈建议您打印一份 ddb(4) 的联机手册之后再开始调试, 因为在单步执行内核时, 查看联机手册是很麻烦的。
10.5 使用远程 GDB 进行联机内核调试
从 FreeBSD 2.2 开始提供了对这一功能的支持, 实际上, 它也是一种非常灵活的方式。
GDB 很久以前就已经支持 远程调试 了。 这是通过一种非常简单的串口线协议来实现的。 与前面介绍的方法不同, 要使用这种方式, 您需要使用两台计算机。 其中一台用于提供调试环境, 其中包括全部源代码, 以及一份包含全部符号的编译好的内核; 另一台则运行这一内核 (已经脱去了调试信息)。
您应使用 config -g 来配置内核, 并在配置中加入 DDB, 并按通常的方法编译。 由于包含了调试信息,
这样做得到的编译结果会很大。 将这个内核复制到目标机上, 并使用 strip
-x 脱去调试符号, 并使用引导选项 -d 来启动。
用于连接调试主机的目标机上, 应为调试串口设备设置 "flags 080"。 现在, 在调试机上,
进入目标内核的编译目录, 并启动 gdb:
% kgdb kernel GDB is free software and you are welcome to distribute copies of it under certain conditions; type "show copying" to see the conditions. There is absolutely no warranty for GDB; type "show warranty" for details. GDB 4.16 (i386-unknown-freebsd), Copyright 1996 Free Software Foundation, Inc... (kgdb)
用下面的命令初始化远程调试会话 (如果使用的是第一个串口的话):
(kgdb) target remote /dev/cuaa0
现在, 在目标机 (在开始设备检测之前就进入了 DDB), 输入:
Debugger("Boot flags requested debugger")
Stopped at Debugger+0x35: movb $0, edata+0x51bc
db> gdb
DDB 将给出响应:
Next trap will enter GDB remote protocol mode
每次输入 gdb 时, 都会在远程 GDB 与本地 DDB 模式之间切换。 要立即触发一个 trap, 可以简单地输入 s (step)。 您的 GDB 将获得目的内核的控制权:
Remote debugging using /dev/cuaa0
Debugger (msg=0xf01b0383 "Boot flags requested debugger")
at ../../i386/i386/db_interface.c:257
(kgdb)
您可以像使用任何其他 GDB 会话一样进行调试, 包括访问完整的内核, 在 Emacs 窗口中以 gud-模式 来执行 (这会在另一 Emacs 窗口中自动显示源代码), 等等。
10.6 如何调试控制台驱动
由于您需要控制台驱动来运行 DDB, 因此如果控制台驱动本身发生问题,
调试起来就很复杂了。 需要时刻谨记使用串口控制台 (通过修改引导块, 或者在 Boot: 提示符后面指定 -h),
并在第一个串口上挂接一个标准的终端。 DDB 可以在您配置的任何一个控制台驱动上运行,
这也包括串口控制台。
10.7 调试死锁
有时您会遇到一种称为死锁的状况, 此时系统会停止进行有用的工作。 如果希望在此时提供有用的 bug 报告, 您应按照前述的方式使用 ddb(4)。 清在报告中给出与可疑进程有关的 ps 和 trace 输出。
如果可能的话, 请考虑对问题进行更深入的考察。 如果您怀疑死锁发生在 VFS 层上, 则下列选项会有助于找到问题。 您可以在内核编译配置文件中加入
makeoptions DEBUG=-g
options INVARIANTS
options INVARIANT_SUPPORT
options WITNESS
options DEBUG_LOCKS
options DEBUG_VFS_LOCKS
options DIAGNOSTIC
这些选项。 当发生死锁时, 除了 ps 命令的输出之外, 您还应提供
show pcpu、 show allpcpu、 show locks、 show alllocks、 show lockedvnods 以及 alltrace
的输出结果。对于使用线程的进程而言, 要获得有意义的调用栈内容, 还需要使用 thread thread-id 来切换线程栈, 并使用 where 来显示调用栈。
10.8 用于调试的内核选项术语表
本节将对用于调试的编译时内核选项进行简要的术语表式介绍:
-
options KDB: 在内核中联编调试器框架。 这是使用 options DDB 和 options GDB 的先决条件。 它对性能产生的影响很小, 甚至完全不够成影响。 默认情况下, 如果使用这一选项, 在内核发生崩溃时将进入调试器, 而不是自动重启。
-
options KDB_UNATTENDED: 将 sysctl 变量 debug.debugger_on_panic 的默认值改为 0, 这一变量控制在发生崩溃时是否进入调试器。 当内核中没有编入 options KDB 时, 默认的行为是发生崩溃时自动重启系统; 而如果将其编入内核, 则默认行为是崩溃时进入调试器, 除非您同时指定了 options KDB_UNATTENDED。 如果希望将调试器联编进内核, 但又希望系统在无人值守的情况下自动恢复, 则应使用这一选项。
-
options KDB_TRACE: 将 sysctl 变量 debug.trace_on_panic 的默认值改为 1, 这一变量控制调试器是否自动在发生崩溃时自动显示调用�。 如果使用串口或火线控制台, 特别是在配合 options KDB_UNATTENDED 运行时, 这个选项有助于收集一系列基本的调试信息, 而又不会影响系统重启并恢复服务。
-
options DDB: 将控制台调试器, DDB 的支持联编到内核中。 这个交互式调试器能够在系统中可用的任何低级控制台上运行, 这包括显示器控制台、 串口控制台或火线控制台。 它提供了基本的集成调试机制, 例如显示调用�、 列出进程和线程、 显示锁的状态、 VM 状态、 文件系统状态, 以及管理内核内存。 DDB 并不需要在另一台机器上运行任何软件, 也不能直接生成崩溃核心内存转存或使用完整的内核调试符号, 并提供详细的内核运行环境诊断机制。 尽管如此, 许多问题仍可以直接通过 DDB 输出来进行诊断。 这一选项依赖 options KDB。
-
options GDB: 连入远程调试器 GDB 的支持, 它支持通过串口电缆或火线进行操作。 当进入调试器时, 可以挂接 GDB 并观察数据结构的内容、 生成调用�信息等。 在检查某些内核状态时, 这会比使用 DDB 要简单许多, 因为它能够自动生成一些关于内核状态的摘要信息, 例如自动遍历锁的调试信息, 或内核内存管理结构等, 但这种调试需要另一台计算机的参与。 另一方面, GDB 能够配合内核源代码和完整的调试符号使用, 并且了解全部的数据结构定义、 局部变量, 而且可以采用脚本化方式操作。 如果只是在内核核心内存的崩溃转存运行 GDB 的话, 则这一选项并非必需。 此选项依赖 options KDB。
-
options BREAK_TO_DEBUGGER、 options ALT_BREAK_TO_DEBUGGER: 允许控制台上的 break 或 alternative 信号使内核进入调试器。 如果系统在没有发生崩溃时停止响应, 则这是一种很有用的进入调试器的方式。 由于目前的内核上锁机制, 串口控制台产生的 break 信号在进入调试器方面更为可靠, 因而也是推荐的方式。 这一选项造成的性能影响微乎其微。
-
options INVARIANTS: 在内核中联编一系列运行时断言检查和测试, 这些测试会持续地检查内核数据结构的完整性, 以及内核算法的正确性。 这类测试可能会产生很大的性能开销, 因此默认情况下并不会联编进内核, 但它能够提供非常有用的 “遇错即停” 行为, 使得系统在发生潜在问题并破坏内核数据结构之前进入调试器, 从而使问题更容易调试。 这类测试包括对内存进行清零等操作, 以及对释放后使用的检查, 而这些都会显著的提高开销。 这个选项依赖于 options INVARIANT_SUPPORT。
-
options INVARIANT_SUPPORT: 许多 options INVARIANTS 测试需要修改过的数据结构, 或定义额外的内核符号, 此选项将这些加入内核。
-
options WITNESS: 这个选项会启用运行时的锁逆序追踪和验证, 是诊断死锁时的一个十分有用的工具。 WITNESS 会维护一个所持锁的有向图, 并在线程获锁时检查其中是否有 (直接或间接的) 环路。 如果检测到环路, 则会在控制台显示出警告和调用�, 表示可能会发生潜在的死锁现象。 在使用 DDB 命令 show locks、 show witness 以及 show alllocks 时, 必须配合 WITNESS。 这一调试选项会产生显著的性能开销, 但这种性能开销, 可以通过使用 options WITNESS_SKIPSPIN 选项在一定程度上减轻。 关于它的详细介绍, 请参见 witness(4)。
-
options WITNESS_SKIPSPIN: 禁用 WITNESS 对自旋锁的锁序检查。 由于自旋锁在调度器中会频繁地持放, 而调度器事件又经常发生, 因此这一选项会显著地改善运行 WITNESS 系统的性能。 此选项依赖 options WITNESS.
-
options WITNESS_KDB: 将 sysctl 变量 debug.witness.kdb 的默认值改为 1, 使 WITNESS 在发生锁逆序时直接进入调试器, 而不是简单地给出警告。 此选项依赖 options WITNESS。
-
options SOCKBUF_DEBUG: 对 socket 缓冲区进行高代价的运行时一致性检查, 这在调试 socket 问题, 以及查找与 socket 交互的协议和设备驱动中的竞态条件时非常有用。 这一选项会显著地影响网络性能, 而且可能改变设备驱动竞态条件的时序。
-
options DEBUG_VFS_LOCKS: 追踪 lockmgr/vnode 锁的获持点, 并扩充 DDB 的 show lockedvnods 所能提供的信息范围。 这一选项会产生可观的性能影响。
-
options DEBUG_MEMGUARD: 将 malloc(9) 内核内存分配器替换为一个使用 VM 系统, 并能检测释放后读写内存行为的分配器。 关于这一分配器的具体介绍, 请参见 memguard(9)。 这一选项会产生显著的性能影响, 但在调试内核内存损毁问题时会非常有用。
-
options DIAGNOSTIC: 启用附加的、 代价更高的 options INVARIANTS 诊断测试。
第IV部分. 系统结构
- 目录
- 第11章 x86 汇编语言
第11章 x86 汇编语言
本章节由 G. Adam Stanislav <adam@redprince.net>
撰写。 翻译: sunlecn@gmail.com。
11.1 概述
涉及 UNIX 下的汇编语言的相关资料很少。 通常我们都假设几乎没有人希望用到它, 因为不同的 UNIX 可能是在不同的处理器上运行的, 所以为了移植性的考虑所有的东西都应该用 C 来实现。
实际上, C 语言的移植性是非常神秘的。即使 C 程序在不同的 UNIX 之间移植的时候需要进行修改, 但这些修改绝对和在什么处理器上运行无关。 特别明显地是, 这样的程序充满了在编译时对于系统依赖的条件描述。
即使我们希望所有的 UNIX 软件都应该用 C 语言或者是其他的高级语言编写, 但是我们仍然需要掌握汇编语言的程序员: 不然谁将完成 C 语言函数库中直接访问内核的部分?
在本章节,我将尝试着说明如何用汇编语言编写 UNIX 程序,特别是在 FreeBSD 上的程序。
这个章节不会讲解汇编语言的基础知识。现在已经有很多相关的资料了 (如果你想寻找完整的关于汇编语言的在线课程, 请看 Randall Hyde 的 《汇编语言艺术》; 如果你想选择一本书, 那么去看看 Jeff Duntemann 的 《循序渐进学汇编》) 不过, 一旦你掌握了这个章节的内容, 任何汇编语言的程序员, 将能够在 FreeBSD 上高效、快速地编写程序。
Copyright © 2000-2001 G. Adam Stanislav. All rights reserved.
11.2 工具
11.2.1 汇编器
汇编语言编程最重要的工具是汇编器, 它将汇编语言代码转换成机器语言。
在 FreeBSD 中有两个完全不同的汇编器。 一个是 as(1), 使用传统的UNIX汇编语法, 它是随系统发布的。
另外一个是 /usr/ports/devel/nasm。 它使用 Intel 的语法规范, 其最大的好处是可以在许多操作系统上汇编代码。 它需要你单独安装, 不过它是完全免费的。
本章节使用 nasm 的语法规范, 这是因为许多从其他操作系统移植到 FreeBSD 的汇编语言可以更好地被理解。 不过, 坦白地说, 这是因为我更习惯这样的语法规范。
11.3 系统调用
11.3.1 默认的调用规范
通常, FreeBSD 的内核使用 C 语言的调用规范。 此外, 虽然我们使用 int 80h 来访问内核, 但是我们常常通过调用一个函数来执行 int 80h, 而不是直接访问。
这个规范是非常方便的, 比 Microsoft 的 MS-DOS 上使用的规范更加优越。 为什么呢? 因为 UNIX 的规范允许任何语言所写的程序访问内核。
汇编语言也可以这样做, 比如, 我们可以编写一个文件:
kernel:
int 80h ; Call kernel
ret
open:
push dword mode
push dword flags
push dword path
mov eax, 5
call kernel
add esp, byte 12
ret
这是一种非常清晰而易于移植的编码方法。 如果你需要将代码移植到一个使用和 FreeBSD 完全不同中断或参数传递方式的 UNIX 系统, 那么你所需要做的仅仅是改变那一段内核程序。
但是汇编程序员喜欢使用一些技巧来削减程序执行所需的时钟周期数。 以上的例子需要一个
call/ret 组合, 我们可以通过压栈 push 一个额外的双字节来去除它。
open:
push dword mode
push dword flags
push dword path
mov eax, 5
push eax ; Or any other dword
int 80h
add esp, byte 16
在上一个 open 的例子中, 我们放在 EAX 中的数字 5
表示了一个内核函数。
11.3.2 另一种调用规范
FreeBSD 是一个非常灵活的系统。 它提供了访问内核的其他方式。 但是, 如果你要用到它, 你的系统必须安装 Linux emulation。
Linux 是一个类 UNIX 操作系统。 但是,
它的内核在传递参数的时候, 使用和 MS-DOS 相同系统调用规范。 比如在 UNIX 的规范中, 代表内核函数的数字存放在 EAX 中。 但是在 Linux 中, 参数不进行压栈而是存放在 EBX, ECX, EDX, ESI, EDI, EBP:
open:
mov eax, 5
mov ebx, path
mov ecx, flags
mov edx, mode
int 80h
这种做法与 UNIX 的常规做法相比有一个严重的缺点, 至少现在汇编语言程序需要注意的: 每次进行系统调用, 你必须对寄存器的值进行压栈和出栈操作, 这让你的程序变得冗长而效率低下。 因此, FreeBSD 提供给你了一个其他的选择。
如果你确实选择了 Linux 的规范, 你必要让你的系统知道这一点。 在你的程序完成汇编和连接之后, 你需要对可执行文件进行标识:
% brandelf -t Linux filename
11.3.3 你该选择哪个规范?
如果你专门为 FreeBSD 写代码, 你必须使用 UNIX 的规范: 因为它快速, 你可以在寄存器中存取全局变量, 而且不需要进行可执行的标识, 更不需要在你的系统上安装 Linux emulation。
如果你想做一些可以在 Linux 上运行的程序, 并且你打算尽可能地给 FreeBSD 用户提供最有效率地程序。 我将在我讲解完汇编基础之后, 告诉你怎样完成这样地程序。
11.3.4 系统调用号
要通知内核你调用了什么系统服务, 将代表调用的数字放入 EAX 中。 当然, 你需要知道那些系统调用号代表了什么。
11.3.4.1 syscalls 文件
系统调用号列在了 syscalls 文件里面。 locate syscalls 去寻找这个文件的不同格式, 它们都是从 syscalls.master 中自动生成的。
你可以在 /usr/src/sys/kern/syscalls.master 下找到这个描述默认情况下 UNIX 系统调用规范的文件。 如果你需要使用在 Linux emulation 中使用的规范, 请参阅 /usr/src/sys/i386/linux/syscalls.master。
注意: FreeBSD 和 Linux 不仅仅是使用不同的调用规范, 有时候它们也使用不同的系统调用号来表示相同函数。
syscalls.master 描述了如何使用这些调用:
0 STD NOHIDE { int nosys(void); } syscall nosys_args int
1 STD NOHIDE { void exit(int rval); } exit rexit_args void
2 STD POSIX { int fork(void); }
3 STD POSIX { ssize_t read(int fd, void *buf, size_t nbyte); }
4 STD POSIX { ssize_t write(int fd, const void *buf, size_t nbyte); }
5 STD POSIX { int open(char *path, int flags, int mode); }
6 STD POSIX { int close(int fd); }
etc...
