第九章 关联数组/哈希表
一、数组变量的限制1 : #!/usr/local/bin/perl运行结果如下:
2 :
3 : while ($inputline = <STDIN>) {
4 : while ($inputline =~ /\b[A-Z]\S+/g) {
5 : $word = $&;
6 : $word =~ s/[;.,:-]$//; # remove punctuation
7 : for ($count = 1; $count <= @wordlist;
8 : $count++) {
9 : $found = 0;
10: if ($wordlist[$count-1] eq $word) {
11: $found = 1;
12: $wordcount[$count-1] += 1;
13: last;
14: }
15: }
16: if ($found == 0) {
17: $oldlength = @wordlist;
18: $wordlist[$oldlength] = $word;
19: $wordcount[$oldlength] = 1;
20: }
21: }
22: }
23: print ("Capitalized words and number of occurrences:\n");
24: for ($count = 1; $count <= @wordlist; $count++) {
25: print ("$wordlist[$count-1]: $wordcount[$count-1]\n");
26: }
Here is a line of Input.这个程序每次从标准输入文件读一行文字,第四行起的循环匹配每行中首字母大写的单词,每找到一个循环一次,赋给简单变量$word。在第六行中去掉标点后,查看该单词是否曾出现过,7~15行中在@wordlist中挨个元素做此检查,如果某个元素与$word相等,@wordcount中相应的元素就增加一个数。如果没有出现过,即@wordlist中没有元素与$word相等,16~20行给@wordlist和@wordcount增加一个新元素。
This Input contains some Capitalized words.
^D
Capitalized words and number of occurrences:
Here: 1
Input: 2
This: 1
Capitalized: 1
$fruit{"bananas"}简单变量也可作为下标,如:
$number{3.14159}
$integer{-7}
1 : #!/usr/local/bin/perl运行结果如下:
2 :
3 : while ($inputline =) {
4 : while ($inputline =~ /\b[A-Z]\S+/g) {
5 : $word = $&;
6 : $word =~ s/[;.,:-]$//; # remove punctuation
7 : $wordlist{$word} += 1;
8 : }
9 : }
10: print ("Capitalized words and number of occurrences:\n");
11: foreach $capword (keys(%wordlist)) {
12: print ("$capword: $wordlist{$capword}\n");
13: }
Here is a line of Input.你可以看到,这次程序简单多了,读取输入并存贮各单词数目从20行减少到了7行。
This Input contains some Capitalized words.
^D
Capitalized words and number of occurrences:
This: 1
Input: 2
Here: 1
Capitalized: 1
foreach $capword (sort keys(%wordlist)) {五、创建关联数组
print ("$capword: $wordlist{$capword}\n");
}
注:用列表给关联数组赋值时,Perl5允许使用"=>"或","来分隔下标与值,用"=>"可读性更好些,上面语句等效于:下标为apples的元素,值为17 下标为bananas的元素,值为9 下标为oranges的元素,值为none
1: #!/usr/local/bin/perl运行结果如下:
2:
3: $inputline = <STDIN>;
4: $inputline =~ s/^\s+|\s+\n$//g;
5: %fruit = split(/\s+/, $inputline);
6: print ("Number of bananas: $fruit{\"bananas\"}\n");
oranges 5 apples 7 bananas 11 cherries 6七、元素的增删
Number of bananas: 11
1、一定要使用delete函数来删除关联数组的元素,这是唯一的方法。八、列出数组的索引和值
2、一定不要对关联数组使用内嵌函数push、pop、shift及splice,因为其元素位置是随机的。
%fruit = ("apples", 9,
"bananas", 23,
"cherries", 11);
@fruitsubs = keys(%fruits);
%fruit = ("apples", 9,
"bananas", 23,
"cherries", 11);
@fruitvalues = values(%fruits);
foreach $holder (keys(%records)){Perl提供一种更有效的循环方式,使用内嵌函数each(),如:
$record = $records{$holder};
}
%records = ("Maris", 61, "Aaron", 755, "Young", 511);each()函数每次返回一个双元素的列表,其第一个元素为下标,第二个元素为相应的值,最后返回一个空列表。
while (($holder, $record) = each(%records)) {
# stuff goes here
}
%words = ("abel", "baker",
"baker", "charlie",
"charlie", "delta",
"delta", "");
$header = "abel";
1 : #!/usr/local/bin/perl运行结果如下:
2 :
3 : # initialize list to empty
4 : $header = "";
5 : while ($line = <STDIN>) {
6 : # remove leading and trailing spaces
7 : $line =~ s/^\s+|\s+$//g;
8 : @words = split(/\s+/, $line);
