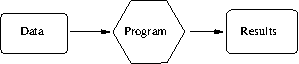
Figure D.1: General Program Flow
Next: Basic Data Typing, Up: Basic Concepts [Contents][Index]
At the most basic level, the job of a program is to process some input data and produce results. See Figure D.1.
The “program” in the figure can be either a compiled
program119
(such as ls),
or it may be interpreted. In the latter case, a machine-executable
program such as awk reads your program, and then uses the
instructions in your program to process the data.
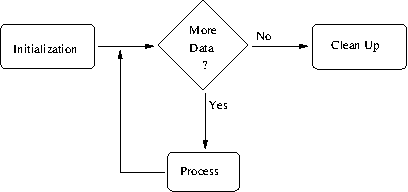
When you write a program, it usually consists of the following, very basic set of steps, as shown in Figure D.2:
These are the things you do before actually starting to process
data, such as checking arguments, initializing any data you need
to work with, and so on.
This step corresponds to awk’s BEGIN rule
(see BEGIN/END).
If you were baking a cake, this might consist of laying out all the mixing bowls and the baking pan, and making sure you have all the ingredients that you need.
This is where the actual work is done. Your program reads data, one logical chunk at a time, and processes it as appropriate.
In most programming languages, you have to manually manage the reading
of data, checking to see if there is more each time you read a chunk.
awk’s pattern-action paradigm
(see Getting Started)
handles the mechanics of this for you.
In baking a cake, the processing corresponds to the actual labor: breaking eggs, mixing the flour, water, and other ingredients, and then putting the cake into the oven.
Once you’ve processed all the data, you may have things you need to
do before exiting.
This step corresponds to awk’s END rule
(see BEGIN/END).
After the cake comes out of the oven, you still have to wrap it in plastic wrap to keep anyone from tasting it, as well as wash the mixing bowls and utensils.
An algorithm is a detailed set of instructions necessary to accomplish a task, or process data. It is much the same as a recipe for baking a cake. Programs implement algorithms. Often, it is up to you to design the algorithm and implement it, simultaneously.
The “logical chunks” we talked about previously are called records, similar to the records a company keeps on employees, a school keeps for students, or a doctor keeps for patients. Each record has many component parts, such as first and last names, date of birth, address, and so on. The component parts are referred to as the fields of the record.
The act of reading data is termed input, and that of generating results, not too surprisingly, is termed output. They are often referred to together as “input/output,” and even more often, as “I/O” for short. (You will also see “input” and “output” used as verbs.)
awk manages the reading of data for you, as well as the
breaking it up into records and fields. Your program’s job is to
tell awk what to do with the data. You do this by describing
patterns in the data to look for, and actions to execute
when those patterns are seen. This data-driven nature of
awk programs usually makes them both easier to write
and easier to read.
Compiled programs are typically written in lower-level languages such as C, C++, or Ada, and then translated, or compiled, into a form that the computer can execute directly.
Next: Basic Data Typing, Up: Basic Concepts [Contents][Index]