最左边的一列告诉我们需要放入 EAX 的数字。
最右边的一列告诉我们那些需要被压栈 push 的参数,
它们的压栈 push 顺序是 从右到左。
11.4 返回值
如果系统调用没有返回一些数值, 那么在很多情况下并没有太多用处。这些返回值包括: 一个打开的文件的文件描述符、 一个从缓存里读取的字节, 或者系统时间等等。
此外, 如果错误出现, 系统需要通知我们。 这些错误包括: 文件不存在、系统资源耗尽,或者我们传递了一个错误的参数等等。
11.4.1 联机手册
传统情况下,寻找 UNIX 下不同系统调用的地方是手册页。 FreeBSD 会在手册页的第2节描述系统调用,有的时候会在第三节。
例如, open(2) 所描述的:
如果执行成功,
open()将返回一个表示文件描述符的非负整数。 如果执行失败, 它会返回-1并且设置errno来标识错误。
刚刚接触 UNIX 和
FreeBSD的汇编程序员或许会马上提出一个难题: 那些 errno
在哪里?我怎么才能找得到它们?
注意: 这些在手册页中展示的信息仅针对 C 语言。 汇编程序员则需要更多的信息。
11.4.2 返回值在哪里?
很不幸, 它有依赖性。。。 大部分系统调用都使用 EAX
但不是所有的系统调用都会这样。 不过当第一次使用系统调用的时候,直接在 EAX 检查返回值是个不错的查找方法。 如果它不在那里,
你再需要深入调查。
注意: 我知道一个
SYS_fork的系统调用将返回值存放在EDX中。而我曾经用过的其他调用都使用EAX存放返回值, 但是我目前还没有用过所有的系统调用。
提示: 如果你哪里都找不到答案, 去学习 libc 代码吧,去看看它如何访问内核的。
11.4.3 哪里可以找到
errno?
实际上,没什么地方。。。
errno 不属于 UNIX
内核, 而是 C 语言中的一部分。 当直接访问内核服务的时候, 错误代码返回到 EAX 中,也就是那个通常用来保存返回值得寄存器。
这个处理方式非常有意义。 如果这里没有错误, 这里就没有错误代码。 如果这里有错误,这里就没有返回值。 使用一个寄存器可以涵盖以上任意一种情况。
11.4.4 判断错误的出现
当使用标准的 FreeBSD 调用规范时,标志位 carry flag
在程序运行成功时被清零,在失败时被置位。
当使用 Linux emulation 模式的时候, EAX
中的有符号数反映了执行结果。 当为非负数时,表示执行成功, 并包含了返回值。 如果失败,
返回值即为负数, 如 -errno。
11.5 建立可移植的代码
一般说来, 可移植性并非汇编语言的长项。 然而, 写出能够在不同平台上执行的汇编代码仍然是可能的事情, 特别是在使用 nasm 的时候。 我曾经写过一个汇编语言函数库, 可以在 Windows 或 FreeBSD 这样不同的操作系统下进行汇编。
所以, 让你的代码在两种不同但是又基于相似的结构的平台上运行是完全可能的。
比如, FreeBSD 是 UNIX 操作系统,Linux 是类UNIX 操作系统。 从一个汇编语言程序员的观点来看, 我只说明三个两者不同的地方: 调用方式, 功能号, 以及返回值的传递方式。
11.5.1 功能号的处理
许多情况下, 两个平台下的功能号是相同的。 当然, 即使它们不一样的时候, 问题也一样容易解决。 方法很简单,就是在代码中用常量替代数字, 这样你可以根据不同的系统结构进行不同的声明:
%ifdef LINUX %define SYS_execve 11 %else %define SYS_execve 59 %endif
11.5.2 编程规范的处理
调用规范和返回值( errno 相关的问题)
可以通过使用宏一起得到解决:
%ifdef LINUX
%macro system 0
call kernel
%endmacro
align 4
kernel:
push ebx
push ecx
push edx
push esi
push edi
push ebp
mov ebx, [esp+32]
mov ecx, [esp+36]
mov edx, [esp+40]
mov esi, [esp+44]
mov ebp, [esp+48]
int 80h
pop ebp
pop edi
pop esi
pop edx
pop ecx
pop ebx
or eax, eax
js .errno
clc
ret
.errno:
neg eax
stc
ret
%else
%macro system 0
int 80h
%endmacro
%endif
11.5.3 与移植相关的其他问题处理
以上的方法可以解决 FreeBSD 和 Linux 之间的代码移植过程。 尽管如此, 一些内核服务之间的差异还是很大。
如果那样的话, 你需要针对那些特殊的调用编写代码, 并且使用针对环境的条件汇编。 不过, 幸运的是, 你的代码所进行地大部分工作不是在调用内核, 所以通常情况下, 你只需要在你的代码中增加一些针对环境的条件片段就可以了。
11.5.4 使用函数库
你可以通过为系统调用编写函数库来完全避免你主程序中的移植性问题。 所以,为 FreeBSD 建议一个独立的函数库吧, 为 Linux 建立另外的一个, 再为其他的操作系统建立这样的函数库。
在你的函数库中,为每一个系统调用编写独立的函数。 (
如果你习惯于传统的汇编语言术语,我们也可以称之为程序) 使用 C
语言传递参数的方式,但是依然使用 EAX 来传递功能号。
如果那样, 你的 FreeBSD 函数库将非常简单, 因为许多看似不同的函数,
实际上都只是同一段代码的不同标签:
sys.open:
sys.close:
[etc...]
int 80h
ret
你的 Linux 函数库需要更多彼此不同的函数。 然而, 尽管如此, 仍可以将系统调用按其参数的个数进行分组:
sys.exit:
sys.close:
[etc... one-parameter functions]
push ebx
mov ebx, [esp+12]
int 80h
pop ebx
jmp sys.return
...
sys.return:
or eax, eax
js sys.err
clc
ret
sys.err:
neg eax
stc
ret
使用函数库的方法起初会看起来很不方便,因为它需要你去建立一个你的程序所依赖的独立的文件。 但是它又有很多优点:首先, 你只需要编写一次, 就可以在你所有的程序中使用。 甚至你可以让其他的汇编程序员或者其他程序使用。 不过, 使用函数库的最大的好处在于: 仅仅需要增加一个新的函数库, 你的程序就可以被任何人移植到其他系统上了。
如果你对使用函数库没有任何概念, 你至少可以将你所有的系统调用放置在一个独立的汇编语言文件中, 然后将它和你的主程序连接。这里,再次强调, 所有的移植程序的程序员所做的,就是建立一个新的对象文件, 然后连接到你的主程序中。
11.5.5 使用头文件
如果你发布的软件中包含代码, 你可以在你包含代码的地方使用宏, 将它们放置在一个独立的文件中。
移植你的软件的人只需要简单地写一个头文件, 不需要外部的对象文件。 你的程序将不加修改地被移植。
注意: 这个就是我们将在本章中使用的方法。 我们将把我们的头文件命名为 system.inc, 然后在我们使用新的系统调用时增加它。
我们从声明标准文件描述符开始,编写我们的 system.inc :
%define stdin 0 %define stdout 1 %define stderr 2
接下来,为每个系统调用指定符号名:
%define SYS_nosys 0 %define SYS_exit 1 %define SYS_fork 2 %define SYS_read 3 %define SYS_write 4 ; [etc...]
接下来增加一个短小的非全局子程序, 并给它其一个够长的名字, 以避免我们不慎在代码中使用同样的名字。
section .text
align 4
access.the.bsd.kernel:
int 80h
ret
我们建立了一个带有一个参数的宏, 其系统调用号为:
%macro system 1
mov eax, %1
call access.the.bsd.kernel
%endmacro
最后, 我们为每一个系统调用建立了一个宏。 这些宏不带有任何参数。
%macro sys.exit 0
system SYS_exit
%endmacro
%macro sys.fork 0
system SYS_fork
%endmacro
%macro sys.read 0
system SYS_read
%endmacro
%macro sys.write 0
system SYS_write
%endmacro
; [etc...]
继续, 把它添加到你的编辑器中, 然后把它保存为 system.inc 。 我们将随着讨论得深入,将更多的系统调用添加进来。
11.6 编写第一个程序
请为我们第一个程序 理所当然的 Hello, World! 做好准备。
1: %include 'system.inc' 2: 3: section .data 4: hello db 'Hello, World!', 0Ah 5: hbytes equ $-hello 6: 7: section .text 8: global _start 9: _start: 10: push dword hbytes 11: push dword hello 12: push dword stdout 13: sys.write 14: 15: push dword 0 16: sys.exit
它的工作如下: 第1行,它包含了 system.inc 中的定义、宏和代码。
第3-5行是数据段: 数据段从第3行开始。第4行中包含了字符串 "Hello, World!"
和一个换行符 (0Ah)。
第5行中,我们建立了一个常量来表示第四行字符串中包含字节的数目。
第7-16行是代码段。 请注意 FreeBSD 对可执行文件使用 elf 格式, 这需要每个程序从标签 _start 开始执行, 或者更准确地说,是连接器对程序的要求。
这个标签需要是全局的。
第10-13行,程序将把 字符串 hello 中的 hbytes 个字符写到标准输出 stdout
中。
第15-16行,程序将结束并返回 0。 系统调用 SYS_exit 没有返回值,所以程序在这里结束。
注意: 如果你以前有 MS-DOS 汇编程序的背景, 你可能习惯直接对显示硬件进行写操作。 在 FreeBSD, 或者其它 UNIX 中,你也不用担心。 到目前为止,你所要关心地是向一个叫 stdout 的文件进行写操作。这个叫 stdout 的文件, 可以是显示器,或者是一个 telnet 终端,或者是一个真实的文件,甚至可能是对另外一个程序的输入。
11.6.1 汇编你的代码
在编辑器里输入这些代码 (不包括那些行号), 然后保存为名叫 hello.asm 的文件。 现在你需要做的是使用 nasm 对代码进行汇编。
11.6.1.1 安装 nasm
如果你没有 nasm,请输入:
% su Password:your root password # cd /usr/ports/devel/nasm # make install # exit %
如果你不想保留 nasm 的代码,你可以使用 make install clean 来代替上面提到的 make install。
不过通过任何一种方法, FreeBSD 将自动从互联网上下载 nasm 的代码, 编译它, 并将它安装在你的系统上。
注意: 如果您的系统不是 FreeBSD, 则需要从 nasm 的 主页 来获得它。 在其他系统上这个程序也能够汇编针对 FreeBSD 的代码。
现在你可以汇编,连接,运行代码了:
% nasm -f elf hello.asm % ld -s -o hello hello.o % ./hello Hello, World! %
11.7 编写 UNIX® 过滤程序
过滤程序是 UNIX 中一种常见的应用程序, 它从标准输入 stdin 读入数据, 然后进行相关处理, 最后将结果写到标准输出 stdout。
在本节中, 我们将编写一个简单的过滤程序, 从而学习如何从标准输入 stdin 和标准输出 stdout 进行读写。 这个过滤程序将按字节把输入转换成16进制的数字, 并在每个数字的后面添加一个空格。
%include 'system.inc'
section .data
hex db '0123456789ABCDEF'
buffer db 0, 0, ' '
section .text
global _start
_start:
; read a byte from stdin
push dword 1
push dword buffer
push dword stdin
sys.read
add esp, byte 12
or eax, eax
je .done
; convert it to hex
movzx eax, byte [buffer]
mov edx, eax
shr dl, 4
mov dl, [hex+edx]
mov [buffer], dl
and al, 0Fh
mov al, [hex+eax]
mov [buffer+1], al
; print it
push dword 3
push dword buffer
push dword stdout
sys.write
add esp, byte 12
jmp short _start
.done:
push dword 0
sys.exit
在数据段, 我们建立一个叫做 hex 的数组,
它包含了按照升序排列的16进制数字。 在这个数组的后面, 是一个输入输出都会用到的缓存。
缓存的头两个字节被初始化设置为 0。
这里,我们将输出两个16进制数字( 第一个字节也同样是我们读取输入的地方 )。
第三个字节是空格。
代码段由四部分组成: 读入一字节, 转换成16进制数字, 输出结果, 结束程序。
为了读入一字节的数据, 我们命令系统从标准输入 stdin
中读出一个字节的数据, 然后将它存储在缓存 buffer
的第一个字节中。 系统将把返回值存放在寄存器 EAX 中。
返回值如果为 1 则代表有数据输入, 如果为 0, 则表示没有数据输入。 因此, 我们检查 EAX 中的数值,如果它为 0
我们的程序将跳转至 .done,
否则我们的程序将继续执行操作。
注意: 出于简单实现程序基本功能的目的, 我们忽略了针对某些可能发生的错误的处理。
16进制转换程序首先从缓存 buffer 中读出一字节的值,
并将其写入 EAX, 或者, 更确切地说, 这部分是将数据写入
AL, 并把 EAX 的其他部分清零。
同时, 也将数据复制到 EDX 中,
因为我们需要独立转换高4位和低4位的数据。 最后, 把结果存放在和缓存的头两个字节中。
下面, 我们将让系统将缓存中的这三个字节, 就是两个16进制数字和一个空格, 输出到标准输出 stdout 中。 然后我们的程序将跳转至程序开始处,处理下一个字节。
一旦没有输入, 我们将命令系统终止程序, 返回0。 通常情况下, 使用0作为返回值代表着程序已经执行成功。
接下来, 将程序保存到名为 hex.asm 的文件中, 然后输入以下内容 (符号 ^D 代表在按下控制键的同时, 按下键盘 D):
% nasm -f elf hex.asm % ld -s -o hex hex.o % ./hex Hello, World! 48 65 6C 6C 6F 2C 20 57 6F 72 6C 64 21 0A Here I come! 48 65 72 65 20 49 20 63 6F 6D 65 21 0A ^D %
注意: 如果你是从 MS-DOS 上转到 UNIX 的程序员, 你会很奇怪为什么每行结束的时候没有使用
0D 0A而是使用了0A。 这是因为 UNIX 使用的不是 cr/lf, 而是换行符号, 也就是是16进制数字0A所代表的字符来表示换行。
我们能让它看起来更好吗?当然,很明显的一个问题,
当我们转换了一行文字后,我们的输入不再处在行开始的位置。 我们可以修改它,让它在每个 0A 后输出一个新行, 而不是输出一个空格:
%include 'system.inc'
section .data
hex db '0123456789ABCDEF'
buffer db 0, 0, ' '
section .text
global _start
_start:
mov cl, ' '
.loop:
; read a byte from stdin
push dword 1
push dword buffer
push dword stdin
sys.read
add esp, byte 12
or eax, eax
je .done
; convert it to hex
movzx eax, byte [buffer]
mov [buffer+2], cl
cmp al, 0Ah
jne .hex
mov [buffer+2], al
.hex:
mov edx, eax
shr dl, 4
mov dl, [hex+edx]
mov [buffer], dl
and al, 0Fh
mov al, [hex+eax]
mov [buffer+1], al
; print it
push dword 3
push dword buffer
push dword stdout
sys.write
add esp, byte 12
jmp short .loop
.done:
push dword 0
sys.exit
我们将空格存储在寄存器 CL 中。 这样做不会导致问题,
因为与 Microsoft Windows
不同, UNIX 系统调用, 除返回值之外,
并不修改其它寄存器。
所以我们只需要把数值送入 CL 一次即可。
因此我们添加了一个新的标签 .loop, 在下一个字节处理的时候,
跳转到那里,而不是回到 _start。 我们也同样增加了一个 .hex 标签, 这样对第三个字节, 我们既可以赋值为空格,
又可以换行符号。
如果你想在 hex.asm 中反映这些变化,请输入:
% nasm -f elf hex.asm % ld -s -o hex hex.o % ./hex Hello, World! 48 65 6C 6C 6F 2C 20 57 6F 72 6C 64 21 0A Here I come! 48 65 72 65 20 49 20 63 6F 6D 65 21 0A ^D %
这样看起来就好了一些。 但是程序的效率还不高! 我们针对一个字节, 进行了两次系统调用 (一次是读取, 另一次是输出)
11.8 缓存 I/O
通过使用输入输出缓存, 我们可以提高代码的效率。 我们可以建立一个输入缓存, 并一次读入一系列的字节。 然后, 我们再一个接一个地从缓存中提取它们。
同样, 我们可以建立一个输出缓存。 把我们的输出存在里面,直到添满。 同时, 我们将让内核将缓存的内容写到标准输出 stdout 上。
程序将在没有输入的时候结束。 但是我们仍然需要让内核再向标准输出 stdout 进行最后一次写操作, 否则一些内容将留在缓存中, 永不输出。 别忘记这个操作, 否则你将会困惑为什么你的程序丢失了一些应有的输出。
%include 'system.inc'
%define BUFSIZE 2048
section .data
hex db '0123456789ABCDEF'
section .bss
ibuffer resb BUFSIZE
obuffer resb BUFSIZE
section .text
global _start
_start:
sub eax, eax
sub ebx, ebx
sub ecx, ecx
mov edi, obuffer
.loop:
; read a byte from stdin
call getchar
; convert it to hex
mov dl, al
shr al, 4
mov al, [hex+eax]
call putchar
mov al, dl
and al, 0Fh
mov al, [hex+eax]
call putchar
mov al, ' '
cmp dl, 0Ah
jne .put
mov al, dl
.put:
call putchar
jmp short .loop
align 4
getchar:
or ebx, ebx
jne .fetch
call read
.fetch:
lodsb
dec ebx
ret
read:
push dword BUFSIZE
mov esi, ibuffer
push esi
push dword stdin
sys.read
add esp, byte 12
mov ebx, eax
or eax, eax
je .done
sub eax, eax
ret
align 4
.done:
call write ; flush output buffer
push dword 0
sys.exit
align 4
putchar:
stosb
inc ecx
cmp ecx, BUFSIZE
je write
ret
align 4
write:
sub edi, ecx ; start of buffer
push ecx
push edi
push dword stdout
sys.write
add esp, byte 12
sub eax, eax
sub ecx, ecx ; buffer is empty now
ret
现在我们的程序有了第三个部分,名字叫 .bss。
这个部分不会包含在我们可执行文件里, 因此不会被初始化。 我们需要用 resb 代替 db。
它仅仅为我们保留了指定大小的未初始化内存。
我们将充分利用系统不会修改寄存器这个优点:我们为那些可能存储在 .data 数据段里的全局变量使用寄存器。 和 Microsoft
将参数直接传递进寄存器的方式相比, UNIX
规范中将参数存放在堆栈里的方式更加高级。 因为我们将更自由得使用寄存器。
我们将 EDI 和 ESI
当作指针使用, 以次来对下一个字节进行读写操作。同时,我们使用 EBX 和 ECX
来保存两个缓存里字节的数量。 因此,我们知道什么时候该对系统停止读写操作。
我们来看看它是怎样工作的?