9 : foreach $word (@words) {
10: # remove closing punctuation, if any
11: $word =~ s/[.,;:-]$//;
12: # convert all words to lower case
13: $word =~ tr/A-Z/a-z/;
14: &add_word_to_list($word);
15: }
16: }
17: &print_list;
18:
19: sub add_word_to_list {
20: local($word) = @_;
21: local($pointer);
22:
23: # if list is empty, add first item
24: if ($header eq "") {
25: $header = $word;
26: $wordlist{$word} = "";
27: return;
28: }
29: # if word identical to first element in list,
30: # do nothing
31: return if ($header eq $word);
32: # see whether word should be the new
33: # first word in the list
34: if ($header gt $word) {
35: $wordlist{$word} = $header;
36: $header = $word;
37: return;
38: }
39: # find place where word belongs
40: $pointer = $header;
41: while ($wordlist{$pointer} ne "" &&
42: $wordlist{$pointer} lt $word) {
43: $pointer = $wordlist{$pointer};
44: }
45: # if word already seen, do nothing
46: return if ($word eq $wordlist{$pointer});
47: $wordlist{$word} = $wordlist{$pointer};
48: $wordlist{$pointer} = $word;
49: }
50:
51: sub print_list {
52: local ($pointer);
53: print ("Words in this file:\n");
54: $pointer = $header;
55: while ($pointer ne "") {
56: print ("$pointer\n");
57: $pointer = $wordlist{$pointer};
58: }
59: }
Here are some words.此程序分为三个部分:
Here are more words.
Here are still more words.
^D
Words in this file:
are
here
more
some
still
words
第3~17行为主程序,第4行初始化链表,将表头变量$header设为空串,第5行起的循环每次读取一行输入,第7行去掉头、尾的空格,第8行将句子分割成单词。9~15行的内循环每次处理一个单词,如果该单词的最后一个字符是标点符号,就去掉。第13行把单词转换成全小写形式,第14行传递给子程序add_word_to_list。主程序:读取输入并转换到相应的格式。 子程序:add_word_to_list,建立排序单词链表。 子程序:print_list,输出单词链表
foreach $word (sort keys(%wordlist)) {但是,这里涉及的指针的概念在其它数据结构中很有意义。
# print the sorted list, or whatever }
struce{我们要做的是定义一个含有三个元素的关联数组,下标分别为field1、field2、field3,如:
int field1;
int field2;
int field3; }mystructvar;
%mystructvar = ("field1" , "" ,像上面C语言的定义一样,这个关联数组%mystrctvar有三个元素,下标分别为field1、field2、field3,各元素初始值均为空串。对各元素的访问和赋值通过指定下标来进行,如:
"field2" , "" ,
"field3" , "" ,);
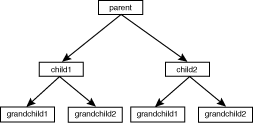
有多种使用关联数组实现树结构的方法,最好的一种应该是:给子节点分别加上left和right以访问之。例如,alphaleft和alpharight指向alpha的左右子节点。下面是用此方法创建二叉树并遍历的例程:因为每个子节点均为一个树,所以左/右子节点也称为左/右子树。(有时称左/右分支) 第一个节点(不是任何节点的子节点的节点)称为树的根。 没有孩子(子节点)的节点称为叶节点。
1 : #!/usr/local/bin/perl结果输出如下:
2 :
3 : $rootname = "parent";
4 : %tree = ("parentleft", "child1",
5 : "parentright", "child2",
6 : "child1left", "grandchild1",
7 : "child1right", "grandchild2",
8 : "child2left", "grandchild3",
9 : "child2right", "grandchild4");
10: # traverse tree, printing its elements
11: &print_tree($rootname);
12:
13: sub print_tree {
14: local ($nodename) = @_;
15: local ($leftchildname, $rightchildname);
16:
17: $leftchildname = $nodename . "left";
18: $rightchildname = $nodename . "right";
19: if ($tree{$leftchildname} ne "") {
20: &print_tree($tree{$leftchildname});
21: }
22: print ("$nodename\n");
23: if ($tree{$rightchildname} ne "") {
24: &print_tree($tree{$rightchildname});
25: }
26: }
grandchild1该程序创建的二叉树如下图:
child1
grandchild2
parent
grandchild3
child2
grandchild4