% nasm -f elf hex.asm % ld -s -o hex hex.o % ./hex Hello, World! Here I come! 48 65 6C 6C 6F 2C 20 57 6F 72 6C 64 21 0A 48 65 72 65 20 49 20 63 6F 6D 65 21 0A ^D %
在我们输入 ^D 前, 程序没有输出,这个和我们的预计不符。 不过修复很简单, 插入三行代码, 让程序在我们换行的时候, 每次都有输出就可以了。 我用 > 标记了这三行 ( 请不要将 > 加入你的代码中)。
%include 'system.inc'
%define BUFSIZE 2048
section .data
hex db '0123456789ABCDEF'
section .bss
ibuffer resb BUFSIZE
obuffer resb BUFSIZE
section .text
global _start
_start:
sub eax, eax
sub ebx, ebx
sub ecx, ecx
mov edi, obuffer
.loop:
; read a byte from stdin
call getchar
; convert it to hex
mov dl, al
shr al, 4
mov al, [hex+eax]
call putchar
mov al, dl
and al, 0Fh
mov al, [hex+eax]
call putchar
mov al, ' '
cmp dl, 0Ah
jne .put
mov al, dl
.put:
call putchar
> cmp al, 0Ah
> jne .loop
> call write
jmp short .loop
align 4
getchar:
or ebx, ebx
jne .fetch
call read
.fetch:
lodsb
dec ebx
ret
read:
push dword BUFSIZE
mov esi, ibuffer
push esi
push dword stdin
sys.read
add esp, byte 12
mov ebx, eax
or eax, eax
je .done
sub eax, eax
ret
align 4
.done:
call write ; flush output buffer
push dword 0
sys.exit
align 4
putchar:
stosb
inc ecx
cmp ecx, BUFSIZE
je write
ret
align 4
write:
sub edi, ecx ; start of buffer
push ecx
push edi
push dword stdout
sys.write
add esp, byte 12
sub eax, eax
sub ecx, ecx ; buffer is empty now
ret
现在看看它运行的结果:
% nasm -f elf hex.asm % ld -s -o hex hex.o % ./hex Hello, World! 48 65 6C 6C 6F 2C 20 57 6F 72 6C 64 21 0A Here I come! 48 65 72 65 20 49 20 63 6F 6D 65 21 0A ^D %
看来程序运行得不错!
注意: 这样对缓存 I/O 的操作存在着潜在危险。 我会在说明完 缓存的缺陷 后,讨论并修改它。
11.8.1 如何将字符放回输入流
警告: 这可能是一个较为进阶的话题, 熟悉编译理论的程序员可能会对此有兴趣。 如果愿意的话, 您可以 直接跳转到下一节, 以后再阅读这一部分。
尽管我们的示范程序并不需要它, 但更复杂一些的过滤器可能会用到。 换言之, 这些过滤器可能需要知道下一个字符 (甚至接下来的几个字符) 是什么。 如果下一个字符是某个特定的值, 则它是当前短语 (token) 的一部分, 反之则可能不是。
例如, 您可能正对输入流进行语义串的词法分析 (例如, 实现某种语言的编译器): 如果一个字符跟着另一个字符或数字, 则后面这个字符是正在处理的短语的一部分。 如果这个字符后面是空格, 或某个其它的值, 则它就不是当前短语的一部分了。
这带来了一个很有意思的问题: 如何将接下来的这个字符送回输入流, 使之能够在稍后被重新读取?
一种可行的方法是将其保存到一个字符变量中, 并设置一个标志。 我们可以修改 getchar 使之检查这一标志, 如果这个标志被置位,
则从变量而非输入缓冲区中获取字符, 并复位标志。 不过, 很显然, 这会拖慢我们的脚步。
C 语言中有一个 ungetc() 函数,
它正是用于实现这个目的的。 那么, 有没有办法在我们的代码中迅速实现这一函数呢?
在阅读下一节之前, 希望您能回到前面, 并查看 getchar 过程,
并思考您是否能找到一个漂亮且快捷的解决方案。 接着回到这里来看看我的解法。
将字符放回流的关键是, 如何获取开始的字符:
首先, 我们会通过检查 EBX
的值来检测输入缓冲区是否为空。 如果它是零, 则调用 read
过程。
如果有可用的字符, 则使用 lodsb, 接着对 EBX 的值做递减。 lodsb
指令实际上相当于:
mov al, [esi]
inc esi
我们拿到的这个字节会保留在缓冲区中, 直到下次调用 read 为止。 尽管我们不知道这会在何时发生, 但我们知道它不会在下次
getchar 之前。 因此, 要将读取的最后一个字节 “还给” 流,
我们需要做的就是将 ESI 的值递减, 并使 EBX 的值递增:
ungetc:
dec esi
inc ebx
ret
但是, 一定要小心! 如果我们每次只向前读取一个字符的话, 这样做没有任何问题。
但是如果我们会读取多个字符, 并多次调用 ungetc 的话,
有时就会出问题了 (而且会很难调试)。 为什么呢?
这是因为 getchar 并不必然调用 read, 所有预先读入的字符仍会出于缓冲区, 而我们的 ungetc 也会毫无问题地运行。 但是如果 getchar 调用了 read,
则缓冲区的内容就会随之变化。
我们可以认为 ungetc 一定能在使用 getchar 读入的最后一个字符上正确工作,
但在这之前的则没有任何保证。
如果您的程序需要一次读取多个字节, 则有两个选择:
如果可能的话, 修改程序使其一次只向前读最多一个字符。 这是最简单的办法。
如果没办法这样做, 首先要确定程序最多会向流交还多少各字符。 保险起见,
适当地增大这个数字, 最好是 16 的整数倍 ── 使其能够对齐。 接着, 修改您的代码中的 .bss 节, 并在输入缓冲区之前建立一个小的 “预留” 缓冲,
类似下面这样:
section .bss
resb 16 ; or whatever the value you came up with
ibuffer resb BUFSIZE
obuffer resb BUFSIZE
您还需要修改 ungetc 以便将还回的字符放入 AL:
ungetc:
dec esi
inc ebx
mov [esi], al
ret
经过这样的修改, 您就可以安全地调用最多 17 次 ungetc
了 (第一次调用仍会使用输入缓冲, 而余下的 16 次则有可能在输入缓冲, 也可能在 “预留缓冲”
中)。
11.9 命令行参数
如果我们的 hex 程序能读取通过命令行传给它的输入输出文件名, 也就是如果它能处理命令行参数的话, 那它就更好用了。 但是, 这些参数在哪里呢?
在 UNIX 系统启动程序之前, 它会将一些数据 push 到堆栈中, 接着跳转到程序的 _start 标签。 是的, 我说的是跳转而不是调用。 这意味着,
这些数据可以通过读取 [esp+offset], 或更简单的 pop 得到。
�顶的值包含了命令行参数的个数。 传统上它叫做 argc, 表示 “argument count”。
接下来是 argc 个命令行参数。 传统上这些称为 argv, 表示 “argument value(s)”。 这样, 我们便得到了 argv[0]、 argv[1]、 ...、 argv[argc-1]。
这些并不是实际的参数, 而是指向这些参数的指针, 也就是实际参数的内存地址。 参数本身是以
NUL-结尾的字符串形式存放的。
argv 表以一 NULL 指针结束, 这个指针的值就是 0。 还有一些其它的数据, 但前面这些已经足以让我们达到目的了。
注意: 如果你以前在 MS-DOS 环境下编程, 现在的主要的区别就是每个参数都在不同的string里头。第二个不同点就是对于参数数量没有实际的限制。
通过这些知识的武装,我们几乎可以立即开始下一个版本的 hex.asm 了。 首先,不论如何,我们需要在 system.inc 增加一些代码:
首先,为我们的系统调用编号清单增加两个新的入口:
%define SYS_open 5 %define SYS_close 6
接下来在文件尾部增加两个新的宏:
%macro sys.open 0
system SYS_open
%endmacro
%macro sys.close 0
system SYS_close
%endmacro
然后就是我们改过的源码:
%include 'system.inc'
%define BUFSIZE 2048
section .data
fd.in dd stdin
fd.out dd stdout
hex db '0123456789ABCDEF'
section .bss
ibuffer resb BUFSIZE
obuffer resb BUFSIZE
section .text
align 4
err:
push dword 1 ; return failure
sys.exit
align 4
global _start
_start:
add esp, byte 8 ; discard argc and argv[0]
pop ecx
jecxz .init ; no more arguments
; ECX contains the path to input file
push dword 0 ; O_RDONLY
push ecx
sys.open
jc err ; open failed
add esp, byte 8
mov [fd.in], eax
pop ecx
jecxz .init ; no more arguments
; ECX contains the path to output file
push dword 420 ; file mode (644 octal)
push dword 0200h | 0400h | 01h
; O_CREAT | O_TRUNC | O_WRONLY
push ecx
sys.open
jc err
add esp, byte 12
mov [fd.out], eax
.init:
sub eax, eax
sub ebx, ebx
sub ecx, ecx
mov edi, obuffer
.loop:
; read a byte from input file or stdin
call getchar
; convert it to hex
mov dl, al
shr al, 4
mov al, [hex+eax]
call putchar
mov al, dl
and al, 0Fh
mov al, [hex+eax]
call putchar
mov al, ' '
cmp dl, 0Ah
jne .put
mov al, dl
.put:
call putchar
cmp al, dl
jne .loop
call write
jmp short .loop
align 4
getchar:
or ebx, ebx
jne .fetch
call read
.fetch:
lodsb
dec ebx
ret
read:
push dword BUFSIZE
mov esi, ibuffer
push esi
push dword [fd.in]
sys.read
add esp, byte 12
mov ebx, eax
or eax, eax
je .done
sub eax, eax
ret
align 4
.done:
call write ; flush output buffer
; close files
push dword [fd.in]
sys.close
push dword [fd.out]
sys.close
; return success
push dword 0
sys.exit
align 4
putchar:
stosb
inc ecx
cmp ecx, BUFSIZE
je write
ret
align 4
write:
sub edi, ecx ; start of buffer
push ecx
push edi
push dword [fd.out]
sys.write
add esp, byte 12
sub eax, eax
sub ecx, ecx ; buffer is empty now
ret
现在我们在 .data 区里头有了两个新的变量 fd.in 和 fd.out.
我们把输入输出文件描述符放在这.
我们还在 .text 区里用 [fd.in] 和 [fd.out] 替换了指向 stdin 和 stdout 的引用。.
现在,.text
段以一个简单的错误处理程序开始,――这个程序除了退出程序时返回 1 之外啥都不干。 该错误处理程序在 _start 之前,由此我们一旦碰到错误,距离会很近。
很自然, 这个程序还是从 _start 开始执行 首先,我们把
argc 和 argv[0]
从栈中移走:在这个程序里头,他们对我们没意义。
将 argv[1] 出栈, 放到 ECX 。这个寄存器很适合于指针,就如同我们把 NULL 指针用 jecxz 处理。 如果 argv[1]
不为空,我们尝试打开第一个参数中的文件。否则我们将照常继续程序:从 stdin 中读取,写入 stdin 。
假设我们还是在打开文件时候失败 (比如文件不存在),跳转到错误处理然后退出。
如果一切顺利,
我们现在可以检查第二个参数。假设文件存在,我们就带开输出文件。否则,把输出送到 stdout。
如果在打开输出文件时候失败(比如文件已经存在但是我们没有写权限),那我们就再来一次错误处理。
剩下的代码跟之前一样,除开我们在退出之前关闭了输入和输出,如前所述,我们使用的是
[fd.in] and [fd.out] 。
然后768 字节大小的可执行文件到手。
我们是否可以进一步改进?理所当然!每个程序都可以改进。以下是一些我们可以做点啥的想法:
-
我们的错误处理是否输出信息到
stderr. -
把错误处理加入
read和write函数。 -
当我们打开文件用于输入时,关闭
stdin, 反之(输出时)关闭stdout。 -
增加命令行参数,比如
-i和-o, 这样我们就能用任何次序列出输入和输出文件,或者从stdin读入然后写入某个文件。 -
当命令行参数不正确的时候,打印一份帮助。
I shall leave these enhancements as an exercise to the reader: You already know everything you need to know to implement them.
11.10 UNIX 中的环境
UNIX 中一个重要的概念就是环境, 环境中定义了许多 环境变量。 一些是由系统设置的, 一些则由你自己, 或者是由 shell, 再不然就是载入其它程序的进程设置的。
11.10.1 如何找到环境变量
我曾经说过,当一个程序开始执行的时候, 堆栈包含了参数 argc 并且在 argc 之后包含了 argv 数组, 或者其他的一些东西。这些所谓的其他的东西,是所 环境 或者更确切的说是以 NULL 结尾的指向
环境变量 的指针数组。 这通常称作
env。
env 和 argv
的结构是相同的, 以 NULL ( 0 )结尾的一系列的内存地址。
在这种情况下,不存在 "envc" ── 我们将通过查找最后的 NULL
来定位数组的结尾。
变量常常以 name=value 的形式表现, 但是有的时候 =value 的部分会遗失。 我们需要考虑到这样的情况发生的可能性。
11.10.2 webvars
我可以给你展示一些如 UNIX env 命令一样输出环境变量的代码。 但是我想通过写一个简单的汇编 CGI 程序来说明, 将更有意义。
11.10.2.1 通用网关接口(CGI): 一个概述
在我的站点上, 我有一个 详细CGI手册, 但这里有一个关于 CGI 的精简概述:
-
网络服务器根据已经设定的 环境变量 来和 CGI 程序进行通信。
-
CGI 程序向标准输出 stdout 进行输出。 而网络服务器从那里读取程序的输出。
-
它必须以 HTTP 头为开始,并在随后空两行。
-
然后, 它可以打印 HTML 代码, 或者其他由 CGI 产生的数据。
注意: 根据网络服务器的不同,当一些 环境变量 使用标准名称的时候,其他的一些会产生变化。 因此,这使得 webvars 成为一个非常有用的诊断工具。
11.10.2.2 代码
我们的 webvars 程序, 将发送 HTTP 的头和一些 HTML 的标记, 然后它将一个接一个得读取 环境变量, 然后将它们输出在网页中。
代码如下, 我在代码中添加了注解:
;;;;;;; webvars.asm ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;
; Copyright (c) 2000 G. Adam Stanislav
; All rights reserved.
;
; Redistribution and use in source and binary forms, with or without
; modification, are permitted provided that the following conditions
; are met:
; 1. Redistributions of source code must retain the above copyright
; notice, this list of conditions and the following disclaimer.
; 2. Redistributions in binary form must reproduce the above copyright
; notice, this list of conditions and the following disclaimer in the
; documentation and/or other materials provided with the distribution.
;
; THIS SOFTWARE IS PROVIDED BY THE AUTHOR AND CONTRIBUTORS ``AS IS'' AND
; ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
; IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
; ARE DISCLAIMED. IN NO EVENT SHALL THE AUTHOR OR CONTRIBUTORS BE LIABLE
; FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
; DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS
; OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
; HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
; LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY
; OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
; SUCH DAMAGE.
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;
; Version 1.0
;
; Started: 8-Dec-2000
; Updated: 8-Dec-2000
;
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
%include 'system.inc'
section .data
http db 'Content-type: text/html', 0Ah, 0Ah
db '<?xml version="1.0" encoding="UTF-8"?>', 0Ah
db '<!DOCTYPE html PUBLIC "-//W3C/DTD XHTML Strict//EN" '
db '"DTD/xhtml1-strict.dtd">', 0Ah
db '<html xmlns="http://www.w3.org/1999/xhtml" '
db 'xml.lang="en" lang="en">', 0Ah
db '<head>', 0Ah
db '<title>Web Environment</title>', 0Ah
db '<meta name="author" content="G. Adam Stanislav" />', 0Ah
db '</head>', 0Ah, 0Ah
db '<body bgcolor="#ffffff" text="#000000" link="#0000ff" '
db 'vlink="#840084" alink="#0000ff">', 0Ah
db '<div class="webvars">', 0Ah
db '<h1>Web Environment</h1>', 0Ah
db '<p>The following <b>environment variables</b> are defined '
db 'on this web server:</p>', 0Ah, 0Ah
db '<table align="center" width="80" border="0" cellpadding="10" '
db 'cellspacing="0" class="webvars">', 0Ah
httplen equ $-http
left db '<tr>', 0Ah
db '<td class="name"><tt>'
leftlen equ $-left
middle db '</tt></td>', 0Ah
db '<td class="value"><tt><b>'
midlen equ $-middle
undef db '<i>(undefined)</i>'
undeflen equ $-undef
right db '</b></tt></td>', 0Ah
db '</tr>', 0Ah
rightlen equ $-right
wrap db '</table>', 0Ah
db '</div>', 0Ah
db '</body>', 0Ah
db '</html>', 0Ah, 0Ah
wraplen equ $-wrap
section .text
global _start
_start:
; First, send out all the http and xhtml stuff that is
; needed before we start showing the environment
push dword httplen
push dword http
push dword stdout
sys.write
; Now find how far on the stack the environment pointers
; are. We have 12 bytes we have pushed before "argc"
mov eax, [esp+12]
; We need to remove the following from the stack:
;
; The 12 bytes we pushed for sys.write
; The 4 bytes of argc
; The EAX*4 bytes of argv
; The 4 bytes of the NULL after argv
;
; Total:
; 20 + eax * 4
;
; Because stack grows down, we need to ADD that many bytes
; to ESP.
lea esp, [esp+20+eax*4]
cld ; This should already be the case, but let's be sure.
; Loop through the environment, printing it out
.loop:
pop edi
or edi, edi ; Done yet?
je near .wrap
; Print the left part of HTML
push dword leftlen
push dword left
push dword stdout
sys.write
; It may be tempting to search for the '=' in the env string next.
; But it is possible there is no '=', so we search for the
; terminating NUL first.
mov esi, edi ; Save start of string
sub ecx, ecx
not ecx ; ECX = FFFFFFFF
sub eax, eax
repne scasb
not ecx ; ECX = string length + 1
mov ebx, ecx ; Save it in EBX
; Now is the time to find '='
mov edi, esi ; Start of string
mov al, '='
repne scasb
not ecx
add ecx, ebx ; Length of name
push ecx
push esi
push dword stdout
sys.write
; Print the middle part of HTML table code
push dword midlen
push dword middle
push dword stdout
sys.write
; Find the length of the value
not ecx
lea ebx, [ebx+ecx-1]
; Print "undefined" if 0
or ebx, ebx
jne .value
mov ebx, undeflen
mov edi, undef
.value:
push ebx
push edi
push dword stdout
sys.write
; Print the right part of the table row
push dword rightlen
push dword right
push dword stdout
sys.write
; Get rid of the 60 bytes we have pushed
add esp, byte 60
; Get the next variable
jmp .loop
.wrap:
; Print the rest of HTML
push dword wraplen
push dword wrap
push dword stdout
sys.write
; Return success
push dword 0
sys.exit
这个代码将生成一个1396字节的可执行文件, 程序的大部分是数据: 比如那些我们需要发送的 HTML 标记。
然后如往常一样, 编译连接:
% nasm -f elf webvars.asm % ld -s -o webvars webvars.o
如果你要使用它,将它载入你的服务器。 根据你网络服务器的设置, 你可能需要将它放入一个叫 cgi-bin 的目录, 或者重命名一个以 .cgi 结尾的文件名。
然后,你需要用浏览器来看它的输出。 如果要看在我的网络服务器的输出,请访问 http://www.int80h.org/webvars/。 如果对显示密码保护的网络文件目录的环境变量有兴趣, 访问 http://www.int80h.org/private/, 用户名为 asm, 密码为 programmer。
11.11 文件处理
我们已经做过一些基本的文件处理工作了: 我们可以打开或者关闭一个文件, 可以通过缓存对一个文件进行读取或者写入。 但是, 当处理文件的时候, UNIX 提供了更多的功能。 我们将在这个章节中尝试使用一些功能, 并将以一个非常漂亮的文件转换工具作为结束。
当然, 我们是从后往前完成这个文件转换工具的。 因为在通常情况下, 如果我们已经知道我们要实现些什么, 那么我们的程序将完成得更加容易。
我最早为 UNIX 所编写的程序中,有一个叫 tuc 的文件格式转换程序, 可以将其他操作系统中的文本文件转化为 UNIX 的文本文件。 也就是说, 它将不同的行结束符, 转换换行符为文件结束符, 来对应 UNIX 的规范。 也可以将 UNIX 的文本文件转化为 DOS 格式的文本文件。
我虽然广泛得使用我的 tuc 程序, 但是仅仅限于从其他操作系统向 UNIX 转换。 所以, 我希望它能覆盖原来的文件,而不是将结果输出到其他的文件中。 大多数时候, 我是这样使用它的:
% tuc myfile tempfile % mv tempfile myfile
所以最好能有一个叫 ftuc 的程序, 可以这样使用:
% ftuc myfile
接下来, 我们将用汇编完成 ftuc, ( 最开始的 tuc 是C程序 ) 并学习进程中多种面向文件的内核服务。
你可能感觉这个程序很简单,不过是将输车删除而已。
如果你回答是肯定的, 那么想一想: 这个方法虽然对于 MS DOS 的文件, 乃至大多数情况下都适用, 不过有时候也会有失败的时候。
问题是, 并不是所有的非 UNIX 的文本文件一个回车符带一个换行符结尾。 有些只使用回车符, 有些将几个空行合并为一个回车符和若干个换行符, 等等。
一个文件转换程序需要能够处理所有可能出现的结尾:
-
carriage return / line feed
-
carriage return
-
line feed / carriage return
-
line feed
它也需要在上面的基础上,处理那些使用行合并的文件。 ( 比如, 一个回车带多个换行符)
11.11.1 有限状态自动机
这些问题可以很容易地通过一种名为 有限状态自动机 的技术来解决, 这种技术先前是由设计数字电路的人们发明的。 有限状态自动机 是一种其输出不仅取决于输入, 并且还取决于之前的输入, 也就是其状态的数字电路。 微处理器便是一种 有限状态自动机 的例子: 我们使用的汇编语言代码, 有些会对应于单字节的机器指令, 而另一些则对应于多字节机器指令。 微处理器会从内存中逐个字节地抓取指令, 而在这个过程中, 有些只是简单地改变处理器状态, 而并不产生个输出。 当完成了整个机器指令的抓取之后, 微处理器才会产生输出, 或改变寄存器的值, 等等。
正因为如此, 所有的软件, 对微处理器而言, 其实都是一系列的状态指令。 因而, 有限状态自动机 的概念对于软件设计而言也很有用。
我们将文本文件转换成许设计为一个包含三个状态的 有限状态自动机。 我们可以把这三个状态称作状态 0-2, 不过为了明确起见, 将它们符号化为:
-
ordinary -
cr -
lf
我们的程序开始时处于 ordinary 状态。 在这个状态中,
程序的动作取决于其输入:
-
如果输入是除了回车符和换行符之外的任何其他字符, 则这输入会直接送到输出, 同时程序状态保持不变。
-
如果输入是回车符, 则程序状态变为
cr。 而输入则被丢弃, 也就是说不输入任何东西。 -
如果输入是换行符, 则程序状态变为
lf。 同时丢弃输入内容。
如够程序进入了 cr 状态, 说明之前的输出是回车符,
并且还没有进行处理。 这种情况下的输出仍然取决于当前的输入:
-
如果输入是任何回车或换行符之外的其它字符, 则首先输出一个换行符, 然后输出输入内容, 并将程序状态变为
ordinary。 -
如果输入是回车符, 说明我们收到了在同一行中的两个 (或更多) 换行符。 此时应丢弃输入, 并输出一个换行符, 同时保持状态不变。
-
如果输入是换行符, 则输出一个换行符, 并将程序状态变为
ordinary。 请注意, 这和前面的地一种情况不同 - 如果我们把它们合并, 则结果将是输出两次换行符, 而不是所希望的一次。
最后, 如果我们收到的输入是一个在前面没有回车符的换行符的话, 则程序会进入 lf 状态。 如果我们的文件已经是 UNIX
格式, 或者一行中一个回车之后跟随了若干换行符,
或者行尾是换行/回车序列时便会发生这种情况。 下面是如何处理这种情况时的输入:
-
If the input is anything other than a carriage return or line feed, we output a line feed, then output the input, then change the state to
ordinary. This is exactly the same action as in thecrstate upon receiving the same kind of input. -
If the input is a carriage return, we discard the input, we output a line feed, then change the state to
ordinary. -
If the input is a line feed, we output the line feed, and leave the state unchanged.
11.11.1.1 The Final State
The above finite state machine works for the entire file, but leaves the possibility that the final line end will be ignored. That will happen whenever the file ends with a single carriage return or a single line feed. I did not think of it when I wrote tuc, just to discover that occasionally it strips the last line ending.
This problem is easily fixed by checking the state after the entire file was
processed. If the state is not ordinary, we simply need to
output one last line feed.
注意: Now that we have expressed our algorithm as a finite state machine, we could easily design a dedicated digital electronic circuit (a "chip") to do the conversion for us. Of course, doing so would be considerably more expensive than writing an assembly language program.
11.11.1.2 The Output Counter
Because our file conversion program may be combining two characters into one, we
need to use an output counter. We initialize it to 0, and
increase it every time we send a character to the output. At the end of the program, the
counter will tell us what size we need to set the file to.
11.11.2 Implementing FSM in Software
The hardest part of working with a finite state machine is analyzing the problem and expressing it as a finite state machine. That accomplished, the software almost writes itself.
In a high-level language, such as C, there are several main approaches. One is to
use a switch statement which chooses what function should
be run. For example,
switch (state) {
default:
case REGULAR:
regular(inputchar);
break;
case CR:
cr(inputchar);
break;
case LF:
lf(inputchar);
break;
}
Another approach is by using an array of function pointers, something like this:
(output[state])(inputchar);
Yet another is to have state be a function pointer,
set to point at the appropriate function:
(*state)(inputchar);
This is the approach we will use in our program because it is very easy to do in
assembly language, and very fast, too. We will simply keep the address of the right
procedure in EBX, and then just issue:
call ebx
This is possibly faster than hardcoding the address in the code because the microprocessor does not have to fetch the address from the memory──it is already stored in one of its registers. I said possibly because with the caching modern microprocessors do, either way may be equally fast.
11.11.3 Memory Mapped Files
Because our program works on a single file, we cannot use the approach that worked for us before, i.e., to read from an input file and to write to an output file.
UNIX allows us to map a file, or a section of a
file, into memory. To do that, we first need to open the file with the appropriate
read/write flags. Then we use the mmap system call to map
it into the memory. One nice thing about mmap is that it
automatically works with virtual memory: We can map more of the file into the memory than
we have physical memory available, yet still access it through regular memory op codes,
such as mov, lods, and stos. Whatever changes we make to the memory image of the file
will be written to the file by the system. We do not even have to keep the file open: As
long as it stays mapped, we can read from it and write to it.
The 32-bit Intel microprocessors can access up to four gigabytes of memory - physical or virtual. The FreeBSD system allows us to use up to a half of it for file mapping.
For simplicity sake, in this tutorial we will only convert files that can be mapped into the memory in their entirety. There are probably not too many text files that exceed two gigabytes in size. If our program encounters one, it will simply display a message suggesting we use the original tuc instead.
If you examine your copy of syscalls.master, you will
find two separate syscalls named mmap. This is because of
evolution of UNIX: There was the traditional BSD mmap, syscall 71.
That one was superseded by the POSIX mmap, syscall 197.
The FreeBSD system supports both because older programs were written by using the
original BSD version. But new software uses
the POSIX
version, which is what we will use.
The syscalls.master file lists the POSIX version like this:
197 STD BSD { caddr_t mmap(caddr_t addr, size_t len, int prot, \
int flags, int fd, long pad, off_t pos); }
This differs slightly from what mmap(2) says. That is because mmap(2) describes the C version.
The difference is in the long pad argument, which is
not present in the C version. However, the FreeBSD syscalls add a 32-bit pad after pushing a 64-bit argument. In this case, off_t is a 64-bit value.
When we are finished working with a memory-mapped file, we unmap it with the munmap syscall:
提示: For an in-depth treatment of
mmap, see W. Richard Stevens' Unix Network Programming, Volume 2, Chapter 12.
11.11.4 Determining File Size
Because we need to tell mmap how many bytes of the
file to map into the memory, and because we want to map the entire file, we need to
determine the size of the file.
We can use the fstat syscall to get all the
information about an open file that the system can give us. That includes the file
size.
Again, syscalls.master lists two versions of fstat, a traditional one (syscall 62), and a POSIX one (syscall
189). Naturally, we will use the POSIX version:
189 STD POSIX { int fstat(int fd, struct stat *sb); }
This is a very straightforward call: We pass to it the address of a stat structure and the descriptor of an open file. It will fill
out the contents of the stat structure.
I do, however, have to say that I tried to declare the stat structure in the .bss
section, and fstat did not like it: It set the carry flag
indicating an error. After I changed the code to allocate the structure on the stack,
everything was working fine.
11.11.5 Changing the File Size
Because our program may combine carriage return / line feed sequences into straight line feeds, our output may be smaller than our input. However, since we are placing our output into the same file we read the input from, we may have to change the size of the file.
The ftruncate system call allows us to do just that.
Despite its somewhat misleading name, the ftruncate system
call can be used to both truncate the file (make it smaller) and to grow it.
And yes, we will find two versions of ftruncate in
syscalls.master, an older one (130), and a newer one (201). We
will use the newer one:
201 STD BSD { int ftruncate(int fd, int pad, off_t length); }
Please note that this one contains a int pad
again.
11.11.6 ftuc
We now know everything we need to write ftuc. We start by adding some new lines in system.inc. First, we define some constants and structures, somewhere at or near the beginning of the file:
;;;;;;; open flags %define O_RDONLY 0 %define O_WRONLY 1 %define O_RDWR 2 ;;;;;;; mmap flags %define PROT_NONE 0 %define PROT_READ 1 %define PROT_WRITE 2 %define PROT_EXEC 4 ;; %define MAP_SHARED 0001h %define MAP_PRIVATE 0002h ;;;;;;; stat structure struc stat st_dev resd 1 ; = 0 st_ino resd 1 ; = 4 st_mode resw 1 ; = 8, size is 16 bits st_nlink resw 1 ; = 10, ditto st_uid resd 1 ; = 12 st_gid resd 1 ; = 16 st_rdev resd 1 ; = 20 st_atime resd 1 ; = 24 st_atimensec resd 1 ; = 28 st_mtime resd 1 ; = 32 st_mtimensec resd 1 ; = 36 st_ctime resd 1 ; = 40 st_ctimensec resd 1 ; = 44 st_size resd 2 ; = 48, size is 64 bits st_blocks resd 2 ; = 56, ditto st_blksize resd 1 ; = 64 st_flags resd 1 ; = 68 st_gen resd 1 ; = 72 st_lspare resd 1 ; = 76 st_qspare resd 4 ; = 80 endstruc
We define the new syscalls:
%define SYS_mmap 197 %define SYS_munmap 73 %define SYS_fstat 189 %define SYS_ftruncate 201
We add the macros for their use:
%macro sys.mmap 0
system SYS_mmap
%endmacro
%macro sys.munmap 0
system SYS_munmap
%endmacro
%macro sys.ftruncate 0
system SYS_ftruncate
%endmacro
%macro sys.fstat 0
system SYS_fstat
%endmacro
And here is our code:
;;;;;;; Fast Text-to-Unix Conversion (ftuc.asm) ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;;
;; Started: 21-Dec-2000
;; Updated: 22-Dec-2000
;;
;; Copyright 2000 G. Adam Stanislav.
;; All rights reserved.
;;
;;;;;;; v.1 ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
%include 'system.inc'
section .data
db 'Copyright 2000 G. Adam Stanislav.', 0Ah
db 'All rights reserved.', 0Ah
usg db 'Usage: ftuc filename', 0Ah
usglen equ $-usg
co db "ftuc: Can't open file.", 0Ah
colen equ $-co
fae db 'ftuc: File access error.', 0Ah
faelen equ $-fae
ftl db 'ftuc: File too long, use regular tuc instead.', 0Ah
ftllen equ $-ftl
mae db 'ftuc: Memory allocation error.', 0Ah
maelen equ $-mae
section .text
align 4
memerr:
push dword maelen
push dword mae
jmp short error
align 4
toolong:
push dword ftllen
push dword ftl
jmp short error
align 4
facerr:
push dword faelen
push dword fae
jmp short error
align 4
cantopen:
push dword colen
push dword co
jmp short error
align 4
usage:
push dword usglen
push dword usg
error:
push dword stderr
sys.write
push dword 1
sys.exit
align 4
global _start
_start:
pop eax ; argc
pop eax ; program name
pop ecx ; file to convert
jecxz usage
pop eax
or eax, eax ; Too many arguments?
jne usage
; Open the file
push dword O_RDWR
push ecx
sys.open
jc cantopen
mov ebp, eax ; Save fd
sub esp, byte stat_size
mov ebx, esp
; Find file size
push ebx
push ebp ; fd
sys.fstat
jc facerr
mov edx, [ebx + st_size + 4]
; File is too long if EDX != 0 ...
or edx, edx
jne near toolong
mov ecx, [ebx + st_size]
; ... or if it is above 2 GB
or ecx, ecx
js near toolong
; Do nothing if the file is 0 bytes in size
jecxz .quit
; Map the entire file in memory
push edx
push edx ; starting at offset 0
push edx ; pad
push ebp ; fd
push dword MAP_SHARED
push dword PROT_READ | PROT_WRITE
push ecx ; entire file size
push edx ; let system decide on the address
sys.mmap
jc near memerr
mov edi, eax
mov esi, eax
push ecx ; for SYS_munmap
push edi
; Use EBX for state machine
mov ebx, ordinary
mov ah, 0Ah
cld
.loop:
lodsb
call ebx
loop .loop
cmp ebx, ordinary
je .filesize
; Output final lf
mov al, ah
stosb
inc edx
.filesize:
; truncate file to new size
push dword 0 ; high dword
push edx ; low dword
push eax ; pad
push ebp
sys.ftruncate
; close it (ebp still pushed)
sys.close
add esp, byte 16
sys.munmap
.quit:
push dword 0
sys.exit
align 4
ordinary:
cmp al, 0Dh
je .cr
cmp al, ah
je .lf
stosb
inc edx
ret
align 4
.cr:
mov ebx, cr
ret
align 4
.lf:
mov ebx, lf
ret
align 4
cr:
cmp al, 0Dh
je .cr
cmp al, ah
je .lf
xchg al, ah
stosb
inc edx
xchg al, ah
; fall through
.lf:
stosb
inc edx
mov ebx, ordinary
ret
align 4
.cr:
mov al, ah
stosb
inc edx
ret
align 4
lf:
cmp al, ah
je .lf
cmp al, 0Dh
je .cr
xchg al, ah
stosb
inc edx
xchg al, ah
stosb
inc edx
mov ebx, ordinary
ret
align 4
.cr:
mov ebx, ordinary
mov al, ah
; fall through
.lf:
stosb
inc edx
ret
警告: Do not use this program on files stored on a disk formatted by MS-DOS or Windows. There seems to be a subtle bug in the FreeBSD code when using
mmapon these drives mounted under FreeBSD: If the file is over a certain size,mmapwill just fill the memory with zeros, and then copy them to the file overwriting its contents.
11.12 One-Pointed Mind
As a student of Zen, I like the idea of a one-pointed mind: Do one thing at a time, and do it well.
This, indeed, is very much how UNIX works as well. While a typical Windows application is attempting to do everything imaginable (and is, therefore, riddled with bugs), a typical UNIX program does only one thing, and it does it well.
The typical UNIX user then essentially assembles his own applications by writing a shell script which combines the various existing programs by piping the output of one program to the input of another.
When writing your own UNIX software, it is generally a good idea to see what parts of the problem you need to solve can be handled by existing programs, and only write your own programs for that part of the problem that you do not have an existing solution for.
11.12.1 CSV
I will illustrate this principle with a specific real-life example I was faced with recently:
I needed to extract the 11th field of each record from a database I downloaded from a web site. The database was a CSV file, i.e., a list of comma-separated values. That is quite a standard format for sharing data among people who may be using different database software.
The first line of the file contains the list of various fields separated by commas. The rest of the file contains the data listed line by line, with values separated by commas.
I tried awk, using the comma as a separator. But because several lines contained a quoted comma, awk was extracting the wrong field from those lines.
Therefore, I needed to write my own software to extract the 11th field from the CSV file. However, going with the UNIX spirit, I only needed to write a simple filter that would do the following:
-
Remove the first line from the file;
-
Change all unquoted commas to a different character;
-
Remove all quotation marks.
Strictly speaking, I could use sed to remove the first line from the file, but doing so in my own program was very easy, so I decided to do it and reduce the size of the pipeline.
At any rate, writing a program like this took me about 20 minutes. Writing a program that extracts the 11th field from the CSV file would take a lot longer, and I could not reuse it to extract some other field from some other database.
This time I decided to let it do a little more work than a typical tutorial program would:
-
It parses its command line for options;
-
It displays proper usage if it finds wrong arguments;
-
It produces meaningful error messages.
Here is its usage message:
Usage: csv [-t<delim>] [-c<comma>] [-p] [-o <outfile>] [-i <infile>]
All parameters are optional, and can appear in any order.
The -t parameter declares what to replace the
commas with. The tab is the default here. For example,
-t; will replace all unquoted commas with semicolons.
I did not need the -c option, but it may come in
handy in the future. It lets me declare that I want a character other than a comma
replaced with something else. For example, -c@ will
replace all at signs (useful if you want to split a list of email addresses to their user
names and domains).
The -p option preserves the first line, i.e., it
does not delete it. By default, we delete the first line because in a CSV file it contains the field names rather than
data.
The -i and -o
options let me specify the input and the output files. Defaults are stdin and stdout, so this is a regular
UNIX filter.
I made sure that both -i filename and -ifilename are accepted. I also made sure that only one input
and one output files may be specified.
To get the 11th field of each record, I can now do:
% csv '-t;' data.csv | awk '-F;' '{print $11}'
The code stores the options (except for the file descriptors) in EDX: The comma in DH, the new
separator in DL, and the flag for the -p option in the highest bit of EDX, so a check for its sign will give us a quick decision what to
do.
Here is the code:
;;;;;;; csv.asm ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;
; Convert a comma-separated file to a something-else separated file.
;
; Started: 31-May-2001
; Updated: 1-Jun-2001
;
; Copyright (c) 2001 G. Adam Stanislav
; All rights reserved.
;
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
%include 'system.inc'
%define BUFSIZE 2048
section .data
fd.in dd stdin
fd.out dd stdout
usg db 'Usage: csv [-t<delim>] [-c<comma>] [-p] [-o <outfile>] [-i <infile>]', 0Ah
usglen equ $-usg
iemsg db "csv: Can't open input file", 0Ah
iemlen equ $-iemsg
oemsg db "csv: Can't create output file", 0Ah
oemlen equ $-oemsg
section .bss
ibuffer resb BUFSIZE
obuffer resb BUFSIZE
section .text
align 4
ierr:
push dword iemlen
push dword iemsg
push dword stderr
sys.write
push dword 1 ; return failure
sys.exit
align 4
oerr:
push dword oemlen
push dword oemsg
push dword stderr
sys.write
push dword 2
sys.exit
align 4
usage:
push dword usglen
push dword usg
push dword stderr
sys.write
push dword 3
sys.exit
align 4
global _start
_start:
add esp, byte 8 ; discard argc and argv[0]
mov edx, (',' << 8) | 9
.arg:
pop ecx
or ecx, ecx
je near .init ; no more arguments
; ECX contains the pointer to an argument
cmp byte [ecx], '-'
jne usage
inc ecx
mov ax, [ecx]
.o:
cmp al, 'o'
jne .i
; Make sure we are not asked for the output file twice
cmp dword [fd.out], stdout
jne usage
; Find the path to output file - it is either at [ECX+1],
; i.e., -ofile --
; or in the next argument,
; i.e., -o file
inc ecx
or ah, ah
jne .openoutput
pop ecx
jecxz usage
.openoutput:
push dword 420 ; file mode (644 octal)
push dword 0200h | 0400h | 01h
; O_CREAT | O_TRUNC | O_WRONLY
push ecx
sys.open
jc near oerr
add esp, byte 12
mov [fd.out], eax
jmp short .arg
.i:
cmp al, 'i'
jne .p
; Make sure we are not asked twice
cmp dword [fd.in], stdin
jne near usage
; Find the path to the input file
inc ecx
or ah, ah
jne .openinput
pop ecx
or ecx, ecx
je near usage
.openinput:
push dword 0 ; O_RDONLY
push ecx
sys.open
jc near ierr ; open failed
add esp, byte 8
mov [fd.in], eax
jmp .arg
.p:
cmp al, 'p'
jne .t
or ah, ah
jne near usage
or edx, 1 << 31
jmp .arg
.t:
cmp al, 't' ; redefine output delimiter
jne .c
or ah, ah
je near usage
mov dl, ah
jmp .arg
.c:
cmp al, 'c'
jne near usage
or ah, ah
je near usage
mov dh, ah
jmp .arg
align 4
.init:
sub eax, eax
sub ebx, ebx
sub ecx, ecx
mov edi, obuffer
; See if we are to preserve the first line
or edx, edx
js .loop
.firstline:
; get rid of the first line
call getchar
cmp al, 0Ah
jne .firstline
.loop:
; read a byte from stdin
call getchar
; is it a comma (or whatever the user asked for)?
cmp al, dh
jne .quote
; Replace the comma with a tab (or whatever the user wants)
mov al, dl
.put:
call putchar
jmp short .loop
.quote:
cmp al, '"'
jne .put
; Print everything until you get another quote or EOL. If it
; is a quote, skip it. If it is EOL, print it.
.qloop:
call getchar
cmp al, '"'
je .loop
cmp al, 0Ah
je .put
call putchar
jmp short .qloop
align 4
getchar:
or ebx, ebx
jne .fetch
call read
.fetch:
lodsb
dec ebx
ret
read:
jecxz .read
call write
.read:
push dword BUFSIZE
mov esi, ibuffer
push esi
push dword [fd.in]
sys.read
add esp, byte 12
mov ebx, eax
or eax, eax
je .done
sub eax, eax
ret
align 4
.done:
call write ; flush output buffer
; close files
push dword [fd.in]
sys.close
push dword [fd.out]
sys.close
; return success
push dword 0
sys.exit
align 4
putchar:
stosb
inc ecx
cmp ecx, BUFSIZE
je write
ret
align 4
write:
jecxz .ret ; nothing to write
sub edi, ecx ; start of buffer
push ecx
push edi
push dword [fd.out]
sys.write
add esp, byte 12
sub eax, eax
sub ecx, ecx ; buffer is empty now
.ret:
ret
Much of it is taken from hex.asm above. But there is one
important difference: I no longer call write whenever I am
outputting a line feed. Yet, the code can be used interactively.
I have found a better solution for the interactive problem since I first started writing this chapter. I wanted to make sure each line is printed out separately only when needed. After all, there is no need to flush out every line when used non-interactively.
The new solution I use now is to call write every
time I find the input buffer empty. That way, when running in the interactive mode, the
program reads one line from the user's keyboard, processes it, and sees its input buffer
is empty. It flushes its output and reads the next line.
11.12.1.1 The Dark Side of Buffering
This change prevents a mysterious lockup in a very specific case. I refer to it as the dark side of buffering, mostly because it presents a danger that is not quite obvious.
It is unlikely to happen with a program like the csv above, so let us consider yet another filter: In this case we expect our input to be raw data representing color values, such as the red, green, and blue intensities of a pixel. Our output will be the negative of our input.
Such a filter would be very simple to write. Most of it would look just like all the other filters we have written so far, so I am only going to show you its inner loop:
.loop:
call getchar
not al ; Create a negative
call putchar
jmp short .loop
Because this filter works with raw data, it is unlikely to be used interactively.
But it could be called by image manipulation software. And, unless it calls write before each call to read,
chances are it will lock up.
Here is what might happen:
-
The image editor will load our filter using the C function
popen(). -
It will read the first row of pixels from a bitmap or pixmap.
-
It will write the first row of pixels to the pipe leading to the
fd.inof our filter. -
Our filter will read each pixel from its input, turn it to a negative, and write it to its output buffer.
-
Our filter will call
getcharto fetch the next pixel. -
getcharwill find an empty input buffer, so it will callread. -
readwill call theSYS_readsystem call. -
The kernel will suspend our filter until the image editor sends more data to the pipe.
-
The image editor will read from the other pipe, connected to the
fd.outof our filter so it can set the first row of the output image before it sends us the second row of the input. -
The kernel suspends the image editor until it receives some output from our filter, so it can pass it on to the image editor.
At this point our filter waits for the image editor to send it more data to process, while the image editor is waiting for our filter to send it the result of the processing of the first row. But the result sits in our output buffer.
The filter and the image editor will continue waiting for each other forever (or, at least, until they are killed). Our software has just entered a race condition.
This problem does not exist if our filter flushes its output buffer before asking the kernel for more input data.
11.13 Using the FPU
Strangely enough, most of assembly language literature does not even mention the existence of the FPU, or floating point unit, let alone discuss programming it.
Yet, never does assembly language shine more than when we create highly optimized FPU code by doing things that can be done only in assembly language.
11.13.1 Organization of the FPU
The FPU consists of 8 80-bit
floating-point registers. These are organized in a stack fashion──you can push a value on TOS
(top of stack) and you can pop it.
That said, the assembly language op codes are not push and pop because those are
already taken.
You can push a value on TOS by using fld, fild, and fbld. Several other op
codes let you push many common constants──such as pi──on the TOS.
Similarly, you can pop a value by using fst, fstp, fist, fistp, and fbstp. Actually, only the op codes that end with a p will literally pop the value, the rest will store
it somewhere else without removing it from the TOS.
We can transfer the data between the TOS and the computer memory either as a 32-bit, 64-bit, or 80-bit real, a 16-bit, 32-bit, or 64-bit integer, or an 80-bit packed decimal.
The 80-bit packed decimal is a special case of binary coded decimal which is very convenient when converting between the ASCII representation of data and the internal data of the FPU. It allows us to use 18 significant digits.
No matter how we represent data in the memory, the FPU always stores it in the 80-bit real format in its registers.
Its internal precision is at least 19 decimal digits, so even if we choose to display results as ASCII in the full 18-digit precision, we are still showing correct results.
We can perform mathematical operations on the TOS: We can calculate its sine, we can scale it (i.e., we can multiply or divide it by a power of 2), we can calculate its base-2 logarithm, and many other things.
We can also multiply or divide it by, add it to, or subtract it from, any of the FPU registers (including itself).
The official Intel op code for the TOS
is st, and for the registers st(0)-st(7). st and st(0), then, refer to the same register.
For whatever reasons, the original author of nasm has
decided to use different op codes, namely st0-st7. In other words, there are no parentheses, and the TOS is always st0, never
just st.
11.13.1.1 The Packed Decimal Format
The packed decimal format uses 10 bytes (80 bits) of memory to represent 18 digits. The number represented there is always an integer.
提示: You can use it to get decimal places by multiplying the TOS by a power of 10 first.
The highest bit of the highest byte (byte 9) is the sign bit: If it is set, the number is negative, otherwise, it is positive. The rest of the bits of this byte are unused/ignored.
The remaining 9 bytes store the 18 digits of the number: 2 digits per byte.
The more significant digit is stored in the high nibble (4 bits), the less significant digit in the low nibble.
That said, you might think that -1234567 would be
stored in the memory like this (using hexadecimal notation):
80 00 00 00 00 00 01 23 45 67
Alas it is not! As with everything else of Intel make, even the packed decimal is little-endian.
That means our -1234567 is stored like this:
67 45 23 01 00 00 00 00 00 80
Remember that, or you will be pulling your hair out in desperation!
注意: The book to read──if you can find it──is Richard Startz' 8087/80287/80387 for the IBM PC & Compatibles. Though it does seem to take the fact about the little-endian storage of the packed decimal for granted. I kid you not about the desperation of trying to figure out what was wrong with the filter I show below before it occurred to me I should try the little-endian order even for this type of data.
11.13.2 Excursion to Pinhole Photography
To write meaningful software, we must not only understand our programming tools, but also the field we are creating software for.
Our next filter will help us whenever we want to build a pinhole camera, so, we need some background in pinhole photography before we can continue.
11.13.2.1 The Camera
The easiest way to describe any camera ever built is as some empty space enclosed in some lightproof material, with a small hole in the enclosure.
The enclosure is usually sturdy (e.g., a box), though sometimes it is flexible (the bellows). It is quite dark inside the camera. However, the hole lets light rays in through a single point (though in some cases there may be several). These light rays form an image, a representation of whatever is outside the camera, in front of the hole.
If some light sensitive material (such as film) is placed inside the camera, it can capture the image.
The hole often contains a lens, or a lens assembly, often called the objective.
11.13.2.2 The Pinhole
But, strictly speaking, the lens is not necessary: The original cameras did not use a lens but a pinhole. Even today, pinholes are used, both as a tool to study how cameras work, and to achieve a special kind of image.
The image produced by the pinhole is all equally sharp. Or blurred. There is an ideal size for a pinhole: If it is either larger or smaller, the image loses its sharpness.
11.13.2.3 Focal Length
This ideal pinhole diameter is a function of the square root of focal length, which is the distance of the pinhole from the film.
D = PC * sqrt(FL)
In here, D is the ideal diameter of the pinhole,
FL is the focal length, and PC
is a pinhole constant. According to Jay Bender, its value is 0.04, while Kenneth Connors has determined it to be 0.037. Others have proposed other values. Plus, this value is for
the daylight only: Other types of light will require a different constant, whose value
can only be determined by experimentation.
11.13.2.4 The F-Number
The f-number is a very useful measure of how much light reaches the film. A light meter can determine that, for example, to expose a film of specific sensitivity with f5.6 may require the exposure to last 1/1000 sec.
It does not matter whether it is a 35-mm camera, or a 6x9cm camera, etc. As long as we know the f-number, we can determine the proper exposure.
The f-number is easy to calculate:
F = FL / D
In other words, the f-number equals the focal length divided by the diameter of the pinhole. It also means a higher f-number either implies a smaller pinhole or a larger focal distance, or both. That, in turn, implies, the higher the f-number, the longer the exposure has to be.
Furthermore, while pinhole diameter and focal distance are one-dimensional
measurements, both, the film and the pinhole, are two-dimensional. That means that if you
have measured the exposure at f-number A as t, then the exposure at f-number B
is:
t * (B / A)²
11.13.2.5 Normalized F-Number
While many modern cameras can change the diameter of their pinhole, and thus their f-number, quite smoothly and gradually, such was not always the case.
To allow for different f-numbers, cameras typically contained a metal plate with several holes of different sizes drilled to them.
Their sizes were chosen according to the above formula in such a way that the resultant f-number was one of standard f-numbers used on all cameras everywhere. For example, a very old Kodak Duaflex IV camera in my possession has three such holes for f-numbers 8, 11, and 16.
A more recently made camera may offer f-numbers of 2.8, 4, 5.6, 8, 11, 16, 22, and 32 (as well as others). These numbers were not chosen arbitrarily: They all are powers of the square root of 2, though they may be rounded somewhat.
11.13.2.6 The F-Stop
A typical camera is designed in such a way that setting any of the normalized f-numbers changes the feel of the dial. It will naturally stop in that position. Because of that, these positions of the dial are called f-stops.
Since the f-numbers at each stop are powers of the square root of 2, moving the dial by 1 stop will double the amount of light required for proper exposure. Moving it by 2 stops will quadruple the required exposure. Moving the dial by 3 stops will require the increase in exposure 8 times, etc.
11.13.3 Designing the Pinhole Software
We are now ready to decide what exactly we want our pinhole software to do.
11.13.3.1 Processing Program Input
Since its main purpose is to help us design a working pinhole camera, we will use the focal length as the input to the program. This is something we can determine without software: Proper focal length is determined by the size of the film and by the need to shoot "regular" pictures, wide angle pictures, or telephoto pictures.
Most of the programs we have written so far worked with individual characters, or bytes, as their input: The hex program converted individual bytes into a hexadecimal number, the csv program either let a character through, or deleted it, or changed it to a different character, etc.
One program, ftuc used the state machine to consider at most two input bytes at a time.
But our pinhole program cannot just work with individual characters, it has to deal with larger syntactic units.
For example, if we want the program to calculate the pinhole diameter (and other
values we will discuss later) at the focal lengths of 100
mm, 150 mm, and 210
mm, we may want to enter something like this:
100, 150, 210
Our program needs to consider more than a single byte of input at a time. When it
sees the first 1, it must understand it is seeing the first
digit of a decimal number. When it sees the 0 and the other
0, it must know it is seeing more digits of the same
number.
When it encounters the first comma, it must know it is no longer receiving the
digits of the first number. It must be able to convert the digits of the first number
into the value of 100. And the digits of the second number
into the value of 150. And, of course, the digits of the
third number into the numeric value of 210.
We need to decide what delimiters to accept: Do the input numbers have to be separated by a comma? If so, how do we treat two numbers separated by something else?
Personally, I like to keep it simple. Something either is a number, so I process it. Or it is not a number, so I discard it. I do not like the computer complaining about me typing in an extra character when it is obvious that it is an extra character. Duh!
Plus, it allows me to break up the monotony of computing and type in a query instead of just a number:
What is the best pinhole diameter for the focal length of 150?
There is no reason for the computer to spit out a number of complaints:
Syntax error: What Syntax error: is Syntax error: the Syntax error: best
Et cetera, et cetera, et cetera.
Secondly, I like the # character to denote the start
of a comment which extends to the end of the line. This does not take too much effort to
code, and lets me treat input files for my software as executable scripts.
In our case, we also need to decide what units the input should come in: We choose millimeters because that is how most photographers measure the focus length.
Finally, we need to decide whether to allow the use of the decimal point (in which case we must also consider the fact that much of the world uses a decimal comma).
In our case allowing for the decimal point/comma would offer a false sense of
precision: There is little if any noticeable difference between the focus lengths of
50 and 51, so allowing the
user to input something like 50.5 is not a good idea. This
is my opinion, mind you, but I am the one writing this program. You can make other
choices in yours, of course.
11.13.3.2 Offering Options
The most important thing we need to know when building a pinhole camera is the
diameter of the pinhole. Since we want to shoot sharp images, we will use the above
formula to calculate the pinhole diameter from focal length. As experts are offering
several different values for the PC constant, we will need
to have the choice.
It is traditional in UNIX programming to have two main ways of choosing program parameters, plus to have a default for the time the user does not make a choice.
Why have two ways of choosing?
One is to allow a (relatively) permanent choice that applies automatically each time the software is run without us having to tell it over and over what we want it to do.
The permanent choices may be stored in a configuration file, typically found in the user's home directory. The file usually has the same name as the application but is started with a dot. Often "rc" is added to the file name. So, ours could be ~/.pinhole or ~/.pinholerc. (The ~/ means current user's home directory.)
The configuration file is used mostly by programs that have many configurable
parameters. Those that have only one (or a few) often use a different method: They expect
to find the parameter in an environment
variable. In our case, we might look at an environment variable named PINHOLE.
Usually, a program uses one or the other of the above methods. Otherwise, if a configuration file said one thing, but an environment variable another, the program might get confused (or just too complicated).
Because we only need to choose one such parameter, we will go with the second method and
search the environment for a variable named PINHOLE.
The other way allows us to make ad hoc decisions: "Though I usually want you to use 0.039, this time I want 0.03872." In other words, it allows us to override the permanent choice.
This type of choice is usually done with command line parameters.
Finally, a program always needs a default. The user may not make any choices. Perhaps he does not know what to choose. Perhaps he is "just browsing." Preferably, the default will be the value most users would choose anyway. That way they do not need to choose. Or, rather, they can choose the default without an additional effort.
Given this system, the program may find conflicting options, and handle them this way:
-
If it finds an ad hoc choice (e.g., command line parameter), it should accept that choice. It must ignore any permanent choice and any default.
-
Otherwise, if it finds a permanent option (e.g., an environment variable), it should accept it, and ignore the default.
-
Otherwise, it should use the default.
We also need to decide what format our PC option should
have.
At first site, it seems obvious to use the PINHOLE=0.04 format for the environment variable, and -p0.04 for the command line.
Allowing that is actually a security risk. The PC
constant is a very small number. Naturally, we will test our software using various small
values of PC. But what will happen if someone runs the
program choosing a huge value?
It may crash the program because we have not designed it to handle huge numbers.
Or, we may spend more time on the program so it can handle huge numbers. We might do that if we were writing commercial software for computer illiterate audience.
Or, we might say, "Tough! The user should know better.""
Or, we just may make it impossible for the user to enter a huge number. This is the approach we will take: We will use an implied 0. prefix.
In other words, if the user wants 0.04, we will
expect him to type -p04, or set PINHOLE=04 in his environment. So, if he says -p9999999, we will interpret it as 0.9999999──still ridiculous but at least safer.
Secondly, many users will just want to go with either Bender's constant or
Connors' constant. To make it easier on them, we will interpret -b as identical to -p04, and
-c as identical to -p037.
11.13.3.3 The Output
We need to decide what we want our software to send to the output, and in what format.
Since our input allows for an unspecified number of focal length entries, it makes
sense to use a traditional database-style output of showing the result of the calculation
for each focal length on a separate line, while separating all values on one line by a
tab character.
Optionally, we should also allow the user to specify the use of the CSV format we have studied earlier. In this case, we
will print out a line of comma-separated names describing each field of every line, then
show our results as before, but substituting a comma for
the tab.
We need a command line option for the CSV format. We cannot use -c because
that already means use Connors'
constant. For some strange reason, many web sites refer to CSV files as "Excel spreadsheet" (though the CSV format predates Excel). We will, therefore, use the -e switch to inform our software we want the output in the
CSV format.
We will start each line of the output with the focal length. This may sound repetitious at first, especially in the interactive mode: The user types in the focal length, and we are repeating it.
But the user can type several focal lengths on one line. The input can also come in from a file or from the output of another program. In that case the user does not see the input at all.
By the same token, the output can go to a file which we will want to examine later, or it could go to the printer, or become the input of another program.
So, it makes perfect sense to start each line with the focal length as entered by the user.
No, wait! Not as entered by the user. What if the user types in something like this:
00000000150
Clearly, we need to strip those leading zeros.
So, we might consider reading the user input as is, converting it to binary inside the FPU, and printing it out from there.
But...
What if the user types something like this:
17459765723452353453534535353530530534563507309676764423
Ha! The packed decimal FPU format lets us input 18-digit numbers. But the user has entered more than 18 digits. How do we handle that?
Well, we could modify our
code to read the first 18 digits, enter it to the FPU, then read more, multiply what we already have on the TOS by 10 raised to the number of additional digits,
then add to it.
Yes, we could do that. But in this program it would be ridiculous (in a different one it may be just the thing to do): Even the circumference of the Earth expressed in millimeters only takes 11 digits. Clearly, we cannot build a camera that large (not yet, anyway).
So, if the user enters such a huge number, he is either bored, or testing us, or trying to break into the system, or playing games──doing anything but designing a pinhole camera.
What will we do?
We will slap him in the face, in a manner of speaking:
17459765723452353453534535353530530534563507309676764423 ??? ??? ??? ??? ???
To achieve that, we will simply ignore any leading zeros. Once we find a non-zero
digit, we will initialize a counter to 0 and start taking
three steps:
-
Send the digit to the output.
-
Append the digit to a buffer we will use later to produce the packed decimal we can send to the FPU.
-
Increase the counter.
Now, while we are taking these three steps, we also need to watch out for one of two conditions:
-
If the counter grows above 18, we stop appending to the buffer. We continue reading the digits and sending them to the output.
-
If, or rather when, the next input character is not a digit, we are done inputting for now.
Incidentally, we can simply discard the non-digit, unless it is a
#, which we must return to the input stream. It starts a comment, so we must see it after we are done producing output and start looking for more input.
That still leaves one possibility uncovered: If all the user enters is a zero (or several zeros), we will never find a non-zero to display.
We can determine this has happened whenever our counter stays at 0. In that case we need to send 0
to the output, and perform another "slap in the face":
0 ??? ??? ??? ??? ???
Once we have displayed the focal length and determined it is valid (greater than
0 but not exceeding 18 digits), we can calculate the
pinhole diameter.
It is not by coincidence that pinhole contains the word pin. Indeed, many a pinhole literally is a pin hole, a hole carefully punched with the tip of a pin.
That is because a typical pinhole is very small. Our formula gets the result in
millimeters. We will multiply it by 1000, so we can output
the result in microns.
At this point we have yet another trap to face: Too much precision.
Yes, the FPU was designed for high precision mathematics. But we are not dealing with high precision mathematics. We are dealing with physics (optics, specifically).
Suppose we want to convert a truck into a pinhole camera (we would not be the
first ones to do that!). Suppose its box is 12 meters long,
so we have the focal length of 12000. Well, using Bender's
constant, it gives us square root of 12000 multiplied by
0.04, which is 4.381780460
millimeters, or 4381.780460 microns.
Put either way, the result is absurdly precise. Our truck is not exactly 12000 millimeters long. We did not measure its length with such a
precision, so stating we need a pinhole with the diameter of 4.381780460 millimeters is, well, deceiving. 4.4 millimeters would do just fine.
注意: I "only" used ten digits in the above example. Imagine the absurdity of going for all 18!
We need to limit the number of significant digits of our result. One way of doing
it is by using an integer representing microns. So, our truck would need a pinhole with
the diameter of 4382 microns. Looking at that number, we
still decide that 4400 microns, or 4.4 millimeters is close enough.
Additionally, we can decide that no matter how big a result we get, we only want to display four significant digits (or any other number of them, of course). Alas, the FPU does not offer rounding to a specific number of digits (after all, it does not view the numbers as decimal but as binary).
We, therefore, must devise an algorithm to reduce the number of significant digits.
Here is mine (I think it is awkward──if you know a better one, please, let me know):
-
Initialize a counter to
0. -
While the number is greater than or equal to
10000, divide it by10and increase the counter. -
Output the result.
-
While the counter is greater than
0, output0and decrease the counter.
注意: The
10000is only good if you want four significant digits. For any other number of significant digits, replace10000with10raised to the number of significant digits.
We will, then, output the pinhole diameter in microns, rounded off to four significant digits.
At this point, we know the focal length and the pinhole diameter. That means we have enough information to also calculate the f-number.
We will display the f-number, rounded to four significant digits. Chances are the f-number will tell us very little. To make it more meaningful, we can find the nearest normalized f-number, i.e., the nearest power of the square root of 2.
We do that by multiplying the actual f-number by itself, which, of course, will
give us its square. We will then calculate its base-2
logarithm, which is much easier to do than calculating the base-square-root-of-2
logarithm! We will round the result to the nearest integer. Next, we will raise 2 to the
result. Actually, the FPU gives us a good
shortcut to do that: We can use the fscale op code to
"scale" 1, which is analogous to shifting an integer left.
Finally, we calculate the square root of it all, and we have the nearest normalized
f-number.
If all that sounds overwhelming──or too much work, perhaps──it may become much clearer if you see the code. It takes 9 op codes altogether:
fmul st0, st0
fld1
fld st1
fyl2x
frndint
fld1
fscale
fsqrt
fstp st1
The first line, fmul st0, st0, squares the contents
of the TOS (top of the stack, same as st, called st0 by nasm). The fld1 pushes 1 on the TOS.
The next line, fld st1, pushes the square back to
the TOS. At this point the square is both in
st and st(2) (it will become
clear why we leave a second copy on the stack in a moment). st(1) contains 1.
Next, fyl2x calculates base-2 logarithm of st multiplied by st(1). That is why
we placed 1 on st(1)
before.
At this point, st contains the logarithm we have just
calculated, st(1) contains the square of the actual f-number
we saved for later.
frndint rounds the TOS to the nearest integer. fld1 pushes
a 1. fscale shifts the 1 we have on the TOS
by the value in st(1), effectively raising 2 to st(1).
Finally, fsqrt calculates the square root of the
result, i.e., the nearest normalized f-number.
We now have the nearest normalized f-number on the TOS, the base-2 logarithm rounded to the nearest integer in st(1), and the square of the actual f-number in st(2). We are saving the value in st(2) for later.
But we do not need the contents of st(1) anymore. The
last line, fstp st1, places the contents of st to st(1), and pops. As a result,
what was st(1) is now st, what
was st(2) is now st(1), etc.
The new st contains the normalized f-number. The new st(1) contains the square of the actual f-number we have stored
there for posterity.
At this point, we are ready to output the normalized f-number. Because it is normalized, we will not round it off to four significant digits, but will send it out in its full precision.
The normalized f-number is useful as long as it is reasonably small and can be found on our light meter. Otherwise we need a different method of determining proper exposure.
Earlier we have figured out the formula of calculating proper exposure at an arbitrary f-number from that measured at a different f-number.
Every light meter I have ever seen can determine proper exposure at f5.6. We will, therefore, calculate an "f5.6 multiplier," i.e., by how much we need to multiply the exposure measured at f5.6 to determine the proper exposure for our pinhole camera.
From the above formula we know this factor can be calculated by dividing our
f-number (the actual one, not the normalized one) by 5.6,
and squaring the result.
Mathematically, dividing the square of our f-number by the square of 5.6 will give us the same result.
Computationally, we do not want to square two numbers when we can only square one. So, the first solution seems better at first.
But...
5.6 is a constant. We do not have to have our FPU waste precious cycles. We can just tell it to divide the square of
the f-number by whatever 5.6² equals to. Or we can
divide the f-number by 5.6, and then square the result. The
two ways now seem equal.
But, they are not!
Having studied the principles of photography above, we remember that the 5.6 is actually square root of 2 raised to the fifth power. An
irrational number. The square of
this number is exactly 32.
Not only is 32 an integer, it is a power of 2. We do
not need to divide the square of the f-number by 32. We
only need to use fscale to shift it right by five
positions. In the FPU lingo it means we will
fscale it with st(1) equal to
-5. That is much
faster than a division.
So, now it has become clear why we have saved the square of the f-number on the top of the FPU stack. The calculation of the f5.6 multiplier is the easiest calculation of this entire program! We will output it rounded to four significant digits.
There is one more useful number we can calculate: The number of stops our f-number is from f5.6. This may help us if our f-number is just outside the range of our light meter, but we have a shutter which lets us set various speeds, and this shutter uses stops.
Say, our f-number is 5 stops from f5.6, and the light meter says we should use 1/1000 sec. Then we can set our shutter speed to 1/1000 first, then move the dial by 5 stops.
This calculation is quite easy as well. All we have to do is to calculate the base-2 logarithm of the f5.6 multiplier we had just calculated (though we need its value from before we rounded it off). We then output the result rounded to the nearest integer. We do not need to worry about having more than four significant digits in this one: The result is most likely to have only one or two digits anyway.
11.13.4 FPU Optimizations
In assembly language we can optimize the FPU code in ways impossible in high languages, including C.
Whenever a C function needs to calculate a floating-point value, it loads all necessary variables and constants into FPU registers. It then does whatever calculation is required to get the correct result. Good C compilers can optimize that part of the code really well.
It "returns" the value by leaving the result on the TOS. However, before it returns, it cleans up. Any variables and constants it used in its calculation are now gone from the FPU.
It cannot do what we just did above: We calculated the square of the f-number and kept it on the stack for later use by another function.
We knew we would need that value later on. We also knew we had enough room on the stack (which only has room for 8 numbers) to store it there.
A C compiler has no way of knowing that a value it has on the stack will be required again in the very near future.
Of course, the C programmer may know it. But the only recourse he has is to store the value in a memory variable.
That means, for one, the value will be changed from the 80-bit precision used internally by the FPU to a C double (64 bits) or even single (32 bits).
That also means that the value must be moved from the TOS into the memory, and then back again. Alas, of all FPU operations, the ones that access the computer memory are the slowest.
So, whenever programming the FPU in assembly language, look for the ways of keeping intermediate results on the FPU stack.
We can take that idea even further! In our program we are using a constant (the one we named PC).
It does not matter how many pinhole diameters we are calculating: 1, 10, 20, 1000, we are always using the same constant. Therefore, we can optimize our program by keeping the constant on the stack all the time.
Early on in our program, we are calculating the value of the above constant. We
need to divide our input by 10 for every digit in the
constant.
It is much faster to multiply than to divide. So, at the start of our program, we
divide 10 into 1 to obtain
0.1, which we then keep on the stack: Instead of dividing
the input by 10 for every digit, we multiply it by 0.1.
By the way, we do not input 0.1 directly, even
though we could. We have a reason for that: While 0.1 can
be expressed with just one decimal place, we do not know how many binary places it takes. We, therefore,
let the FPU calculate its binary value to its
own high precision.
We are using other constants: We multiply the pinhole diameter by 1000 to convert it from millimeters to microns. We compare
numbers to 10000 when we are rounding them off to four
significant digits. So, we keep both, 1000 and 10000, on the stack. And, of course, we reuse the 0.1 when rounding off numbers to four digits.
Last but not least, we keep -5 on the stack. We need
it to scale the square of the f-number, instead of dividing it by 32. It is not by coincidence we load this constant last. That
makes it the top of the stack when only the constants are on it. So, when the square of
the f-number is being scaled, the -5 is at st(1), precisely where fscale
expects it to be.
It is common to create certain constants from scratch instead of loading them from
the memory. That is what we are doing with -5:
fld1 ; TOS = 1
fadd st0, st0 ; TOS = 2
fadd st0, st0 ; TOS = 4
fld1 ; TOS = 1
faddp st1, st0 ; TOS = 5
fchs ; TOS = -5
总结一下前面的所有这些优化: 将重复的值放在堆栈上!
提示: PostScript® 也是一种面向堆栈的程序设计语言。 关于 PostScript 的书要比介绍 FPU 汇编语言的书多得多: 掌握了 PostScript 会有助于帮助您掌握 FPU。
11.13.5 pinhole──源程序
;;;;;;; pinhole.asm ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;
; 计算针孔照相机的若干参数
;
; 创建: 2001-6月-9日
; 更新: 2001-6月-10日
;
; Copyright (c) 2001 G. Adam Stanislav
; All rights reserved.
;
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
%include 'system.inc'
%define BUFSIZE 2048
section .data
align 4
ten dd 10
thousand dd 1000
tthou dd 10000
fd.in dd stdin
fd.out dd stdout
envar db 'PINHOLE=' ; Exactly 8 bytes, or 2 dwords long
pinhole db '04,', ; Bender's constant (0.04)
connors db '037', 0Ah ; Connors' constant
usg db 'Usage: pinhole [-b] [-c] [-e] [-p <value>] [-o <outfile>] [-i <infile>]', 0Ah
usglen equ $-usg
iemsg db "pinhole: Can't open input file", 0Ah
iemlen equ $-iemsg
oemsg db "pinhole: Can't create output file", 0Ah
oemlen equ $-oemsg
pinmsg db "pinhole: The PINHOLE constant must not be 0", 0Ah
pinlen equ $-pinmsg
toobig db "pinhole: The PINHOLE constant may not exceed 18 decimal places", 0Ah
biglen equ $-toobig
huhmsg db 9, '???'
separ db 9, '???'
sep2 db 9, '???'
sep3 db 9, '???'
sep4 db 9, '???', 0Ah
huhlen equ $-huhmsg
header db 'focal length in millimeters,pinhole diameter in microns,'
db 'F-number,normalized F-number,F-5.6 multiplier,stops '
db 'from F-5.6', 0Ah
headlen equ $-header
section .bss
ibuffer resb BUFSIZE
obuffer resb BUFSIZE
dbuffer resb 20 ; decimal input buffer
bbuffer resb 10 ; BCD buffer
section .text
align 4
huh:
call write
push dword huhlen
push dword huhmsg
push dword [fd.out]
sys.write
add esp, byte 12
ret
align 4
perr:
push dword pinlen
push dword pinmsg
push dword stderr
sys.write
push dword 4 ; return failure
sys.exit
align 4
consttoobig:
push dword biglen
push dword toobig
push dword stderr
sys.write
push dword 5 ; return failure
sys.exit
align 4
ierr:
push dword iemlen
push dword iemsg
push dword stderr
sys.write
push dword 1 ; return failure
sys.exit
align 4
oerr:
push dword oemlen
push dword oemsg
push dword stderr
sys.write
push dword 2
sys.exit
align 4
usage:
push dword usglen
push dword usg
push dword stderr
sys.write
push dword 3
sys.exit
align 4
global _start
_start:
add esp, byte 8 ; discard argc and argv[0]
sub esi, esi
.arg:
pop ecx
or ecx, ecx
je near .getenv ; no more arguments
; ECX contains the pointer to an argument
cmp byte [ecx], '-'
jne usage
inc ecx
mov ax, [ecx]
inc ecx
.o:
cmp al, 'o'
jne .i
; Make sure we are not asked for the output file twice
cmp dword [fd.out], stdout
jne usage
; Find the path to output file - it is either at [ECX+1],
; i.e., -ofile --
; or in the next argument,
; i.e., -o file
or ah, ah
jne .openoutput
pop ecx
jecxz usage
.openoutput:
push dword 420 ; file mode (644 octal)
push dword 0200h | 0400h | 01h
; O_CREAT | O_TRUNC | O_WRONLY
push ecx
sys.open
jc near oerr
add esp, byte 12
mov [fd.out], eax
jmp short .arg
.i:
cmp al, 'i'
jne .p
; Make sure we are not asked twice
cmp dword [fd.in], stdin
jne near usage
; Find the path to the input file
or ah, ah
jne .openinput
pop ecx
or ecx, ecx
je near usage
.openinput:
push dword 0 ; O_RDONLY
push ecx
sys.open
jc near ierr ; open failed
add esp, byte 8
mov [fd.in], eax
jmp .arg
.p:
cmp al, 'p'
jne .c
or ah, ah
jne .pcheck
pop ecx
or ecx, ecx
je near usage
mov ah, [ecx]
.pcheck:
cmp ah, '0'
jl near usage
cmp ah, '9'
ja near usage
mov esi, ecx
jmp .arg
.c:
cmp al, 'c'
jne .b
or ah, ah
jne near usage
mov esi, connors
jmp .arg
.b:
cmp al, 'b'
jne .e
or ah, ah
jne near usage
mov esi, pinhole
jmp .arg
.e:
cmp al, 'e'
jne near usage
or ah, ah
jne near usage
mov al, ','
mov [huhmsg], al
mov [separ], al
mov [sep2], al
mov [sep3], al
mov [sep4], al
jmp .arg
align 4
.getenv:
; If ESI = 0, we did not have a -p argument,
; and need to check the environment for "PINHOLE="
or esi, esi
jne .init
sub ecx, ecx
.nextenv:
pop esi
or esi, esi
je .default ; no PINHOLE envar found
; check if this envar starts with 'PINHOLE='
mov edi, envar
mov cl, 2 ; 'PINHOLE=' is 2 dwords long
rep cmpsd
jne .nextenv
; Check if it is followed by a digit
mov al, [esi]
cmp al, '0'
jl .default
cmp al, '9'
jbe .init
; fall through
align 4
.default:
; We got here because we had no -p argument,
; and did not find the PINHOLE envar.
mov esi, pinhole
; fall through
align 4
.init:
sub eax, eax
sub ebx, ebx
sub ecx, ecx
sub edx, edx
mov edi, dbuffer+1
mov byte [dbuffer], '0'
; Convert the pinhole constant to real
.constloop:
lodsb
cmp al, '9'
ja .setconst
cmp al, '0'
je .processconst
jb .setconst
inc dl
.processconst:
inc cl
cmp cl, 18
ja near consttoobig
stosb
jmp short .constloop
align 4
.setconst:
or dl, dl
je near perr
finit
fild dword [tthou]
fld1
fild dword [ten]
fdivp st1, st0
fild dword [thousand]
mov edi, obuffer
mov ebp, ecx
call bcdload
.constdiv:
fmul st0, st2
loop .constdiv
fld1
fadd st0, st0
fadd st0, st0
fld1
faddp st1, st0
fchs
; If we are creating a CSV file,
; print header
cmp byte [separ], ','
jne .bigloop
push dword headlen
push dword header
push dword [fd.out]
sys.write
.bigloop:
call getchar
jc near done
; Skip to the end of the line if you got '#'
cmp al, '#'
jne .num
call skiptoeol
jmp short .bigloop
.num:
; See if you got a number
cmp al, '0'
jl .bigloop
cmp al, '9'
ja .bigloop
; Yes, we have a number
sub ebp, ebp
sub edx, edx
.number:
cmp al, '0'
je .number0
mov dl, 1
.number0:
or dl, dl ; Skip leading 0's
je .nextnumber
push eax
call putchar
pop eax
inc ebp
cmp ebp, 19
jae .nextnumber
mov [dbuffer+ebp], al
.nextnumber:
call getchar
jc .work
cmp al, '#'
je .ungetc
cmp al, '0'
jl .work
cmp al, '9'
ja .work
jmp short .number
.ungetc:
dec esi
inc ebx
.work:
; Now, do all the work
or dl, dl
je near .work0
cmp ebp, 19
jae near .toobig
call bcdload
; Calculate pinhole diameter
fld st0 ; save it
fsqrt
fmul st0, st3
fld st0
fmul st5
sub ebp, ebp
; Round off to 4 significant digits
.diameter:
fcom st0, st7
fstsw ax
sahf
jb .printdiameter
fmul st0, st6
inc ebp
jmp short .diameter
.printdiameter:
call printnumber ; pinhole diameter
; Calculate F-number
fdivp st1, st0
fld st0
sub ebp, ebp
.fnumber:
fcom st0, st6
fstsw ax
sahf
jb .printfnumber
fmul st0, st5
inc ebp
jmp short .fnumber
.printfnumber:
call printnumber ; F number
; Calculate normalized F-number
fmul st0, st0
fld1
fld st1
fyl2x
frndint
fld1
fscale
fsqrt
fstp st1
sub ebp, ebp
call printnumber
; Calculate time multiplier from F-5.6
fscale
fld st0
; Round off to 4 significant digits
.fmul:
fcom st0, st6
fstsw ax
sahf
jb .printfmul
inc ebp
fmul st0, st5
jmp short .fmul
.printfmul:
call printnumber ; F multiplier
; Calculate F-stops from 5.6
fld1
fxch st1
fyl2x
sub ebp, ebp
call printnumber
mov al, 0Ah
call putchar
jmp .bigloop
.work0:
mov al, '0'
call putchar
align 4
.toobig:
call huh
jmp .bigloop
align 4
done:
call write ; flush output buffer
; close files
push dword [fd.in]
sys.close
push dword [fd.out]
sys.close
finit
; return success
push dword 0
sys.exit
align 4
skiptoeol:
; Keep reading until you come to cr, lf, or eof
call getchar
jc done
cmp al, 0Ah
jne .cr
ret
.cr:
cmp al, 0Dh
jne skiptoeol
ret
align 4
getchar:
or ebx, ebx
jne .fetch
call read
.fetch:
lodsb
dec ebx
clc
ret
read:
jecxz .read
call write
.read:
push dword BUFSIZE
mov esi, ibuffer
push esi
push dword [fd.in]
sys.read
add esp, byte 12
mov ebx, eax
or eax, eax
je .empty
sub eax, eax
ret
align 4
.empty:
add esp, byte 4
stc
ret
align 4
putchar:
stosb
inc ecx
cmp ecx, BUFSIZE
je write
ret
align 4
write:
jecxz .ret ; nothing to write
sub edi, ecx ; start of buffer
push ecx
push edi
push dword [fd.out]
sys.write
add esp, byte 12
sub eax, eax
sub ecx, ecx ; buffer is empty now
.ret:
ret
align 4
bcdload:
; EBP contains the number of chars in dbuffer
push ecx
push esi
push edi
lea ecx, [ebp+1]
lea esi, [dbuffer+ebp-1]
shr ecx, 1
std
mov edi, bbuffer
sub eax, eax
mov [edi], eax
mov [edi+4], eax
mov [edi+2], ax
.loop:
lodsw
sub ax, 3030h
shl al, 4
or al, ah
mov [edi], al
inc edi
loop .loop
fbld [bbuffer]
cld
pop edi
pop esi
pop ecx
sub eax, eax
ret
align 4
printnumber:
push ebp
mov al, [separ]
call putchar
; Print the integer at the TOS
mov ebp, bbuffer+9
fbstp [bbuffer]
; Check the sign
mov al, [ebp]
dec ebp
or al, al
jns .leading
; We got a negative number (should never happen)
mov al, '-'
call putchar
.leading:
; Skip leading zeros
mov al, [ebp]
dec ebp
or al, al
jne .first
cmp ebp, bbuffer
jae .leading
; We are here because the result was 0.
; Print '0' and return
mov al, '0'
jmp putchar
.first:
; We have found the first non-zero.
; But it is still packed
test al, 0F0h
jz .second
push eax
shr al, 4
add al, '0'
call putchar
pop eax
and al, 0Fh
.second:
add al, '0'
call putchar
.next:
cmp ebp, bbuffer
jb .done
mov al, [ebp]
push eax
shr al, 4
add al, '0'
call putchar
pop eax
and al, 0Fh
add al, '0'
call putchar
dec ebp
jmp short .next
.done:
pop ebp
or ebp, ebp
je .ret
.zeros:
mov al, '0'
call putchar
dec ebp
jne .zeros
.ret:
ret
这段代码在形式上与我们之前看到的其他过滤器如出一辙, 只是有一处细小的区别:
我们不再假定输入的结束是全部事情的终结, 而这是 面向字符的 过滤器中的一种基本假设。
这个过滤器并不是简单地处理字符流。 它处理的是一种 语言 (当然, 只是一种非常简单的, 只包含数字的语言)。
如果没有进一步的输入了, 这可能表示两件事之一:
已经完成了全部工作, 而程序可以结束了。 这与之前的情况类似。
我们读入的最后一个字符是一个数字。 我们将其保存在 ASCII-到-浮点数转换缓冲区中。 我们需要将那个缓冲区的内容转换为数字, 并输出所得到的最后一个结果。
基于这样的原因, 我们需要修改
getchar和read两个过程, 并在仍有字符时返回时将carry flag复位, 而在没有更多字符时, 则返回时将carry flag置位。当然, 我们需要使用一些汇编语言的小技巧来完成这项工作。 看一看
getchar。 它 总会 在返回时将carry flag复位。另外, 我们的主函数代码依赖于使用
carry flag来告诉它何时退出──就是这样。这里所采用的技巧是在
read中。 当它收到来自系统的更多输入时, 会返回到getchar, 后者会从输入缓冲中取走一个字符, 复位carry flag并返回。但是当
read没有从系统中获取到输入时, 它 并不会 返回到getchar。 与此相反, 它会使用add esp, byte 4操作将ESP加4, 并将carry flag置位 之后返回。那么, 它返回到了哪里呢? 无论什么时候, 当程序用到
call操作时, 微处理器都会push返回地址, 也就是将其放到�顶 (注意并不是 FPU �, 而是内存中的系统�)。 当程序用到ret操作时, 微处理器会从�中pop返回地址, 并跳转回保存在那里的地址。然而, 由于我们在
ESP(�指针寄存器) 上加了4, 我们实际上利用了微处理器的 健忘性: 它会忘记, 在之前是getcharcall(调用) 的read。而由于
getchar从未在callread之前push过数据, 因此�顶的内容就是call了getchar时的返回地址。 如果调用者留意的话, 他会发现call了getchar, 而ret(返回) 时, 则有设置carry flag!
除此之外, bcdload 这个过程也有一些问题, 它需要面对
Big-Endians 和 Little-Endians 之间的冲突。
在将文本转化为对应的数值时, 文本是以 big-endian 字节序保存的, 而 压缩形式的十进制数 则是 little-endian 格式。
要解决这个冲突, 我们首先使用 std。 然后, 使用
cld 来取消其作用: 确保在设了 std 时, 不调用任何可能会依赖于默认的 direction flag 设置的函数是非常重要的。
如果您完整地阅读过这一章, 那么这段代码的其余部分就比较清晰了。
这也应验了一句老话, 程序设计需要的是深思熟虑, 而真正的编码工作则微不足道。 一旦我们认真思考了每个细节, 那么代码基本上就是在顺理成章中一气呵成的了。
11.13.6 使用 pinhole
由于我们已经决定让程序 忽略 除了数字以外的任何输入 (当然在注释中的数字也会忽略), 实际的操作就简化为 文本查询。 尽管并非 必须如此, 但至少 可以 这样做。
在我看来, 构造文本查询, 而非严格遵循语法, 有助于改善软件的用户体验。
假定我们打算制作使用 4x5 英寸胶片的针孔相机。 这种胶片的标准焦距大约是 150mm。 我们希望尽可能地 微调 焦距, 使得针孔的直径尽可能接近某个数值。 除此之外, 由于对计算机的抵触情绪和对照相机的熟悉, 并不希望输入一大串数字, 而是直接 问 一些问题。
这种会话大致如此:
% pinhole Computer, What size pinhole do I need for the focal length of 150? 150 490 306 362 2930 12 Hmmm... How about 160? 160 506 316 362 3125 12 Let's make it 155, please. 155 498 311 362 3027 12 Ah, let's try 157... 157 501 313 362 3066 12 156? 156 500 312 362 3047 12 That's it! Perfect! Thank you very much! ^D
我们注意到, 尽管焦距是 150, 针孔的直径却应该是 490 微米, 或 0.49 mm; 而如果希望得到与之接近的 156 mm 的焦距, 则针孔的直径则应是恰好半毫米。
11.13.7 使用脚本
由于选择了使用 # 标示注释的开始, 因此可以把我们的
pinhole 软件作为一种 脚本语言 来使用。
您可能看过 shell 脚本 的开头是类似这样的形式:
#! /bin/sh
...或者...
#!/bin/sh
...因为在 #! 后面的空格是可选的。
当在 UNIX 中执行以 #!
开头的文件时, 它会假定这个文件是脚本。 此时, 脚本会把脚本头一行和命令拼起来,
并尝试执行它。
假设现在已经把 pinhole 安装到了 /usr/local/bin/, 就可以撰写用于计算用于 120 胶卷在不同焦距时所应使用的光圈大小了。
这样的脚本格式类似下面这样:
#! /usr/local/bin/pinhole -b -i # Find the best pinhole diameter # for the 120 film ### Standard 80 ### Wide angle 30, 40, 50, 60, 70 ### Telephoto 100, 120, 140
由于 120 是一种中型尺寸的胶卷, 我们把这个文件命名为 medium。
接下来赋予这个文件可执行权限, 并作为程序运行:
% chmod 755 medium % ./medium
UNIX 将把前述命令解释为:
% /usr/local/bin/pinhole -b -i ./medium
这个命令的输出结果将是:
80 358 224 256 1562 11 30 219 137 128 586 9 40 253 158 181 781 10 50 283 177 181 977 10 60 310 194 181 1172 10 70 335 209 181 1367 10 100 400 250 256 1953 11 120 438 274 256 2344 11 140 473 296 256 2734 11
现在, 输入:
% ./medium -c
UNIX 会将前述命令作为:
% /usr/local/bin/pinhole -b -i ./medium -c
来执行。 这里有两个互相冲突的选项: -b 和 -c (分别表示采用 Bender 常数和 Connors 常数)。
我们在设计程序时, 假定后出现的选项优先生效 ── 这样一来, 程序将使用 Connors
常数来完成计算:
80 331 242 256 1826 11 30 203 148 128 685 9 40 234 171 181 913 10 50 262 191 181 1141 10 60 287 209 181 1370 10 70 310 226 256 1598 11 100 370 270 256 2283 11 120 405 296 256 2739 11 140 438 320 362 3196 12
最后我们决定使用 Bender 常数, 并将这些数值, 以使用逗号分隔的文本文件来保存:
% ./medium -b -e > bender % cat bender focal length in millimeters,pinhole diameter in microns,F-number,normalized F-number,F-5.6 multiplier,stops from F-5.6 80,358,224,256,1562,11 30,219,137,128,586,9 40,253,158,181,781,10 50,283,177,181,977,10 60,310,194,181,1172,10 70,335,209,181,1367,10 100,400,250,256,1953,11 120,438,274,256,2344,11 140,473,296,256,2734,11 %
11.14 忠告
从 MS-DOS 和 Windows “成长” 起来的汇编程序员, 通常倾向于走捷径。 读键盘扫描码和直接写屏, 在 MS-DOS 上就属于很多人毫不犹豫地采用, 并自认为正确的一种做法。
原因嘛? PC BIOS 和 MS-DOS 在执行这些操作时实在是太慢了。
在 UNIX 环境下继续照此行事也许是相当有诱惑力的做法, 我还见过一个网站专门介绍如何在常见的类 UNIX 系统上访问键盘扫描码。
一般来说, 在 UNIX 环境下这是一个 糟糕透顶的主意! 下面来解释一下为什么。
11.14.1 UNIX 是受保护的
首先, 简而言之这是不可行的。 UNIX 是在保护模式下运行的。 只有内核和设备驱动才允许直接访问硬件。 也许某些设计不良的类 UNIX 系统会让您读取键盘扫描码, 但是通常真正的 UNIX 操作系统都不允许这样做。 而且, 即便某个版本允许您这么做, 也许下个版本就不行了, 因此您精心雕琢的软件, 很可能会沦为昨日黄花。
11.14.2 UNIX 是一种抽象
即使在允许您这样做的类 UNIX 系统上, 也不去尝试直接操作硬件的一个更重要原因 (当然, 除非您正在撰写设备驱动) 是:
UNIX 是一种抽象!
MS-DOS 和 UNIX 的设计哲学有一个截然相反的地方。 MS-DOS 是为单用户系统设计的, 它只在那些键盘和显示屏幕都直接插在主机上的计算机上运行, 来自用户的输入, 基本上一定来自于那个键盘, 而您程序的输出, 最终也一定会反映到那个显示器上。
在 UNIX 中从未提供这样的保证。 使用管道来重定向输入和输出这样的事情在 UNIX 用户看来是极为稀松平常的事情:
% program1 | program2 | program3 > file1
如果您撰写了 program2, 则输入并非来自键盘, 而是来自 program1 的输出。 类似地, 您的输出并不会显示到屏幕上, 而是成为 program3 的输入, 而后者的输出, 则相应地会存入 file1。
且慢! 即使您能确保输入输出都来自真正的终端, 也没有任何人能保证那终端一定是 PC: 在您预期的位置可能并不是显存, 其键盘也未必会产生 PC-风格的扫描码。 它可能是一台 Macintosh, 或者其他种类的计算机。
现在您也许会摇头: 我的软件是用 PC 汇编语言写成的, 它如何能在 Macintosh 上运行? 请注意, 我并不是说它要在 Macintosh 上运行, 而只是说终端可能是一台 Macintosh。
在 UNIX 中, 终端未必会直接连在运行您软件的计算机上, 它甚至可能在另一个大洲, 甚至在另一个星球上。 很有可能某位澳洲的 Macintosh 用户会通过 telnet 连到在北美 (或其他地方) 的 UNIX 系统上。 这样, 软件是在一台计算机上运行的, 而终端则在另一台计算机上: 如果您试图读取扫描码, 就会得到不正确的输入!
同样的问题也适用于任何其他硬件: 您正读取的文件, 可能位于您无权直接访问的磁盘上。 提取图像的一部照相机, 也许正在某个透过卫星连接的航天飞机上。
这就是为什么在 UNIX 下您不应对数据的来源和去向有任何心存侥幸的假定。 任何时候都应让系统来处理对硬件的物理访问。
注意: 这些只是忠告, 而不是绝对的规则。 有时会有一些例外的情况。 例如, 如果文本编辑器检测到它正在本地机器上运行, 就可能希望直接读取扫描码来改善控制。 这些忠告并非要告诉您该做什么和不该做什么, 只是提醒您在刚刚从 MS-DOS 迁移到 UNIX 时可能碰到的一些问题。 当然, 富于创意的人们通常会打破规则, 如果他们知道打破的是什么规则, 以及为什么要这样做的话, 一般也不会产生太严重的后果。
11.15 致谢
如果没有参与 FreeBSD 技术讨论邮件列表 邮件列表活动的众多富有经验的程序员的帮助, 如果没有那些不厌起烦得回答我问题的人,如果没有那些带领我探索 UNIX 特别是 FreeBSD 系统编程的人们的帮助,这个手册将不可能存在。
Thomas M. Sommers 领我入门,他的 如何在 FreeBSD 上用汇编语言编写 "Hello, world"? 的网页, 是我遇见的第一个关于在 FreeBSD 上编写汇编程序的实例。
Jake Burkholder 乐于助人,回答我的问题,提供给我汇编的代码, 在他的帮助下我不断前进。
Copyright © 2000-2001 G. Adam Stanislav. All rights reserved.
第V部分. 附录
- 目录
- 参考书目
参考书目
[1] Dave A Patterson 和 John L Hennessy, 1998, 1-55860-428-6, Morgan Kaufmann Publishers, Inc., Computer Organization and Design: The Hardware / Software Interface, 1-2.
[2] W. Richard Stevens, 1993, 0-201-56317-7, Addison Wesley Longman, Inc., Advanced Programming in the Unix Environment, 1-2.
[4] Marshall Kirk McKusick 和 George Neville-Neil, 2004, 0-201-70245-2, Addison-Wesley, The Design and Implementation of the FreeBSD Operating System, 1-2.
索引
B
- bounds checking(边界检查)
-
- compiler-based(基于编译器的), 基于编译器运行时边界检查
- library-based(基于库的), 基于库运行时边界检查
- buffer overflow, 基于编译器运行时边界检查
- buffer overflow(缓冲区溢出), 缓冲区溢出
P
- Perl, Perl 和 Python
- Perl Taint模式, 信任
- port 维护者, Makefile 中的 MAINTAINER
- positive filtering(积极过滤), 信任
- POSIX.1e 处理能力, POSIX.1e 处理能力
- process image(进程映象)
- ProPolice, 基于编译器运行时边界检查
- Python, Perl 和 Python
R
- race conditions(竞态条件)
- release engineering (正式发行工程师), 妨碍性的 (Encumbered) 文件
- return address(返回地址), 缓冲区溢出